AWS Big Data Blog
The Impact of Using Latest-Generation Instances for Your Amazon EMR Job
Nick Corbett is a Big Data Consultant for AWS Professional Services
Amazon Elastic MapReduce (Amazon EMR) is a web service that makes it easy to process large amounts of data efficiently. Amazon EMR uses the popular open source framework Apache Hadoop combined with several other AWS products to do such tasks as web indexing, data mining, log file analysis, machine learning, scientific simulation and data warehousing.
Traditionally, Hadoop has used a distributed processing engine called MapReduce to divide large jobs into small tasks. These are spread out over a fleet of servers and executed in parallel. This scales well, even when the input data is in the order of petabytes. However, MapReduce is not the only choice; open source products such as Impala, Apache Spark, or Presto can all be run on Amazon EMR and offer alternative frameworks for processing large amounts of data.
Whatever your framework choice, when you run an Amazon EMR cluster you need to choose the instance type that’s used for your cluster’s nodes. An overview of all the instance types is provided in the Amazon EMR documentation. The table below lists specifications of instance types discussed in this post.
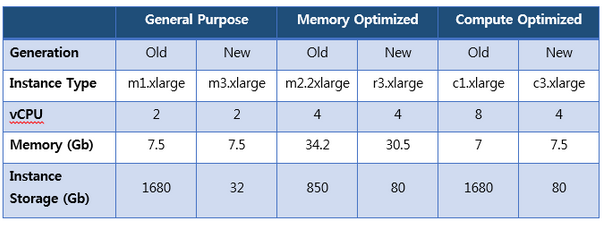
As the AWS platform evolves, new generations of instances replace old. For example, the m3 family of general-purpose instances are offered as a newer alternative to the m1 family. As you might expect, each new generation is more powerful than the last, but translating this into a benefit for your Amazon EMR cluster is not always straightforward. This post looks at the practical differences between instance generations and helps you to make the best choice for your cluster.
The first step to successfully building any Amazon EMR cluster is to understand the workloads you want to run. Are they bound by CPU, do they require lots of memory, or is there a requirement for storage? Understanding how your Amazon EMR job behaves lets you choose the best instance type.
Compute-Intensive Workloads
To simulate a job that is bound by CPU, a simple MapReduce algorithm that uses a Monte Carlo technique to estimate Pi was developed. This was compute heavy; it has little requirement for memory and the flow of data between mappers and reducers is minimal.
It isn’t always obvious if your job is compute, memory or disk intensive. Fortunately, it’s easy to use the open source monitoring tool Ganglia to investigate your Amazon EMR workloads. When you start an Amazon EMR cluster, follow the Amazon EMR instructions for adding Ganglia as a bootstrap action (this page also includes instructions that show you how to connect to Ganglia once your cluster is running).
A simple Amazon EMR Cluster containing 3 nodes (1 master and 2 core) was started. All nodes were the old generation m1.xlarge instance type. The Monte Carlo MapReduce job was run and the following graphs show CPU usage across the cluster:

The two graphs on the left show the CPUs from the core nodes were at 100% for the time the job was monitored. The master node, on the right, is less busy. That is to be expected as it does not execute map or reduce tasks. The network, memory and disk usage on this cluster was minimal.
Having established that the Monte Carlo job is CPU bound, we can predict that it will run best on the latest generation of compute-optimized instances. To test this prediction, we look at the impact of moving the job to a range of new generation instances:
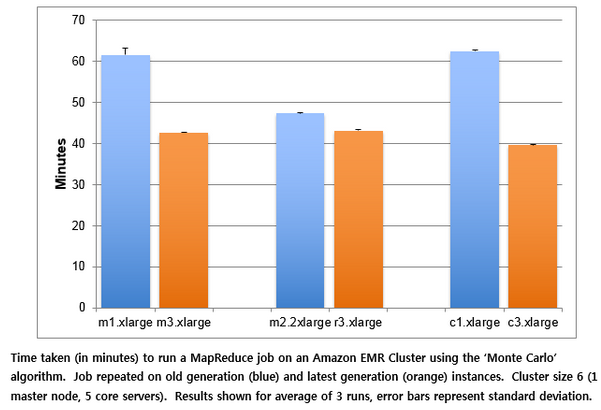
On paper the m1.xlarge and m3.xlarge look similar (both have 2 vCPUs and 7.5Gb memory). However, the m3 instances completed the job 30% faster than equivalent m1 instances. New generation memory-optimized (r3) instances were 9% faster than the previous and a 37% improvement was seen when the workload was moved from old (c1) to new (c3) generation compute-optimized instances.
Running your Amazon EMR workload on optimal instances can save you money as well as time. This financial saving is two-fold. First, the latest generation instances are cheaper than the old. For example, a c3.xlarge instance in an Amazon EMR cluster in the US East region costs $0.263 an hour whereas an old generation c1.xlarge costs $0.640. A cluster made of c3.xlarge instances will therefore be 59% cheaper to run every hour than one of the same size made of c1.xlarge instances.
If you choose to run a transient cluster and switch off instances after a job has completed you may also see a saving if your job takes less time to complete. Amazon EMR jobs are billed by the number instance hours you use. If your job completes in less instance hours, it will be cheaper. For example, the Monte Carlo job used 12 instance hours when run on c1.xlarge cluster (6 nodes for 62 minutes) but only 6 instance hours on when c3.xlarge instances were used (6 nodes for 39 minutes). Combined with the cheaper rates, this reduction in instance hours resulted in an overall saving of 79% when the job was moved to the new generation of instances.
Memory-Bound Workloads
An Apache Spark job was created to replicate the common Amazon EMR use case of running an Extract Transform and Load (ETL) job. This processed the Google Books Ngrams public data set. It took the raw data and filtered the data set to ngrams that contained a keyword. It then aggregated the count of the each filtered item for each decade. Finally, the list of counts was sorted and the top 50 entries extracted.
An Amazon EMR cluster containing 6 nodes (1 master and 5 core) was started using m2.2xlarge instances. The source data was loaded into HDFS and the Spark ETL job run. Once again, Ganglia was used to monitor the cluster. The overall state of the cluster over a 10 minute period is shown below:
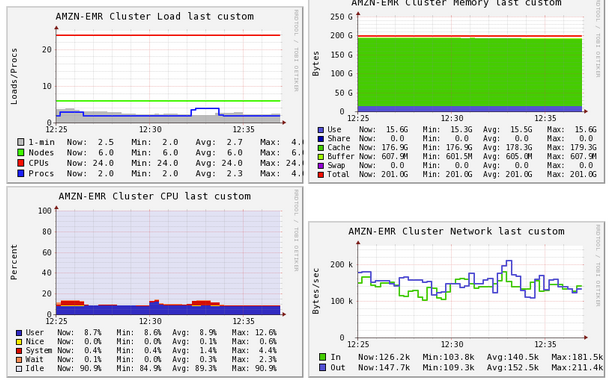
Use of network (bottom right) and CPU (bottom left) are fairly light. What stands out is the high use of memory (top right). This is expected when running a Spark job because this framework will attempt to process as much in memory as possible. Since this job is memory-bound, it makes most sense to move it to the latest generation memory-optimized instances. These instances are optimized for the amount of memory, not for speed. To really leverage the benefits of a memory-optimized server, you need to use a framework that preferentially uses memory over disk such as Spark. The increased memory means you will spend less time spilling to disk and will see improved results.
The graph below compares the Spark job run on the old generation m2 instances against the latest generation r3 family:

The absolute time that an ETL job takes obviously depends on factors such as the size of the input file, its complexity and the number of instances in the cluster. However, for this test the Spark job ran 22% faster on the latest generation instances.
This job was also cheaper to run when migrated to new generation instances. The price per instance dropped from $0.613 per hour to $0.44 and the instance hours went from 12 to 6. This represented a 64% saving on the cost of running the job.
Its important to note that not all jobs will see a price reduction of this size. For example, if a slightly larger input file is used, the job might now take 12 instance hours to complete on the new generation instances as well as the old. In this case, there is still a saving of 28% due to the cheaper price per instance. However, as soon as the job took longer than 60 minutes it cost another instance hour for each member of the cluster. If you find yourself in a similar situation, consider adding more instances to your cluster to see if you can finish the job slightly quicker. Paying for 1 or 2 extra instances for the duration of the job might be cheaper than paying for the whole cluster for an extra hour. This is where the benefits of cloud can change the underlying economics of running data analytics.
Storage
One area in which the old generation instances are better than the current is the amount of instance storage. For example, an r3.xlarge comes with 80GB of SSD local storage, but an m2.2xlarge has 850GB, although these are magnetic disks. For customers who need to process large amounts of data, staying with old generation instances might seem the logical choice: fewer instances are needed to store the same amount in HDFS, making the cluster cheaper to run.
However, Amazon S3 provides a very viable alternative here instead of HDFS for use with newer generation instances. It seems to be a common assumption that you get better performance when data is local to the cluster vs being remote in Amazon S3. We tested this hypothesis by once again running the Spark ETL job along with moving the job to new generation instances and using Amazon S3 instead of HDFS:

The first two columns on the above graph show that an m2.2xlarge cluster completed the Spark ETL job about 9% faster when data was in HDFS compared to Amazon S3. However, the quickest result was seen when a combination of Amazon S3 and r3.xlarge instances were used. The new generation instances using Amazon S3 were 15% faster than old generation using HDFS. If you are running old generation instances and storing data in HDFS you may want to consider this alternative architecture.
There are many other advantages to storing data in Amazon S3 including a high durability (11 9s), low storage costs, server-side encryption and with the introduction of EMRFS, read-after-write consistency and list consistency.
A further advantage of using Amazon S3 that some customers choose to leverage is the ability to run transient clusters. This allows you to decide what instances to use in your cluster when you start a job.
Transient clusters are cost effective if your total number of Amazon EMR processing hours (both data processing time and time to setup the cluster) is less than 24 hours per day. For more details, see the Amazon EMR Best Practices Guide. However, Amazon EMR also allows you to run persistent, long running clusters.
Summary
In this post we have looked at the advantages that using the latest generation instances can have on your Amazon EMR environment. To migrate your cluster successfully, you need to understand how your workload behaves. For example, does it demand lots of memory, is it process intensive or does it demand lots of storage? Using monitoring tools such as Ganglia can help provide insight into these characteristics. Once you understand your job, you can select the best new-generation instance and migrate your cluster. Don’t forget that AWS lets you quickly iterate, allowing you to optimize your cluster so that it performs well for a low cost.
If you have questions or suggestions, please leave a comment below.
—————————————————————
Love to work on open source? Check out EMR’s careers page.
—————————————————————-