AWS Compute Blog
Controlling concurrency in distributed systems using AWS Step Functions
This post is written by Justin Callison, Senior Manager, AWS Step Functions.
Distributed systems allow you to evolve components of your application independently and scale your application more easily. They can combine existing services together to make your application more powerful. Your development teams can develop their components more independently than in a monolithic application and avoid contention as the application grows. When your workload increases, you can add computing capacity to scale with your business. Cloud applications are inherently distributed systems.
Managing concurrency in distributed systems can be challenging. In a monolithic application, you use familiar concepts such as in-memory locks to avoid overloading a database or prevent overwriting a customer record by two users at the same time. With a distributed system, where your application is dispersed across computing environments without shared memory, these methods are no longer available to you.
In this blog, you use AWS Step Functions to control concurrency in your distributed system. This helps you avoid overloading limited resources in your serverless data processing pipeline or reduce availability risk by controlling velocity in your IT automation workflows.
Deploying the concurrency control application
With this sample application, you implement a distributed semaphore using AWS Step Functions and Amazon DynamoDB to control concurrent invocations of a function in AWS Lambda.
The sample application is built using the AWS Serverless Application Model (AWS SAM) and the Python programming language. Use the following commands to deploy this application to your AWS account:
git clone https://github.com/aws-samples/aws-stepfunctions-examples.git
cd aws-stepfunctions-examples/sam/app-control-concurrency-with-dynamodb
sam build
sam deploy --guided --profile <profile_name> --region <region code>

The sample application includes the following:
- LambdaDoWorkFunction is the Lambda function that represents units of work for which you want to control concurrency.
- CC-ConcurrencyControlledStateMachine is the state machine that implements the semaphore with a limit of 5.
- CC-locktable is the DynamoDB used to store lock information
- CC-CleanFromIncomplete is the state machine that cleans up if there are failures.
- CC-Test-Run100Executions is the state machine used to demonstrate the concurrency control.
Running the concurrency control application
- Go to Step Functions in the AWS Management Console and navigate to the CC-Test-Run100Executions state machine.
- Choose Start Execution, keep the default values for Name and Input, and choose Start execution.

- Navigate to the CC-ConcurrencyControlledStateMachine to see a list of Running executions.

- Choose one of the Running executions. The Acquire Lock state is In Progress.

- After some time, you see the state machine progress to the Run Lambda Function With Controlled Concurrency task.

- After 15 seconds, this progresses to completion.
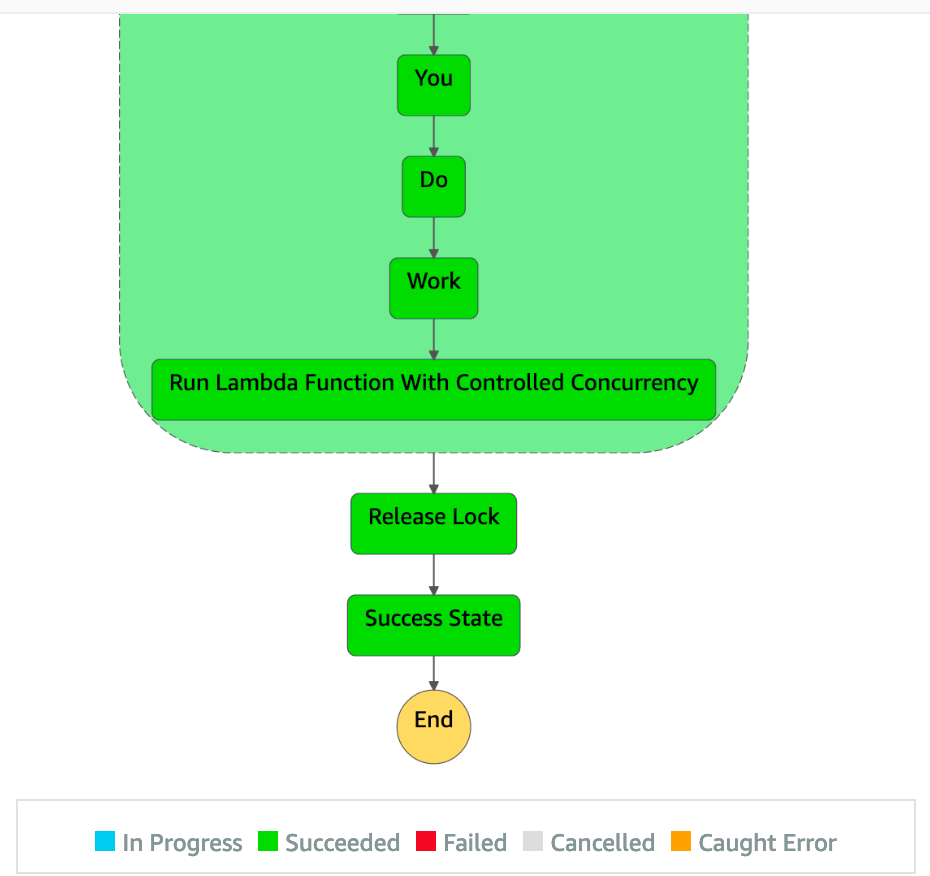
- After approximately 5 minutes, all 100 executions complete. Navigate to the LambdaDoWorkFunction in the console and choose Monitoring.
- In the Concurrent executions graph, you see the number of concurrent executions of this function did not exceed the specified limit of 5.





There are many practical examples of where you can apply this pattern:
- You have a serverless data processing pipeline that updates a relational database that can only handle a fixed level of concurrency.
- You have an IT automation workflow that orchestrates updates to a fleet of hosts where you want to limit the number that are taken out of service at one time.
- You have an MLOps pipeline where you want to provide fairness for teams accessing shared model training resources.
How it works
This section explains how the concurrency control works in more detail.
The application uses Conditional Writes to store and manage the state of the semaphore in DynamoDB. The Acquire Lock task uses the DynamoDB service integration to update the record, which stores lock information, and to atomically increment the currentlockcount attribute by 1. It also adds a new attribute with a key equal to the current execution ID and a value of the time that this state executes.
"ExpressionAttributeNames": {
"#currentlockcount": "currentlockcount",
"#lockownerid.$": "$$.Execution.Id"
},
"ExpressionAttributeValues": {
":increase": {
"N": "1"
},
":limit": {
"N": "5"
},
":lockacquiredtime": {
"S.$": "$$.State.EnteredTime"
}
},
"UpdateExpression": "SET #currentlockcount = #currentlockcount + :increase, #lockownerid = :lockacquiredtime
With a single lock held, the record in DynamoDB looks like this:
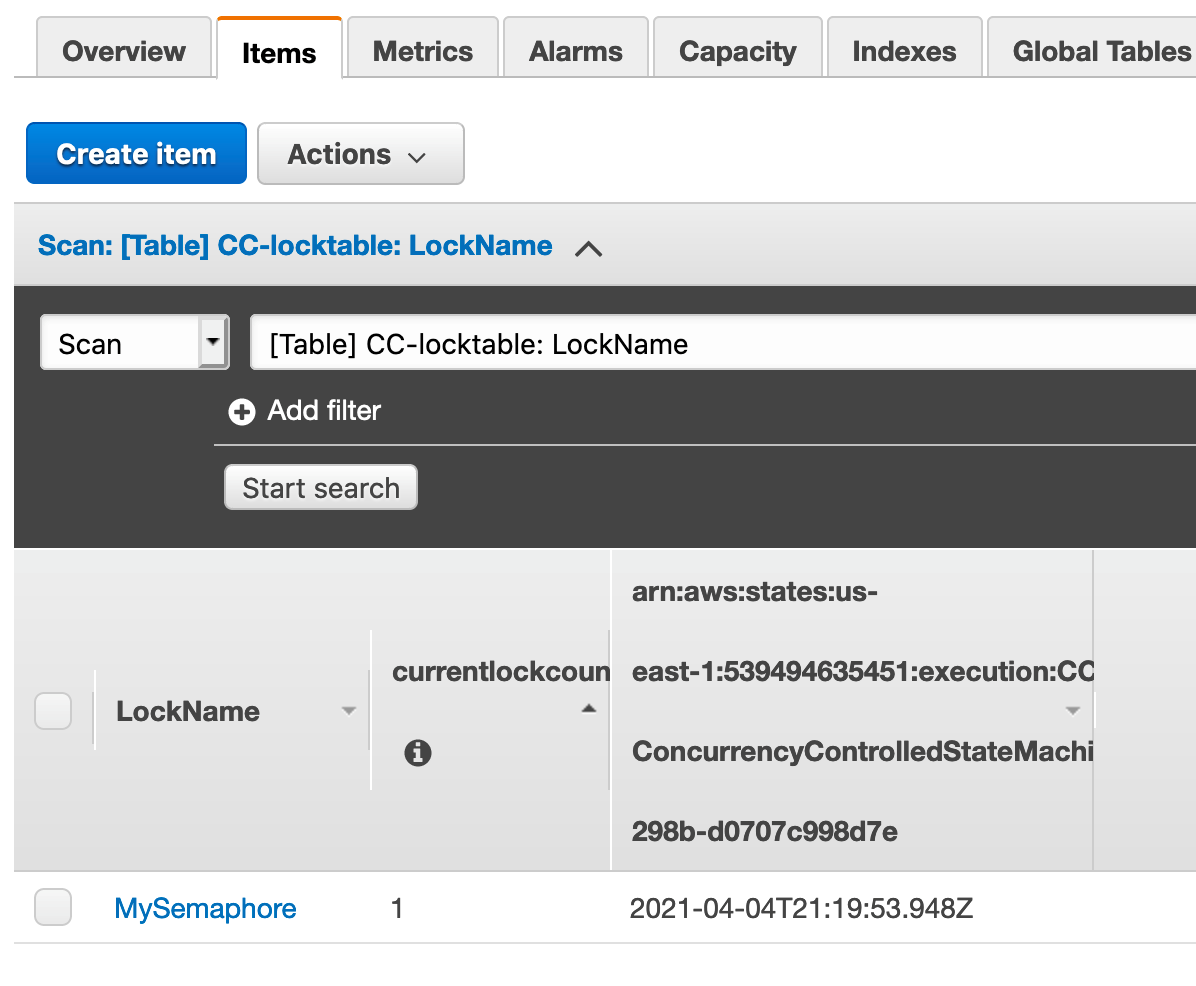
The Acquire Lock task also contains the following Conditional Expression. It causes the update to fail if the maximum number of locks are already acquired or if an attribute named for this execution already exists. The latter check is required to ensure idempotency of lock acquisition. Without this check, a network error issued after the update but before the response is received would cause a lock to leak.
"ConditionExpression": "currentlockcount <> :limit and attribute_not_exists(#lockownerid)"
If this condition is not met, DynamoDB returns a DynamoDB.ConditionalCheckFailedException and the state machine retries, at the task level and in an outer loop of logic, until it acquires a lock.
"Retry": [
{
"ErrorEquals": [
"DynamoDB.AmazonDynamoDBException"
],
"MaxAttempts": 0
},
{
"ErrorEquals": [
"States.ALL"
],
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"DynamoDB.AmazonDynamoDBException"
],
"Next": "Initialize Lock Item",
"ResultPath": "$.lockinfo.acquisitionerror"
},
{
"ErrorEquals": [
"DynamoDB.ConditionalCheckFailedException"
],
"Next": "Get Current Lock Record",
"ResultPath": "$.lockinfo.acquisitionerror"
}
]
Once business logic of the state machine completes, the Release Lock task decrements the counter and removes the execution attribute.
"Release Lock": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:updateItem",
"Parameters": {
"TableName": "CC-locktable",
"Key": {
"LockName": {
"S": "MySemaphore"
}
},
"ExpressionAttributeNames": {
"#currentlockcount": "currentlockcount",
"#lockownerid.$": "$$.Execution.Id"
},
"ExpressionAttributeValues": {
":decrease": {
"N": "1"
}
},
"UpdateExpression": "SET #currentlockcount = #currentlockcount - :decrease REMOVE #lockownerid",
"ConditionExpression": "attribute_exists(#lockownerid)",
"ReturnValues": "UPDATED_NEW"
},
Handling failure
If an execution fails, times out, or ends after a lock has been acquired but before it can be released, a lock is leaked. To handle this scenario, an Amazon EventBridge rule triggers the CC-CleanFromIncomplete state machine in reaction to these Step Functions execution status change events.
StateMachineSempaphoreCleanup:
Type: AWS::Serverless::StateMachine
Properties:
DefinitionUri: statemachines/dynamodb-semaphore-cleanfromincomplete.asl.json
DefinitionSubstitutions:
TableSemaphore: !Join ["",[!Ref ParameterInstancePrefix,"-","locktable"]]
LockName: !Ref ParameterLockName
Tracing:
Enabled: true
Role: !GetAtt ApplicationRole.Arn
Logging:
Destinations:
- CloudWatchLogsLogGroup:
LogGroupArn: !GetAtt LogGroupStateMachines.Arn
IncludeExecutionData: TRUE
Level: "ALL"
Type: "STANDARD"
Name: !Join ["",[!Ref ParameterInstancePrefix,'-',"CleanFromIncomplete"]]
Events:
RunForIncomplete:
Type: EventBridgeRule
Properties:
Pattern:
source:
- "aws.states"
detail:
stateMachineArn:
- !Ref StateMachineSempaphore
status:
- FAILED
- TIMED_OUT
- ABORTED
The LambdaDoWorkFunction function is purposely written to fail roughly one out of 10 times in order to demonstrate this behavior. You see that some of the executions from your tests failed.

For each of these failures, the CC-CleanFromIncomplete state machine starts.

This cleanup returns the lock state back to 0 at the end of your test, despite the failures.

Extending the example
To apply this concurrency control in your own application, replace the branch defined in the Do Work parallel state with a state machine definition that contains the business logic of your application. You also update the ConcurrentAccessLimit value template.yaml to specify the level of concurrency that your application requires.
Conclusion
In this blog post, you learn how to control concurrency in a distributed system. You implement a semaphore using Step Functions and DynamoDB Conditional Expressions. Finally, you use EventBridge to trigger lock cleanup when you encounter failure.
To learn more about Step Functions, visit Serverless Land.