AWS Compute Blog
Deploying a Burstable and Event-driven HPC Cluster on AWS Using SLURM, Part 1
Contributed by Amr Ragab, HPC Application Consultant, AWS Professional Services
When you execute high performance computing (HPC) workflows on AWS, you can take advantage of the elasticity and concomitant scale associated with recruiting resources for your computational workloads. AWS offers a variety of services, solutions, and open source tools to deploy, manage, and dynamically destroy compute resources for running various types of HPC workloads.
Best practices in deploying HPC resources on AWS include creating much of the infrastructure on-demand, and making it as ephemeral and dynamic as possible. Traditional HPC clusters use a resource scheduler that maintains a set of computational resources and distributes those resources over a collection of queued jobs.
With a central resource scheduler, all users have a single point of entry to a broad range of compute. Traditionally, many of these schedulers managed on-premises systems. They weren’t offered dynamically as much as cloud-based HPC clusters, and they usually only needed to manage a largely static set of resources.
However, many schedulers now support the ability to burst into AWS or manage a dynamically changing HPC environment through plugins, connectors, and custom scripting. Some of the more common resource schedulers include:
- SchedMD SLURM – Elastic Plugin
- IBM LSF – Resource Connector
- Univa Grid Engine – Navops
- Altair PBS
SLURM
Simple Linux Resource Manager (SLURM) by SchedMD is one such popular scheduler. Using a derivative of SLURM’s elastic power plugin, you can coordinate the launch of a set of compute nodes with the appropriate CPU/disk/GPU/network topologies. You standup the compute resources for the job, instead of trying to fit a job within a set of pre-existing compute topologies.
We have recently released an example implementation of the SLURM bursting capability in the AWS Samples GitHub repo.
The following diagram shows the reference architecture.
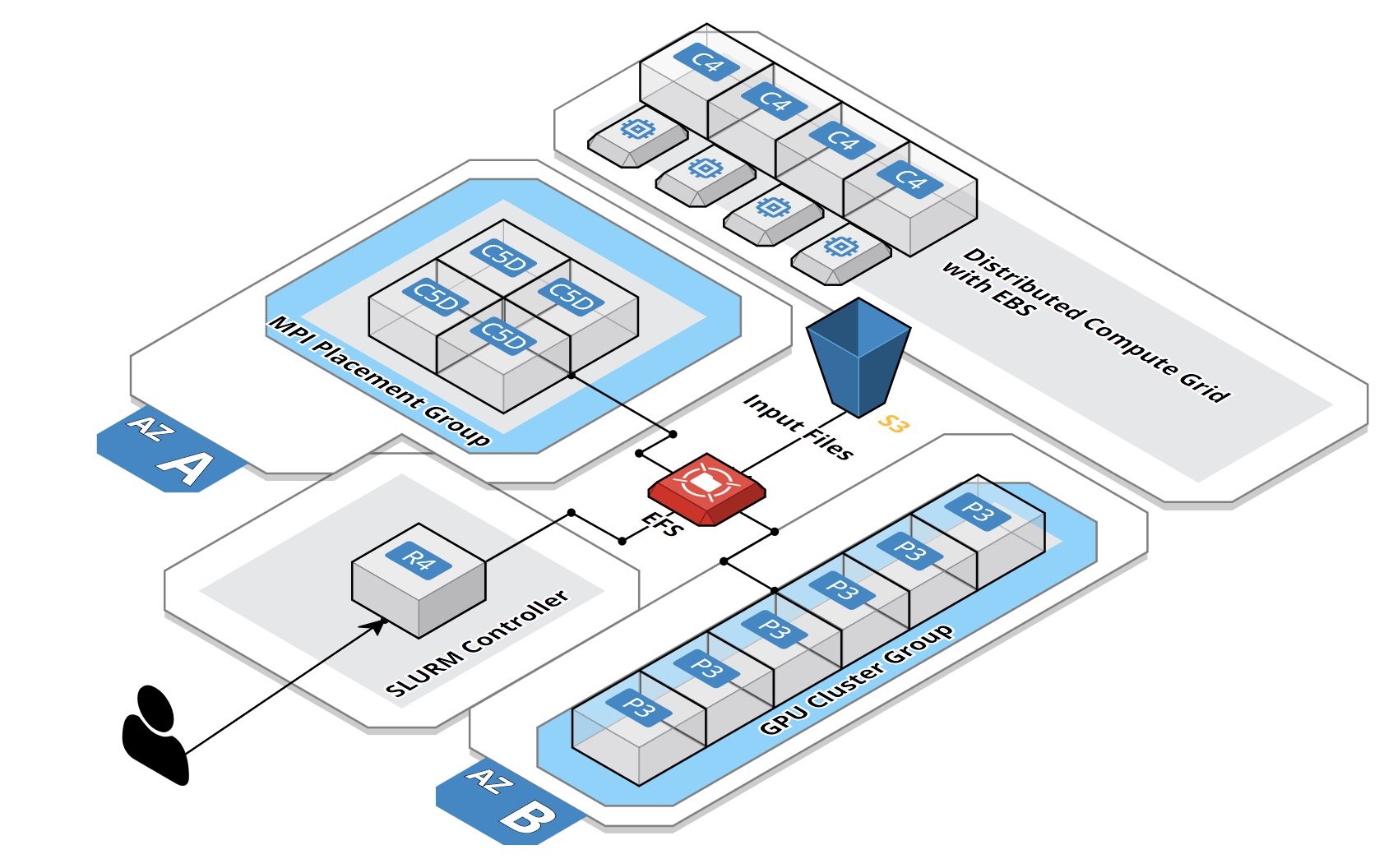
Deployment
Download the aws-plugin-for-slurm directory locally. Use the following AWS CLI commands to sync the directory with an S3 bucket to be referenced later. For more detailed instructions on the deployment follow the README within the GitHub.
git clone https://github.com/aws-samples/aws-plugin-for-slurm.git
aws s3 sync aws-plugin-for-slurm/ s3://<bucket-name>Included is a CloudFormation script, which you use to stand up the VPC and subnets, as well as the headnode. In AWS CloudFormation, choose Create Stack and import the slurm_headnode-clouformation.yml script.

The CloudFormation script lays down the landing zone with the appropriate network topology. The headnode is based on the publicly available CentOS 7.5 available in the AWS Marketplace. The latest security packages are installed with the dependencies needed to install SLURM.
I have found that scheduling performance is best if the source is compiled at runtime, which the CloudFormation script takes care of. The script sets up the headnode as a single controller. However, with minor modifications, it can be set up in a highly available manner with a backup SLURM controller.
After the deployment moves to CREATE_COMPLETEstatus in CloudFormation, use SSH to connect to the slurm headnode:
ssh -i <path/to/private/key.pem> centos@<public-ip-address>Create a new sbatch job submission file by running the following commands in the vi/nano text editor:
#!/bin/bash
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=4
#SBATCH --constraint=[us-west-2a]
env
sleep 60This job submission script requests two nodes to be allocated, running one task per node and using four CPUs. The constraint is optional but allows SLURM to allocate the job among the available zones.
The elasticity of the cluster comes in setting the slurm.conf parameters SuspendProgram and ResumeProgram in the slurm.conf file.
SuspendTime=60 ResumeTimeout=250 TreeWidth=60000 SuspendExcNodes=ip-10-0-0-251 SuspendProgram=/nfs/slurm/bin/slurm-aws-shutdown.sh ResumeProgram=/nfs/slurm/bin/slurm-aws-startup.sh ResumeRate=0 SuspendRate=0
You can set the responsiveness of the scaling on AWS by modifying SuspendTime. Do not set a value for ResumeRateor SuspendRate, as the underlying SuspendProgram and ResumeProgramscripts have API calls that impose their own rate limits. If you find that your API call rate limit is reached at scale (approximately 1000 nodes/sec), you can set ResumeRate and SuspendRate accordingly.
If you are familiar with SLURM’s configuration options, you can make further modifications by editing the /nfs/slurm/etc/slurm.conf.d/slurm_nodes.conffile. That file contains the node definitions, with some minor modifications. You can schedule GPU-based workloads separate from CPU to instantiate a heterogeneous cluster layout. You also get more flexibility running tightly coupled workloads alongside loosely coupled jobs, as well as job array support. For additional commands administrating the SLURM cluster, see the SchedMD SLURM documentation.
The initial state of the cluster shows that no compute resources are available. Run the sinfocommand:
[centos@ip-10-0-0-251 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
all* up infinite 0 n/a
gpu up infinite 0 n/a
[centos@ip-10-0-0-251 ~]$ The job described earlier is submitted with the sbatchcommand:
sbatch test.sbatchThe power plugin allocates the requested number of nodes based on your job definition and runs the Amazon EC2 API operations to request those instances.
[centos@ip-10-0-0-251 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
all* up infinite 2 alloc# ip-10-0-1-[6-7]
gpu up infinite 2 alloc# ip-10-0-1-[6-7]
[centos@ip-10-0-0-251 ~]$ The log file is located at /var/log/power_save.log.
Wed Sep 12 18:37:45 UTC 2018 Resume invoked
/nfs/slurm/bin/slurm-aws-startup.sh ip-10-0-1-[6-7]After the request job is complete, the compute nodes remain idle for the duration of the SuspendTime=60value in the slurm.conffile.
[centos@ip-10-0-0-251 ~]$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
all* up infinite 2 idle ip-10-0-1-[6-7]
gpu up infinite 2 idle ip-10-0-1-[6-7]
[centos@ip-10-0-0-251 ~]$ Ideally, ensure that other queued jobs have an opportunity to run on the current infrastructure, assuming that the job requirements are fulfilled by the compute nodes.
If the job requirements are not fulfilled and there are no more jobs in the queue, the aws-slurm shutdown script takes over and terminates the instance. That’s one of the benefits of an elastic cluster.
Wed Sep 12 18:42:38 UTC 2018 Suspend invoked /nfs/slurm/bin/slurm-aws-shutdown.sh ip-10-0-1-[6-7]
{
"TerminatingInstances": [
{
"InstanceId": "i-0b4c6ec4945afe52e",
"CurrentState": {
"Code": 32,
"Name": "shutting-down"
},
"PreviousState": {
"Code": 16,
"Name": "running"
}
}
]
}
{
"TerminatingInstances": [
{
"InstanceId": "i-0f3139a52f2602c60",
"CurrentState": {
"Code": 32,
"Name": "shutting-down"
},
"PreviousState": {
"Code": 16,
"Name": "running"
}
}
]
}
The SLURM elastic compute plugin provisions the compute resources based on the scheduler queue load. In this example implementation, you are distributing a set of compute nodes to take advantage of scale and capacity across all Availability Zones within an AWS Region.
With a minor modification on the VPC layer, you can use this same plugin to stand up compute resources across multiple Regions. With this implementation, you can truly take advantage of a global HPC footprint.
“Imagine creating your own custom cluster mix of GPUs, CPUs, storage, memory, and networking – just the way you want it, then running your experiment, getting the results, and then tearing it all down.” — InsideHPC. Innovation Unbound: What Would You do with a Million Cores?
Part 2
In Part 2 of this post series, you integrate this cluster with AWS native services to handle scalable job submission and monitoring using Amazon API Gateway, AWS Lambda, and Amazon CloudWatch.