AWS Compute Blog
Introducing JSONL support with Step Functions Distributed Map
This post written by Uma Ramadoss, Principal Specialist SA, Serverless and Vinita Shadangi, Senior Specialist SA, Serverless.
Today, AWS Step Functions is expanding the capabilities of Distributed Map by adding support for JSON Lines (JSONL) format. JSONL, a highly efficient text-based format, stores structured data as individual JSON objects separated by newlines, making it particularly suitable for processing large datasets.
This new capability enables you to process large collection of items stored in JSONL format directly through Distribtued Map and optionally exports the output of the Distributed Map as JSONL file. The enhancement also introduces support for additional delimited file formats, including semicolon and tab-delimited files, providing greater flexibility in data source options. Furthermore, new flexible output transformations gives developers more control over result formatting, enabling better integration with downstream processes for efficient data handling.
Overview
Distributed Map enables parallel processing of large-scale data by concurrently running the same processing steps for millions of entries in a dataset at the maximum scale of 10000. This is particularly useful for use cases like large scale payroll processing, image conversion, document processing and data migrations. Previously, the dataset can come from state input, JSON/CSV files in S3 and collection of S3 objects. With this new feature, the dataset can be a JSONL file in Amazon S3.
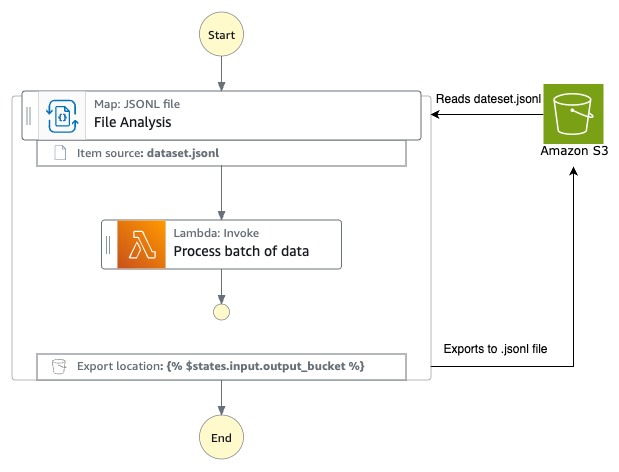
The AWS Step Functions workflow
Consider an example of end-to-end GenAI batch inferencing using Amazon Bedrock. Batch inference helps you process a large number of requests efficiently by bundling them as single request and storing the results in an S3 bucket. Since both input and output are handled as JSONL files, the blog uses the scenario as an example to demonstrate the new capabilities of Distributed Map.
The diagram below shows the end-to-end flow –
- Step Functions workflow (Batch inference input generation worfklow) uses Distributed Map to build and bundle AI prompts for a collection of product review data. Workflow then invokes the Amazon Bedrock batch inference API.
- Amazon Bedrock stores the results in S3 as JSONL file when the batch inference is completed.
- An S3 object created event invokes the second Step Functions workflow (Batch inference output processing workflow) that processes the JSONL file and loads the results into an Amazon DynamoDB table.

Batch inferencing workflow
Introducing new output transformations through batch inference input generation workflow
The batch inference input generation workflow processes product review data in S3 using Distributed Map. Distributed Map spins multiple child workflows that generate AI prompts for sentiment analysis of each product review and exports the results of the child workflows to S3 as a JSONL file. The workflow calls Amazon Bedrock batch inference API (CreateModelInvocationJob) with the JSONL file as input upon completion of the Distributed Map state. Since the inference API operates asynchronously, the workflow completes immediately after receiving a successful response from the API.

Batch inference input generation workflow
Each child workflow receives a batch of product reviews as an array. It operates on the array using Pass state to create an array of AI prompts, one for each item. The Pass state manipulates the input using JSONata expressions, generates unique recordId using JSONata numeric functions, and outputs the results in a format Amazon Bedrock expects.
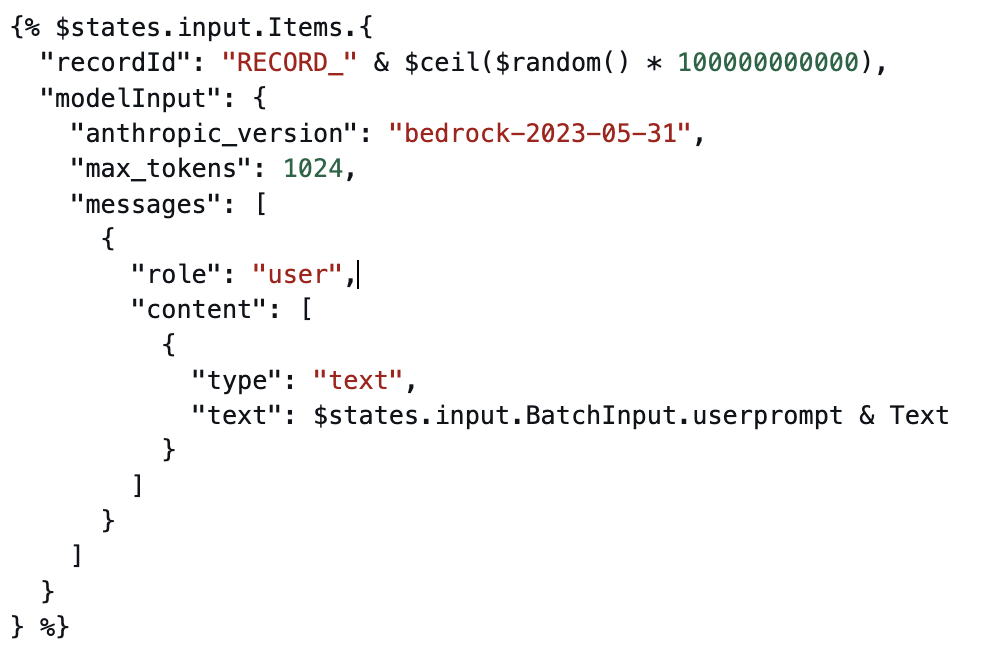
JSONata transformation to generate prompts
Once all child workflows are complete, Distributed Map uses the new output transformations to export the outputs from child workflows to S3.
Using the new output transformations to export in JSONL format
Distributed Map now offers more flexible output handling through an optional writer configuration. While it traditionally exports child workflow execution results to three separate JSON files (successful, failed, and pending), the new writer configuration streamlines the output and supports JSONL format in addition to JSON format.
The previous export option included comprehensive execution details – metadata, child workflow inputs, and outputs. The new configuration allows you to streamline output to include only the child workflow execution results, which are valuable for map/reduce patterns, where the output from one Distributed Map needs to feed directly into another without the need for additional transformation steps.
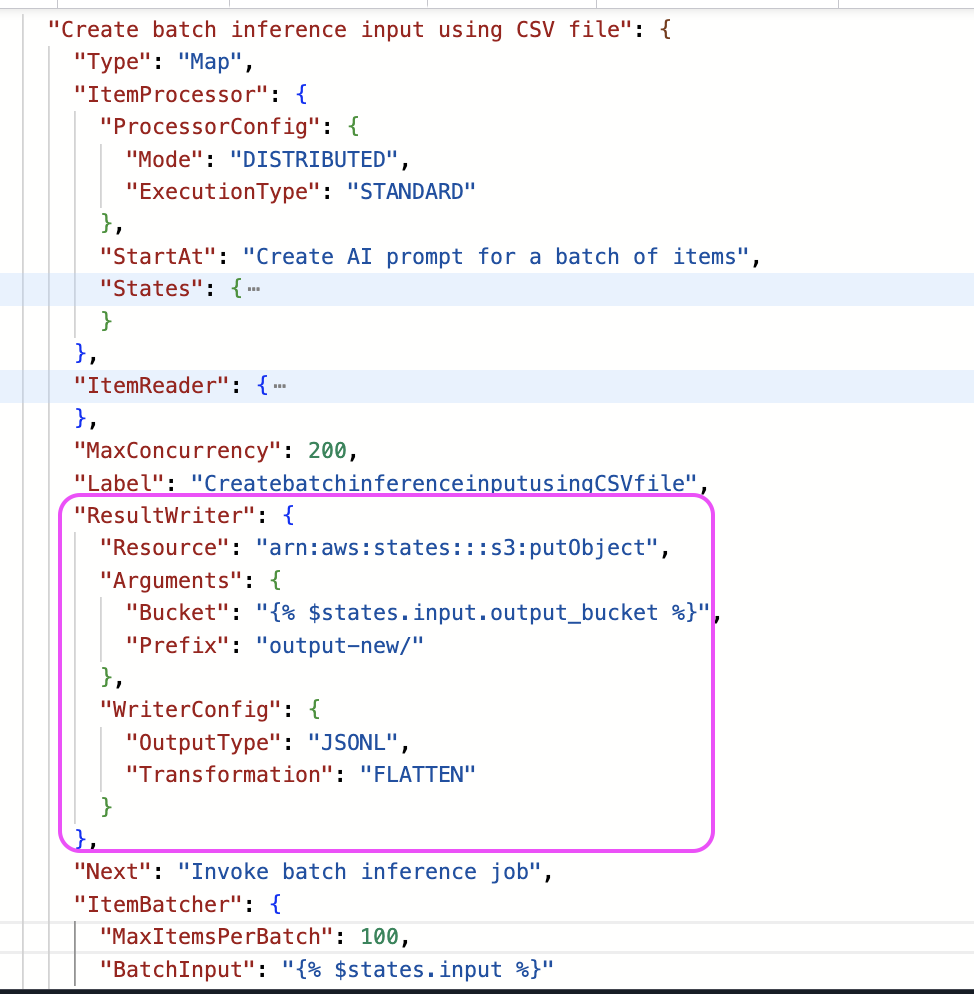
Output writer config for JSONL
Writer config also allows you to flatten the output array. When a child workflow processes batches of the input, it produces an array of results which will eventually become an array of arrays when the Distributed Map aggregates the outputs from all child workflows. With the new output transformation called FLATTEN, you can choose to flatten the array without additional code.

Flattening output in JSONL
Introducing the new ItemReader for JSONL using batch inference output processing workflow
The second workflow processes output of the batch inference job by launching multiple child workflows using Distributed Map. Each child workflow processes batches of items, examining them for error objects and separating successful inferences from errors. The workflow then loads all successful inferences into a DynamoDB table while sending errors to a dead letter queue for subsequent analysis.

Processing inference results
Using the new InputType to read the JSONL inference results
The Distributed Map in the batch inference results processing workflow uses the newly supported ItemReader-InputType, JSONL. Previously, the InputType only accepted CSV, JSON, and MANIFEST, which is an S3 Inventory manifest file.

Reading JSONL file
There is no other change to how Distributed Map processes and shares data with child workflows. The Pass state in the child workflow receives batches of Items from the Map, and uses JSONata expressions to separate the errors from successful items.

Separating successful processing from errors
The following shows the input received by the Pass state and the output generated by the state using the above JSONata expression.

Sample successful processing records
Using S3 events as connective tissue between the workflows
When Amazon Bedrock completes the batch inference job, it stores the output in the S3 location specified in the API request. An EventBridge rule triggers the batch inference results processing workflow using S3 event notifications. The rule looks for “Object Created” event from the specified S3 bucket and a wildcard pattern for JSONL file extension. When the rule matches the incoming event, it triggers the workflow.

EventBridge rule
You can detect failed batch inference jobs by setting up EventBridge rules that listen to Amazon Bedrock status events. Since failed jobs don’t create output files in S3, monitoring status events directly ensures you catch and handle job failures.
Key considerations
- The new output transformations do not change the information in the FAILED execution results file in order to help you analyze the reasons for failures. To learn more about the output transformation configurations, visit the documentation.
- The new transformation mode FLATTEN, COMPACT stores only the output of the execution results. To inspect the results for fact checking or troubleshooting, use the default transformation.
- As a best practice, when implementing code changes, it’s advised to use the versioning and aliasing feature for gradual deployment of changes to production.
- When using Distributed Map, there is an option to configure the child workflow as either Standard or Express. Express is the recommended choice if each iteration (child workflow) can be completed within 5 minutes, and batching items will help optimize costs. To learn more about optimizations for Distributed Map, visit the workshop.
Conclusion
Step Functions Distributed Map is a powerful feature that enables developers to create large-scale data processing solutions with ease, eliminating concerns about operational aspects and software challenges like batching, concurrency, and failure handling. The addition of JSONL support for both input and output expands workload capabilities and minimizes additional effort through transformations by natively deserializing and flattening the output. This blog demonstrated the new feature’s capabilities through a practical example of building large-scale data processing applications using Distributed Map.
For more information on Distributed Map and how to use it with JSONL files, refer to the user guide.
To explore generative AI samples with Step Functions, visit the the GitiHub repo.
To expand your serverless knowledge, visit Serverless Land.