Containers
Running Airflow on AWS Fargate
Apache Airflow is an open-source distributed workflow management platform that allows you to schedule, orchestrate, and monitor workflows. Airflow helps you automate and orchestrate complex data pipelines that can be multistep with inter-dependencies. This post presents a reference architecture where Airflow runs entirely on AWS Fargate with Amazon Elastic Container Service (ECS) as the orchestrator, which means you don’t have to provision and manage servers.
Given the advances in cloud computing and cheaper storage, our reliance on data as a society continues to grow every day. Whether we are making financial predictions, understanding sales figures, or buying a new vacuum cleaner, datasets help us at every step of the decision-making process. Today, many systems generate telemetry data used to understand customer behavior, analyze trends, and enhance our products; however, a significant portion of the data most systems generate is not readily consumable. Raw data must be processed, cleansed, and married to other data sources before it can catalyze meaningful insights. To keep up with this explosion of data, batch processing, which continues to be at the core of data analytics, has become distributed and massively parallel, giving data scientists the ability to compute massive amounts of data at near real-time speeds in a cost-effective manner.
Apache Airflow is much more than a simple batch processing platform. It allows you to develop pipelines that process data or run complex jobs in an automated and distributed manner. Data scientists and developers have found Airflow useful in a wide variety to use cases, anywhere from the extraction of a few columns from a comma-separated text file to paying dividends on a popular trading platform or managing video processing. Operating Airflow, however, has traditionally required data scientists to manage servers in addition to developing the business logic. Many customers find it complicated to right-size servers to match job requirements, and maximizing the infrastructure investment is often a non-trivial exercise.
Benefits of running Airflow using AWS Fargate
With AWS Fargate, you can run Airflow core components and its jobs entirely without creating and managing servers. You don’t have to guess the server capacity you need to run your Airflow cluster, worry about bin packing, or tweak autoscaling groups to maximize resource utilization. You only pay for resources that your Airflow jobs need. Here are some benefits of running Airflow using Fargate:
- No more patching, securing, or managing servers — Fargate ensures that the infrastructure your containers run on is always up-to-date with the required patches, which reduces your team’s operational burden significantly. To upgrade your Airflow cluster, you’ll update the Fargate task with the Airflow container image and restart.
- Managed autoscaling — Fargate allows you to match the compute resources requirements of your Airflow jobs; it helps you add capacity automatically when your cluster is busier without paying for any idle capacity. Each Airflow job runs in a separate Fargate task, so the number of concurrent workflows you can run is only limited by the Fargate quotas in your account. Fargate can also help autoscale Airflow core components, like the web server and scheduler, using Service Auto Scaling.
- Logging and monitoring come included — Fargate has built-in observability tooling, so you don’t have to create your own logging and monitoring infrastructure. You can use the awslogs log driver to send logs to CloudWatch Logs or use Firelens for custom log routing. Logs produced by your Airflow jobs can be collected and consolidated using Fargate’s out-of-the-box logging capabilities.
- Isolation by design — Each Fargate task runs in its own VM-isolated environment, which means concurrent tasks don’t compete for compute resources. You also don’t need to separate sensitive workloads; in Fargate, tasks don’t share Linux kernel with other tasks.
- Spot integration — Airflow jobs can be perfect candidates for Fargate Spot if they can tolerate interruptions, which can help you save up to 70% off the Fargate price.
That’s not all! You also benefit from Fargate’s integrations with other AWS services like AWS Systems Manager and AWS Secrets Manager for storing credentials and configuration securely, and Amazon EFS for persistent storage for tasks that need more than 20GB disk space.
Amazon Managed Workflows for Apache Airflow (MWAA)
At re:Invent 2020, we announced Amazon Managed Workflows for Apache Airflow (MWAA). Managed Workflows is a managed orchestration service for Apache Airflow that makes it easy for data engineers and data scientists to execute data processing workflows on AWS. With MWAA, you can deploy and get started with Airflow in minutes.
MWAA helps you orchestrate workflows and manage their execution without managing, configuring, or scaling Airflow infrastructure. The service manages setting up Airflow, provisioning and autoscaling capacity (compute and storage), automated snapshots, and keeping Airflow up-to-date. It also provides simplified user management and authorization through AWS Identity and Access Management (IAM) and Single Sign-On (SSO).
We recommend customers running Airflow on AWS consider Amazon Managed Workflows for Apache Airflow as the preferred option. If MWAA doesn’t meet your organization’s requirements, running self-managed Airflow on Fargate (as this post demonstrates) can be a viable alternative.
Airflow on Fargate architecture
The infrastructure components in Airflow can be classified into two categories: components that are needed to operate Airflow itself and components that are used to run tasks. The components that belong to the first category are:
- Web server: provides Airflow’s web UI.
- Scheduler: schedules DAGs (Directed Acyclic Graph)
- Database or meta-store: stores Airflow’s metadata
- Executor: the mechanism by which task instances get run
The Airflow documentation describes a DAG (or a Directed Acyclic Graph) as “a collection of all the tasks you want to run, organized in a way that reflects their relationships and dependencies. A DAG is defined in a Python script, which represents the DAGs structure (tasks and their dependencies) as code.”
Using Airflow you can create a pipeline for data processing that may include multiple steps and have inter-dependencies. A DAG represents a sequential process. In other words, there are no loops (hence the name acyclic). For example, a pipeline with steps N1, N2… Nz can go from step N1 to N2 to N3, skip N4, proceed to N5, but it cannot return on N1.
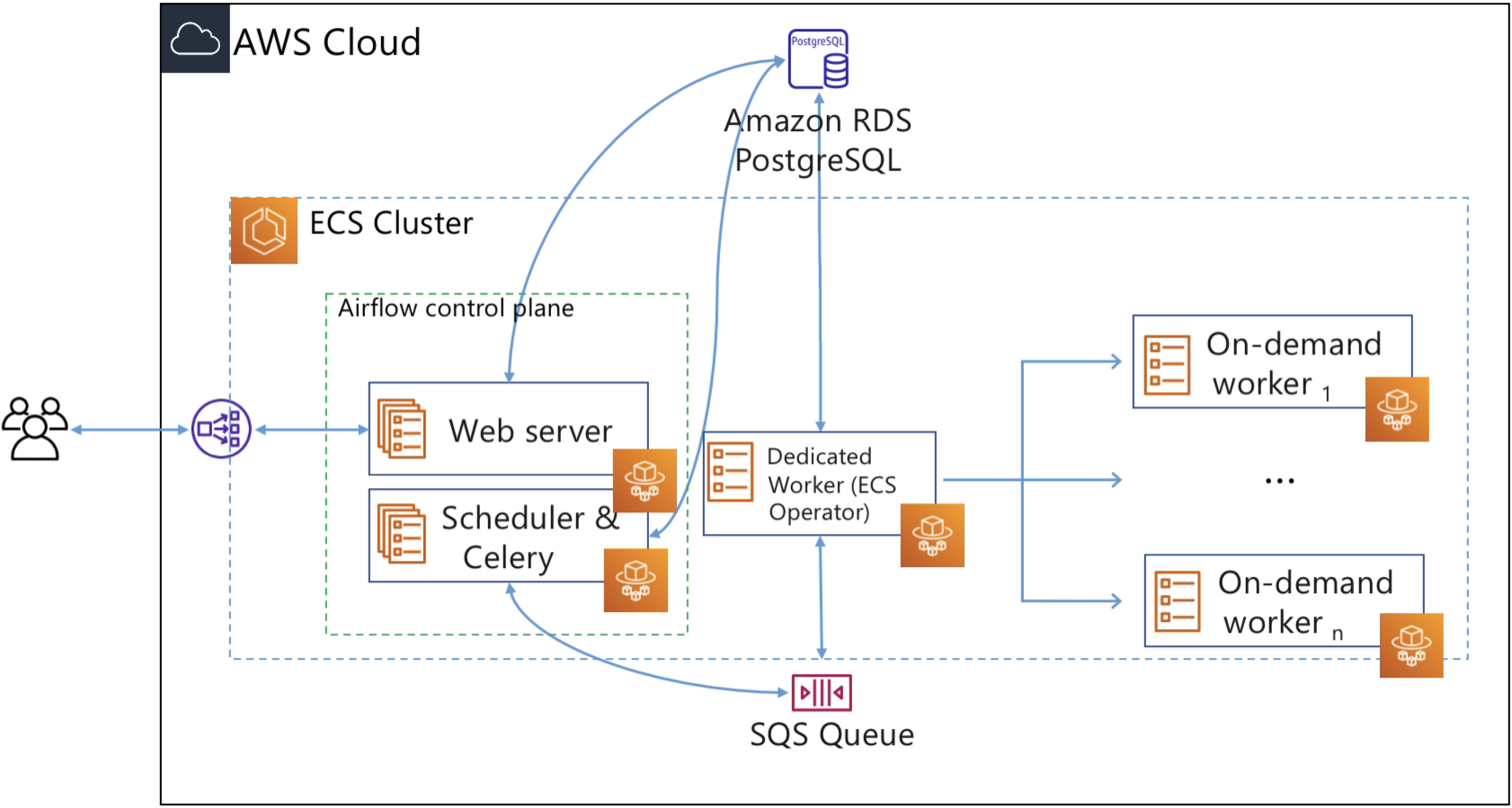
In this post, we run the Airflow control plane components (web server and scheduler) as Fargate services. We use an RDS PostgreSQL database for Airflow metadata storage. To keep the architecture as serverless as possible, we opt for Celery Executor and Amazon SQS as the broker for Celery. In Airflow, the executor runs alongside the scheduler. As the name suggests, the scheduler schedules task by passing task execution details to the executor. The executor then queues tasks using a queuing service like Amazon SQS.
Workers are the resources that run the code you define in your DAG. In Airflow, tasks are created by instantiating an operator class. An operator is used to execute the operation that the task needs to perform. So you define a task in DAG, and the task is then executed using an operator. Since we want to execute tasks as Fargate tasks, we can use the ECS operator, which allows you to run Airflow tasks on capacity provided by either Fargate or Amazon EC2. In this post, we will use the ECS operator to execute tasks on Fargate.

For each task that users submit, the ECS operator creates a new Fargate task (using the ECS run-task API), and this Fargate task becomes the worker that executes the Airflow task.
Below is a sample DAG, taken from Airflow documentation, that uses an ECS operator. Notice how similar its parameters are when compared to the inputs for ECS’s run-task API. This DAG would run the task on Fargate because the launch_type is “FARGATE”, you can change this to EC2 to run tasks on EC2-backed container instances.

Solution
We will demonstrate how you can operate Apache Airflow using AWS Fargate, Amazon SQS, and Amazon RDS. To create the infrastructure, we will use AWS Cloud Development Kit (CDK). You will need these components before starting:
Install CDK:
npm install -g aws-cdkOnce you’ve installed CDK and Node.js, clone the sample code repository:
git clone https://github.com/aws-containers/Airflow-on-Fargate.gitNext, install the dependencies, build, and deploy the stack:
cd Airflow-on-Fargate
# Install dependencies
npm install
# Build this package and generates
# the Cloudformation Stack with resources
npm run build
# Deploy the CloudFormation template
# to your AWS account
cdk deploy The CloudFormation stack includes these resources:
- A VPC
- Two public and two private subnets
- An RDS PostgreSQL instance
- Task definitions for Airflow web server, scheduler, and ECS operator
- A Fargate service with one ECS task with three containers
- Airflow web server
- Airflow scheduler
- Dedicated worker task, required for the ECS operator
- A Network Load Balancer that exposes the Airflow web server
- An Amazon EFS filesystem, which will be used for container storage.
Once CloudFormation completes deploying the stack, CDK will print the Network Load Balancer’s address and the password for the Airflow web server. Navigate to the address and login to the dashboard as “admin” by using the password from the CDK output.
You can configure Airflow to use an existing authentication mechanism by modifying airflow.cfg as explained in the security section of Airflow documentation.
Run tasks
With the Airflow control plane setup, we can start submitting and running tasks. We have included a sample DAG, which runs a very simple data processing job on Fargate. It takes a list of integers and categorizes them as even or odd.

This DAG shows how to create parallel tasks with the use of the ECS operator, which creates on-demand Fargate tasks. It comprises five tasks:
start_processis a dummy task that runs on Airflow’s default worker (which is called ECS operator in the architecture diagram above).odd_taskexecutesodd_numbers.py. This will be executed in a Fargate task.even_taskexecuteseven_numbers.py. This will be executed in an on-demand Fargate task.numbers_taskexecutesnumbers.py. This will be executed in an on-demand Fargate task.on_worker_taskalso gets executed on the default worker. It shows how to use the Python operator to run a task on an Airflow worker.
Each sub-folder under
taskswill result in a new Fargate TaskDefinition. These task definitions will be used in the ECS operator.
Let’s trigger “Test_Dag” and see what happens.
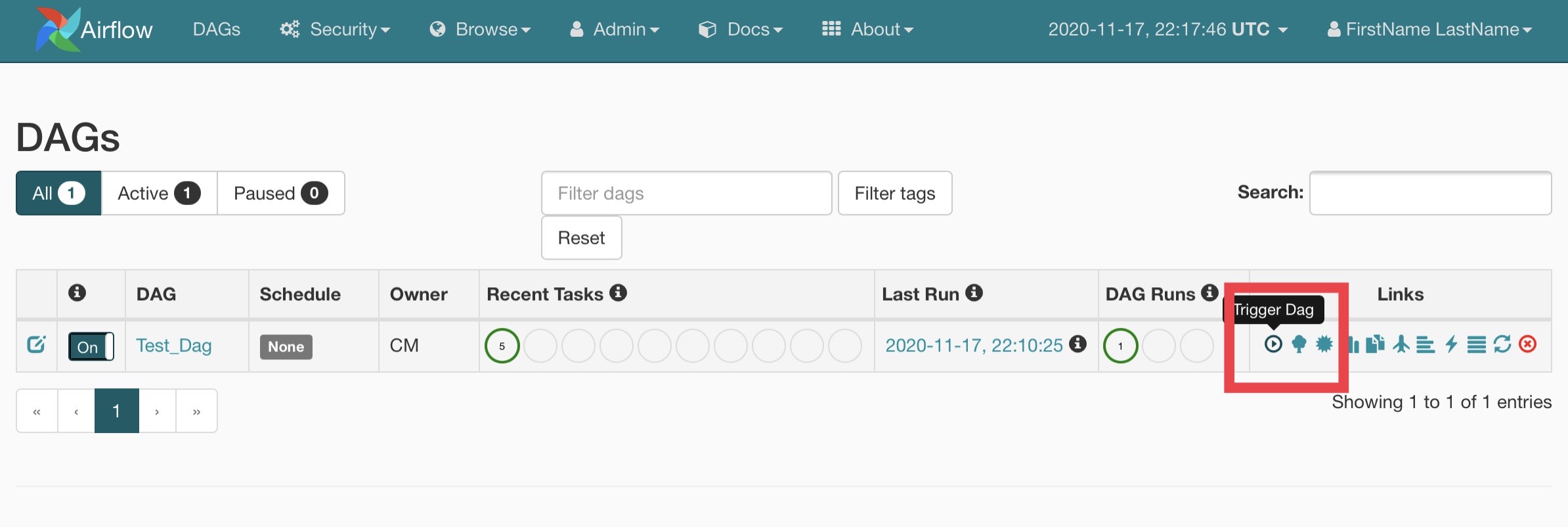
For this DAG, Airflow creates two new Fargate tasks (using the ECS operator.) Each task is responsible to extract odd or even numbers from a range of numbers (from 1 to 10). This is the “odd_task” and “even_task” step shown in the DAG’s graphical view above. Once the odd and even task finish, the “numbers” task runs, and joins the outputs of odd and even tasks.

The tasks save the processed results to a shared Amazon EFS volume to demonstrate how you can execute Airflow tasks that require persistent storage.
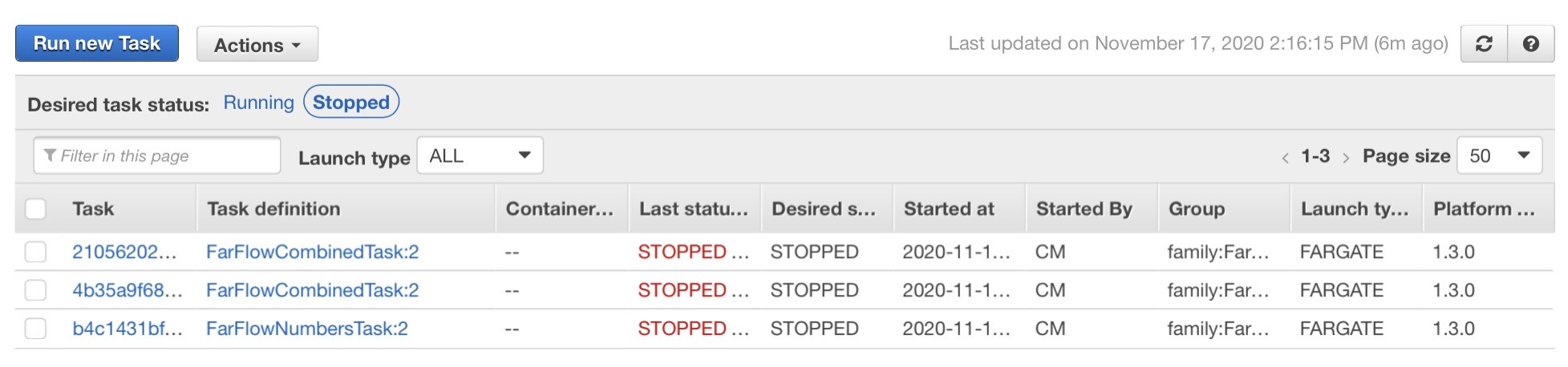
If you go to the ECS console, and look under Stopped Tasks, you will see three tasks. See the screenshot below; the first two tasks run odd_task and even_task, whereas the third one runs numbers_task.
Looking under the hood
We saw what happens when you trigger a DAG: a number of Fargate tasks are executed that run the code to process data. Let’s further inspect the process flow within Airflow components and how they interact with Fargate.
When you trigger the included Test DAG, the Airflow scheduler creates a new instance of the task. It passes the information to the Celery Executor, which provides a way to run Python processes in a distributed manner. Celery then sends the task information to SQS using Celery message protocol. The dedicated Airflow worker monitors the SQS queue for messages. As soon as it receives a message, it creates a Fargate task to execute the DAG’s code using the ECS operator.
ECS operator is a Python application that uses Boto 3 to create and manage ECS tasks. The dedicated Airflow worker uses the ECS operator to create ECS tasks. In our example, the dedicated worker receives instructions to create two Fargate tasks to run the code to separate odd and even numbers; these two tasks run in parallel (this is defined in the DAG’s code). Once odd and even separation tasks finish, the ECS operator will create a new Fargate task to run a Python process to print the numbers that were separated by the odd and even tasks.
Task sizing
Each Airflow task runs in its own Fargate task, which means you can control how much CPU and memory each Airflow task gets. The ECS operator creates Fargate tasks by referencing ECS task definitions. You can define the CPU and memory requirements for your Airflow tasks in their task definitions.
For this post, we created two task definitions to run Airflow tasks. We allocated 512 vCPU and 1024 MiB of memory for odd or even tasks, whereas the “numbers” task requires 256 vCPU and 512 MiB RAM.
Cleanup
Use the following command to delete resources created during this post:
cdk destroyDesign considerations
Because we use Fargate to execute Airflow jobs, the compute resources you can assign to a task can use up to 4vCPU or 32 GB RAM, which is the maximum task size that Fargate supports today. By default, Fargate provides 20 GB of disk space to each task; if your tasks need more storage, you can configure your containers to store data to a shared EFS filesystem.
You can also use EC2 instances to run Airflow jobs by configuring the DAG to use EC2 instead of Fargate. This way, you can run Airflow control plane components on Fargate while using EC2 instances to execute jobs.
Alternatively, you can use Fargate Spot to run workflows. Fargate Spot offers up to 70% discount off the Fargate price, which can translate to significant savings. This post doesn’t include the usage of Fargate Spot as it is not supported by CDK currently. You can track this feature request here.
Conclusion
AWS Fargate allows you to run complex workloads like Airflow without managing servers. Fargate simplifies cost-optimization exercise since you only pay for the compute resources your workloads need. Since each Fargate task runs in a VM-isolated environment, concurrent tasks don’t compete for resources, and the data plane scales automatically.
Many AWS customers are already running Airflow on Fargate, Affirm’s Greg Sterin recently blogged about their Airflow journey from EC2 to Fargate in this post.