AWS Database Blog
Amazon Aurora PostgreSQL blue/green deployment using fast database cloning
December, 2023: Amazon Relational Database Service (Amazon RDS) now supports Amazon RDS Blue/Green Deployments to help you with safer, simpler, and faster updates to your Amazon Aurora and Amazon RDS databases. Blue/Green Deployments create a fully managed staging environment that allows you to deploy and test production changes, keeping your current production database safe. Learn more about Blue/Green Deployments on the Amazon RDS documentation.
In a traditional approach to application deployment, you have no real opportunity to validate new versions or features in a realistic, live deployment while continuing to run the old version in production environment. In some situations, recovering from a failed upgrade or failures in the schema modification process can impact your production environment, which in turn impacts application availability and tarnishes the public image you’re working hard to build.
In this post, we show you how to take advantage of Amazon Aurora PostgreSQL-Compatible Edition for a blue/green deployment strategy by using Aurora fast database cloning for database changes and major version and minor version upgrades.
Blue/green deployment
The following diagram depicts the high-level blue/green deployment architecture.

A blue/green deployment is a deployment strategy in which you create two separate, but identical environments. This strategy can mitigate common risks such as downtime and rollback capability associated with database change management processes like application changes, schema changes such as creating new indexes or modifying indexes on a very large table, data reorganization, and major version and minor version upgrades without impacting the blue environment. The blue environment represents the current database version serving production traffic, and the green environment represents the new version.
An application upgrade usually requires database schema changes, whereas database version upgrades might not require application changes. Database modifications with schema changes like adding or dropping columns for a table are supported by most online replication methods like PostgreSQL native logical replication and pglogical, and can be performed with minimal downtime. Limitations with online replication methods like lack of primary keys for tables or large objects (LOBs) replication from the blue to green environment requires scheduled downtime. For more information about limitations with PostgreSQL online replication methods, see Understand replication capabilities in Amazon Aurora PostgreSQL.
To achieve minimum downtime, the green environment is created restoring a consistent backup from the blue environment at a particular log sequence number (LSN), for example, 100. When the restore on the green environment is complete, start the online logical replication from the blue to green environment from the LSN you noted in the previous step. Additionally, bi-directional replication between the blue and green environments allows you to perform database cutover or failback, if needed.
With the scheduled downtime, writes are stopped, allowing only reads on the blue environment for data consistency between environments. The green environment is created from the blue environment at a consistent state.
The desired change is applied on the green database environment only. When testing is complete on the green environment, live application traffic is directed to the green environment and the blue environment is deprecated. In addition, if something unexpected happens with your new version on the green environment, you can immediately roll back to the last version by switching back to the blue environment.
Aurora fast database cloning
Aurora fast database cloning takes advantage of the underlying distributed storage engine of Aurora. The fast database cloning feature uses a copy-on-write protocol, in which new pages are created copying the data and updating the pointers when data changes on either the source database or the clone database. Minimal additional space is required for creating the initial clone. When the clone is first created, Aurora keeps a single copy of the data that is used by the source Aurora cluster and the cloned Aurora cluster.
The following diagram illustrates the state of a fast cloned database created on Aurora with no storage changes made. Both the source and cloned database reference the same pages on the shared distributed storage system of Aurora.

Additional storage is allocated only when changes are made to data (on the Aurora storage volume) by the source Aurora cluster or the clone Aurora cluster. To learn more about the copy-on-write protocol, see How Aurora cloning works.
The following diagram illustrates the state depicting a fast clone database created on Aurora with storage changes made on both the source and clone clusters. Both databases reference common pages on the shared distributed storage system of Aurora.

Let’s say that you make a change to your source database that results in a change to data held on page 4. Instead of writing to the original page 4, Aurora creates a new page 4[A]. The Aurora DB cluster volume for the source database now points to pages 1, 2, 3, and 4[A], while the clone database still references the original pages.
On the clone, a change is made to pages 3, 4, and 5 on the storage volume. Instead of writing to the original pages 3, 4, and 5, Aurora creates new pages 3[B], 4[B], and 5[B]. The clone now points to original pages 1 and 2, and to pages 3[B], 4[B], and 5[B].
The following diagram shows the blue and green implementation using the Aurora fast cloning feature.

You can share Aurora DB clusters and clones that belong to your AWS account with another AWS account or organization using AWS Resource Access Manager (AWS RAM) with Aurora.
Solution Overview
Aurora PostgreSQL with fast database cloning provides a great environment to manage blue/green deployments in a cost-effective and low risk way with minimal impact on the primary database. This post shows how you can perform Aurora PostgreSQL blue/green deployment using fast database cloning with planned downtime. The blue environment represents the current Aurora PostgreSQL database version serving production traffic.
Native PostgreSQL online replication methods like logical replication and pglogical start by copying a snapshot of the initial existing data on the publisher database. When complete, the changes on the publisher (INSERT, UPDATE, and DELETE) are relayed to the subscriber in near-real time and don’t have good mechanisms yet to replay the changes to replicate the database changes from the last LSN with logical decoding from the blue to green environment. In logical decoding, clients are responsible for avoiding ill effects from handling the same message more than once. To achieve data consistency between environments, writes are stopped on the blue environment, with applications continuing to read data during the planned downtime. We use Aurora fast database cloning to create a clone cluster in the green environment from the source Aurora PostgreSQL cluster in the blue environment.
We perform schema changes and a new database version upgrade on the new cloned Aurora cluster in the green environment. After the testing is complete on the green environment, application traffic is routed from the blue to the green environment. To avoid possible data inconsistency and a split-brain situation, never write to both blue and green environment Aurora clusters at the same time.
The following diagrams depict the order of events, showing the steps to implement the solution.
- During the planned downtime to achieve data consistency, stop writes on the blue environment with applications continuing to read data.
- Create an Aurora clone cluster in the green environment using fast database cloning from the source Aurora PostgreSQL cluster in the blue environment.
The PostgreSQL database engine version of the source Aurora cluster in the blue environment and the clone cluster in the green environment remains the same in this step.

- Apply schema changes like adding indexes or data reorganization and major version or minor version upgrades on the Aurora clone cluster in the green environment.

- Perform necessary tests on the green environment to estimate the planned downtime.
The length of downtime varies, depending on multiple factors like workload on the database, size of the database, instance type chosen, data reorganization, and schema changes on the green environment.
- After you complete testing in the green environment, switch application traffic from the blue environment to the green environment. Amazon Route 53 friendly DNS names (CNAME records) are created to point to the different and changing Aurora endpoints in blue/green deployment, to minimize the amount of manual work you have to undertake to re-link your applications during cutover.
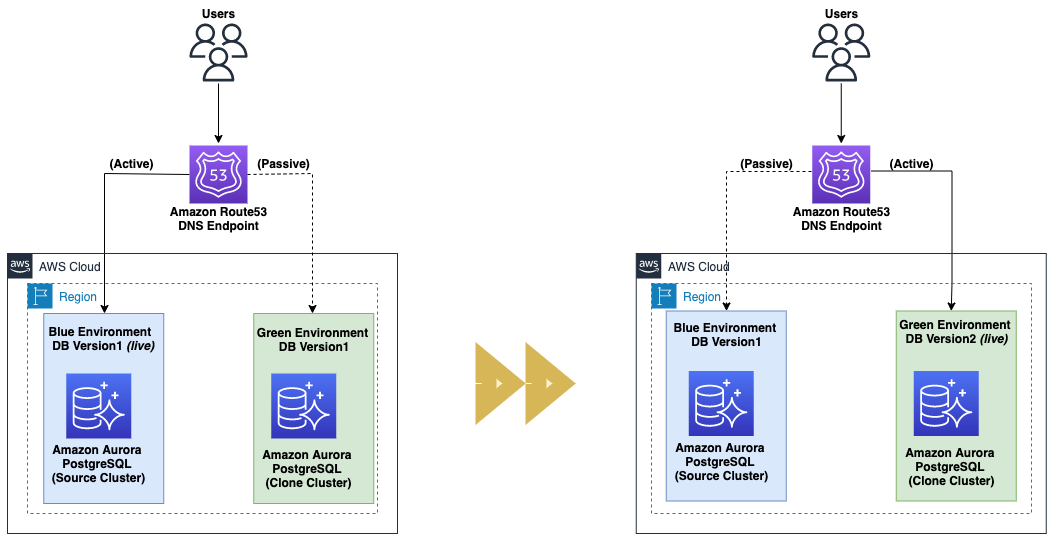
This is the point at which your downtime stops.
Prerequisites
Before you get started, make sure you complete the following prerequisites:
- Choose a Region to deploy your Aurora PostgreSQL DB cluster to serve your applications. For this post, we create an Aurora PostgreSQL DB cluster on version 12.8.
- Verify the limitations of Aurora cloning.
Create an Aurora clone cluster for a pre-existing Aurora PostgreSQL cluster
To create your Aurora clone cluster, complete the following steps:
- Stop all the applications that write to the Aurora PostgreSQL cluster in the environment, and make sure all the write activities are stopped on the database and there is no application database connection.
If you can’t easily stop application writes, you can work around it by blocking application access to the database. For example, modify security groups to block access to the database, or revoke write access to users on the database.
Now we can create our Aurora clone cluster.
- On the Amazon RDS console, choose Databases.
- Select your source cluster (for this post, we use
sourceclusterinus-east-1). - On the Actions menu, choose Create clone.

- For DB instance identifier, enter the name of your instance.
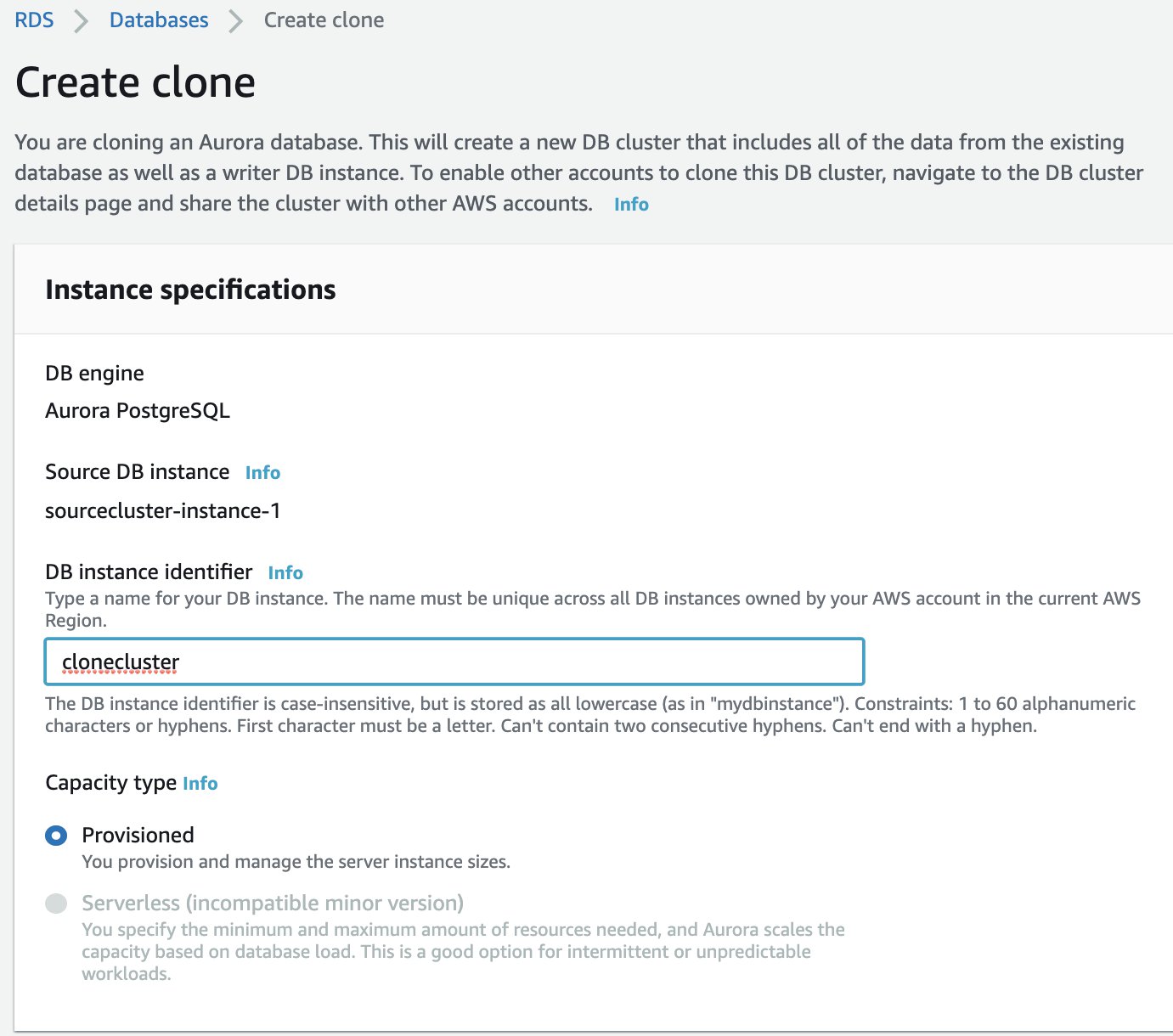
- For Additional configuration, choose settings as you usually do for your Aurora DB clusters.
- Finish configuring all the settings for your Aurora DB cluster clone.
To learn more about Aurora DB cluster and instance settings, see Creating an Amazon Aurora DB cluster.
- Choose Create clone to launch the Aurora clone of your chosen Aurora DB cluster.
When the clone is created, it’s listed with your other Aurora DB clusters on the console Databases page and displays its current state. Your clone is ready to use when its state is Available.
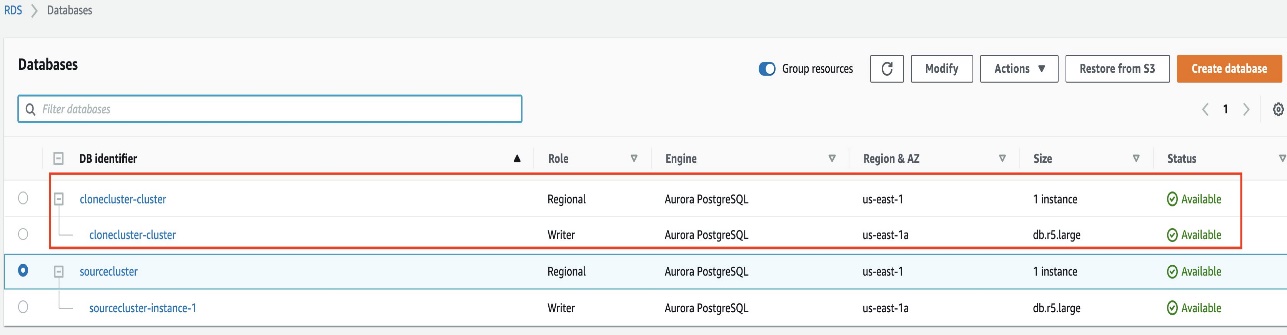
The Aurora fast database cloning creates a cloned cluster in the same Region and same PostgreSQL database version as the source Aurora PostgreSQL cluster.
Apply schema changes to the green environment
To apply your schema changes, complete the following steps:
- Connect to the clone Aurora PostgreSQL database in the green environment as an application user (for this post, the user is
appuser) using psql with following code: - Apply schema changes like adding columns and rebuilding indexes to the Aurora PostgreSQL database in the green environment using following example code:
The PostgreSQL REINDEX SQL command rebuilds an index using the data stored in the index’s table, replacing the old copy of the index.
Upgrade the Aurora PostgreSQL cluster in the green environment
Before you upgrade the newly created Aurora PostgreSQL clone cluster, we recommend reviewing the PostgreSQL documentation for information about behavior changes and deprecated and desupported features, and also refer to PostgreSQL versioning and Amazon Aurora PostgreSQL releases and engine versions for other considerations.
In this step, you can choose to perform either a major version upgrade or minor version upgrade of the Aurora PostgreSQL cluster in the green environment. To perform an in-place upgrade in the green environment, you modify the Aurora PostgreSQL cluster via one of the following methods:
- The Amazon RDS console (see Console)
- The AWS Command Line Interface (see AWS CLI)
- The Amazon RDS API (see RDS API)
The following code is an example of an Aurora PostgreSQL in-place major version upgrade in the green environment from PostgreSQL database version 12.8 to 13.4 using the AWS CLI modify-db-cluster command:
When the upgrade process is complete, verify that the status of the Aurora PostgreSQL cluster in the green environment is in an Available state.
Cut over from the blue environment to the green environment
After you complete functional and performance testing on the green environment, you’re ready to point your applications to the new major application version of the green environment. Before you cut over, you should consider the following checklist as a reference (and add additional checks as required to tailor to your environment):
- The green environment becomes the new production database after cutover. Therefore, avoid destructive tests on the green environment that cause data changes or data inconsistency between environments.
- Make sure that all users and roles are set up with appropriate permissions in the green environment.
- Verify the green environment is configured with the correct instance type, custom DB parameter groups, and security groups.
- Make sure at least one read replica is created for the Aurora clone cluster in the green environment for high availability in multiple Availability Zones for production databases.
- Modify your application to point to the green environment and start the application to route production traffic to the green environment.
- Conduct necessary tests to verify that the application is working correctly.
After the switchover to the green environment, you can use the blue environment for further testing, or delete it by following the cleanup steps in the next section.
Clean up
To clean up after cutover, delete the Aurora PostgreSQL cluster and database instances in the blue environment. For instructions, see Deleting Aurora DB clusters and DB instances.
Conclusion
In this post, we covered how you can implement Aurora PostgreSQL blue/green deployment using Aurora fast database cloning with planned downtime. With the underlying distributed storage engine in Aurora, you’re able to quickly create a copy-on-write clone of your database to minimize costs. For a similar implementation on Aurora MySQL, visit Automate the Amazon Aurora MySQL blue/green deployment process
We welcome your feedback. Share your experience and any questions in the comments.
About the Authors
 Nethravathi Muddarajaiah is a Database Specialist Solutions Architect. She works with AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Nethravathi Muddarajaiah is a Database Specialist Solutions Architect. She works with AWS customers to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
 Maheswaran S is a Solutions Architect based out of Bangalore, India, with a background in large-scale cloud migration and modernisation. He helps ISV customers in India to provide cloud-optimal solutions and mature their SaaS delivery model using AWS products and services. In his free time, he likes long drives, watching movies, and spending time with his family.
Maheswaran S is a Solutions Architect based out of Bangalore, India, with a background in large-scale cloud migration and modernisation. He helps ISV customers in India to provide cloud-optimal solutions and mature their SaaS delivery model using AWS products and services. In his free time, he likes long drives, watching movies, and spending time with his family.
 Abhinav Sarin is a senior partner solutions architect at AWS. His core interests include databases, data analytics, and machine learning. He works with AWS customers and partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.
Abhinav Sarin is a senior partner solutions architect at AWS. His core interests include databases, data analytics, and machine learning. He works with AWS customers and partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions when using AWS.