AWS Database Blog
Understand replication capabilities in Amazon Aurora PostgreSQL
Critical workloads with a global footprint, such as financial, travel, or gaming applications, have strict availability and disaster recovery requirements and may need to tolerate a Region-wide outage. Traditionally, this requires difficult trade-offs between performance, availability, cost, and Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO). In some situations, routine maintenance tasks like database upgrades can become an issue if significant downtime is involved in the upgrade process. In other situations, users may require low latency access to their data regardless of their physical location, with continuous availability despite planned maintenance activities like upgrades.
In this post, you learn about the different replication capabilities offered with Amazon Aurora PostgreSQL-Compatible Edition, which lets your applications be resilient to Region-wide outages and gives you a plan to be always up and running.
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud, which combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases. Database replication involves sharing data so as to ensure consistency between redundant databases to improve reliability, fault tolerance, or accessibility. In this post, we discuss the replication capabilities in Aurora PostgreSQL.
High availability and durability
Aurora is designed to offer greater than 99.99% availability, writing six copies of your data across three Availability Zones and backing up your data continuously to Amazon Simple Storage Service (Amazon S3). It automatically recovers from physical storage failures and instance failures, and the failover process to a read replica in case of an instance failure typically takes less than 30 seconds.
Replication with Aurora
Aurora has several replication options. By default, each Aurora database cluster writes six copies of data across three Availability Zones at the storage level. When you replicate data into or out of an Aurora cluster, you can choose between Aurora features such as Amazon Aurora global database or the native engine-specific replication mechanisms for the MySQL or PostgreSQL database engines. You can choose the appropriate options based on which one provides the right combination of high availability and performance for your needs. The following sections explain how and when to choose each technique.
Replication with Aurora PostgreSQL
When it comes to replication with Aurora PostgreSQL, you have the following options:
- PostgreSQL native logical replication
- PostgreSQL logical replication using the pglogical extension
- Physical replication with Aurora global database
PostgreSQL native logical replication
Logical replication is a method of replicating data objects and their changes based upon their replication identity (usually a primary key). We use the term logical in contrast to physical replication, which uses exact block addresses and byte-by-byte replication. Logical replication uses a publish and subscribe model, with one or more subscribers subscribing to one or more publications on a publisher node. Subscribers pull data from the publications they subscribe to and may subsequently re-publish data to allow cascading replication or more complex configurations. Built-in logical replication was a headline feature of PostgreSQL 10.
Logical replication of a table typically starts with taking a snapshot of the data on the publisher database and copying that to the subscriber. Then the changes on the publisher are sent to the subscriber as they occur in real time. The subscriber applies the data in the same order as the publisher so that transactional consistency is guaranteed.
Use cases for PostgreSQL native logical replication
The following are typical use cases for logical replication:
- Data migration from on-premises or self-managed PostgreSQL environments to Aurora PostgreSQL. For more details, see Migrating PostgreSQL from on-premises or Amazon EC2 to Amazon RDS using logical replication.
- Data replication between two Aurora PostgreSQL database clusters in the same Region, for high availability (HA) and disaster recovery (DR) purposes. In an HA/DR scenario, the target system is an identical copy of the source system. If the source system goes down, the application server needs to be redirected to the target system, which assumes the role of the source system and starts replicating back to the original source now acting as the target.
- Minimum downtime migrations, database upgrades, and application upgrades. You can use AWS Database Migration Service (AWS DMS), which uses PostgreSQL logical replication for near-real-time synchronization of data between two major versions. For more details, see Achieving minimum downtime for major version upgrades in Amazon Aurora for PostgreSQL using AWS DMS.
- Role-based access control, essentially giving different levels of access of subsets of replicated data to different groups of users. For example, application developers, data scientists, database administrators, DevOps users, and business analysts may require different levels of access to different subsets of data for their daily activities. Offloading this access to a secondary database without overwhelming the primary database can be an efficient strategy for most enterprises.
- Replication to big data or a data lake. For example, you could use AWS DMS to replicate transactional data into a data warehouse (Amazon Redshift) or data lake (Amazon S3) for use cases ranging from real-time dashboards, data visualizations to big data processing, real-time analytics, and machine learning.
Limitations
Logical replication currently has the following restrictions. These might be addressed in future releases and subsequently added to Aurora PostgreSQL releases:
- The database schema and Data Definition Language (DDL) commands such as CREATE, ALTER, and DROP aren’t replicated. The initial schema can be copied by hand using
pg_dump --schema-only. Subsequent schema changes need to be kept in sync manually. - Sequence data isn’t replicated. The data in serial or identity columns backed by sequences is of course replicated as part of the table, but the sequence itself still shows the start value on the subscriber. If a failover to the subscriber database is intended, the sequences need to be updated to the latest values, either by copying the current data from the publisher (using
pg_dump) or by determining a sufficiently high value from the tables themselves. - Replication of TRUNCATE commands is supported starting with PostgreSQL 11, but care must be taken when truncating groups of tables connected by foreign keys. When replicating a truncate action, the subscriber truncates the same group of tables that was truncated on the publisher, either explicitly specified or implicitly collected via CASCADE, minus tables that are not part of the subscription. This works correctly if all affected tables are part of the same subscription. But if some tables to be truncated on the subscriber have foreign key links to tables that aren’t part of the same (or any) subscription, the application of the truncate action on the subscriber fails.
- Large objects aren’t replicated. PostgreSQL has two ways for storing Binary Large Objects (BLOBs):
byteatype andOIDtype (large objects).BYTEAtypes or binary strings are very similar to simple character strings, like VARCHAR and text, and are replicated, whereasOIDtypes provide a stream-style access to user data that is stored in a special large object structure. These large objects aren’t replicated. - Replication is only possible from base tables to base tables. That is, the tables on the publication and on the subscription side must be normal tables, not views, materialized views, partition root tables, or foreign tables. In the case of partitions, you can therefore replicate a partition hierarchy one-to-one, but you can’t (as of this writing) replicate to a differently partitioned setup. Attempts to replicate tables other than base tables result in an error.
For more details about replication with Aurora PostgreSQL, see Using PostgreSQL logical replication with Aurora.
PostgreSQL logical replication using the pglogical extension
pglogical is an open-source PostgreSQL extension that helps you replicate data between independent Aurora PostgreSQL databases while maintaining consistent read-write access and a mix of private and common data in each database. pglogical uses logical replication to copy data changes between independent Aurora PostgreSQL databases, optionally resolving conflicts based on standard algorithms.
You can enable pglogical from within your Aurora PostgreSQL instances; it’s fully integrated and requires no triggers or external programs. This alternative to physical and PostgreSQL logical replication is a highly efficient method of replicating data using a publish/subscribe model for selective replication.
pglogical is supported for Aurora PostgreSQL 2.6.x or higher (compatible with PostgreSQL 10.13 or higher), Aurora PostgreSQL 3.3.x or higher (compatible with PostgreSQL 11.8 or higher), Aurora PostgreSQL 4.0 or higher (compatible with PostgreSQL 12.4 or higher) and Aurora PostgreSQL 13.3.
Differences between pglogical extension and native logical replication in PostgreSQL
pglogical has the following differences from built-in logical replication:
- Row filtering on publisher – pglogical allows the publisher database to provide only certain rows by specifying the
row_filterparameter for thereplication_set_add_tablefunction.row_filteris a PostgreSQL expression that has the same limitations on what’s allowed as the ANSI-SQL CHECK constraint. - Column filtering – pglogical also gives you the flexibility to replicate only some columns in a table using an optional argument
columnswith thereplication_set_add_tablefunction. - Conflict detection and resolution – PostgreSQL native logical replication can’t detect conflicts of data either coming from multiple publishers or when replicated changes conflict with data that was changed locally. Therefore, an UPDATE is always applied and INSERT always fails if there is an existing row with the same key. pglogical detects these conflicts and has a configurable resolution. You can choose if the remote row should be used or if the local one should stay and remote change should be discarded. You can also stop replication on the conflict (and fix the data manually), or let pglogical decide which row to pick based on the timestamp of the transaction that has made the change. pglogical can also convert the INSERT operation into UPDATE in case of conflicting keys. For the full list of available techniques, see Conflicts.
- Version support (cross-version replication and online upgrades) – If you want to migrate or upgrade your PostgreSQL database from on premises to AWS-managed PostgreSQL or upgrade to a major version of PostgreSQL within AWS-managed services, you can do so through any native PostgreSQL feature by using logical replication. Although you can replicate data from Aurora 2.4+ (compatible with PostgreSQL 10.11+) to Aurora 4.0+ (compatible with PostgreSQL 12.4+) all the way up to Aurora PostgreSQL 13.3 using built-in logical replication, pglogical supports any version of PostgreSQL since 9.4. For any previous versions of PostgreSQL prior to 10.11, it can provide an easy and convenient way to do online upgrades or replication in cross-version replication environments. For more details, see Migrating PostgreSQL from on-premises or Amazon EC2 to Amazon RDS using logical replication.
- Sequence replication – With pglogical, you can add sequences to replication just like you add tables.
- Delayed replication – With pglogical, you can use the parameter
apply_delaytocreate_subscriptionto delay replication by a given interval. This could be especially useful in scenarios where you need to recover data after accidental deletion. For example, you can pause archive recovery on a delayed replica instance to eliminate the risk of the replica replaying a DELETE operation. - Table schema and DDL – You can copy the initial schema of a database to another database using pglogical. Also, pglogical provides the replicate_ddl_command function to ensure that DDL statements are replicated to the subscribers at the appropriate places in the replication stream (so that the DDLs replicated don’t break the replication).
Use cases for replication with pglogical extension
The following are typical use cases for pglogical:
- Migrate from on-premises or self-managed PostgreSQL environments into Amazon RDS for PostgreSQL or Aurora PostgreSQL
- Upgrades between Aurora PostgreSQL major versions
- Full database replication
- Migrate from older versions of PostgreSQL, either on premises or Amazon Elastic Compute Cloud (Amazon EC2) into Amazon RDS for PostgreSQL or Aurora PostgreSQL
- Selective replication of sets of tables using replication sets
- Selective replication of table rows at either the publisher or subscriber side (
row_filter) - Selective replication of table columns at the publisher side
- Bidirectional replication with conflict detection and resolution between two RDS for PostgreSQL or Aurora PostgreSQL instances
Limitations of replication with pglogical extension
- The UNLOGGED and TEMPORARY tables aren’t replicated, much like with physical replication. This is because the changes to these tables don’t have entries in the transaction logs (Write-Ahead Logs), and it’s impossible for the logical worker process to capture the changes happening on these tables.
- pglogical as well as native logical replication work on a per-database basis. This means that when you replicate more than one database, you must set up individual provider and subscriber relationships for each database using the
pglogical.create_nodeandpglogical.create_subscriptionSQL commands. As of PostgreSQL 12, you can’t configure replication for all databases in a PostgreSQL cluster all at once. - You can’t replicate
UPDATEandDELETEfunctions for tables that lack a primary key or other valid replica identity, such as aUNIQUEpglogical needs a primary key or unique key on the tables to capture the changes. - With the current logical replication technology for PostgreSQL, we have excellent ways to replicate DML events (
INSERT,UPDATE,DELETE), but are left to figure out propagating DDL changes on our own. That is, when we create new tables, alter tables, and so on, we have to manage this separately in our application deployment process in order to make those same changes on logical replicas, and add such tables to replication. As of Postgres 12, there is no way to do transparent DDL replication to other PostgreSQL clusters alongside any logical replication technology built on standard PostgreSQL.
Aurora global database
Aurora global database is designed for globally distributed applications, allowing a single Aurora database to span up to 5 secondary Regions with up to 90 Aurora replicas. It physically replicates your data with no impact on database performance, enables fast local reads with low latency in each Region, and provides managed planned failover and manual unplanned failover from Region-wide outages. The following diagram illustrates this architecture.
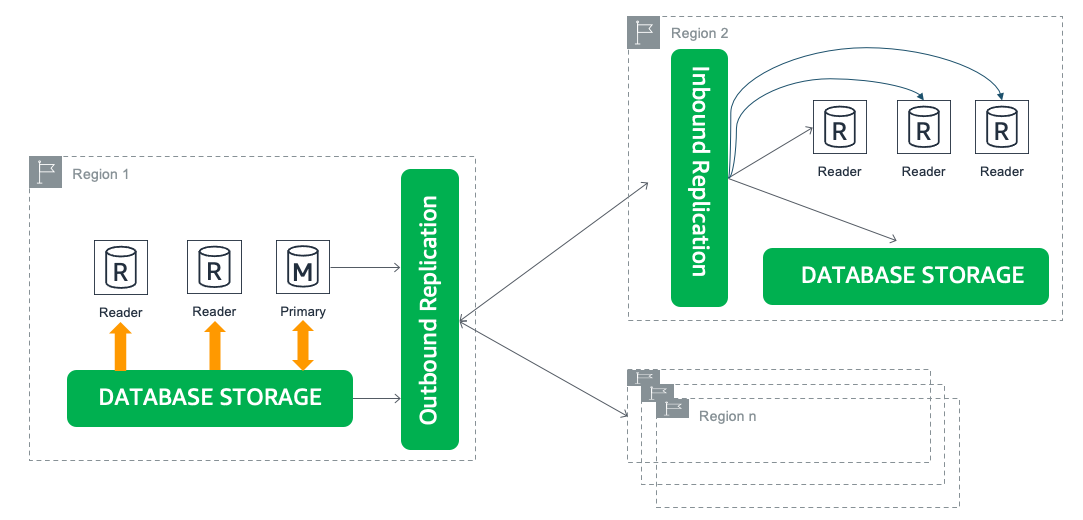
Use cases for Aurora global database
The following are typical use cases for Aurora global database:
- Global reads with local latency – Enterprises with locations around the world can use an Aurora global database to keep databases in sync across the globe. Office locations in local Regions can access the information in their own AWS Region, with minimal latency.
- Scalable secondary Aurora database clusters – You can scale your secondary clusters by adding up to 90 Aurora replicas and up to 5 secondary Regions.
- Disaster recovery from Region-wide outages – The secondary clusters enable fast failover for disaster recovery. You can promote a secondary cluster and make it available for writes in under a minute. For more details, see Cross-Region disaster recovery using Amazon Aurora global database for Amazon Aurora PostgreSQL.
Limitations of Aurora global database
Refer to the AWS documentation to see what is and what isn’t currently supported for Aurora global databases: Limitations of Amazon Aurora global databases.
Conclusion
This post covered the various replication capabilities currently available in Amazon Aurora PostgreSQL-Compatible Edition. To recap, we looked at PostgreSQL native logical replication provides a flexible and simple means to replicate your tables to a subscriber database. It also helps you scale your read and write workloads and provides increased availability for your database clusters. PostgreSQL logical replication using the pglogical extension builds on native logical replication and adds more flexibility to do selective replication with conflict detection and resolution. Amazon Aurora global database enables fast local reads with low latency in each Region, provides up to 5 secondary Regions and up to 90 Aurora replicas. Due to its storage based physical replication architecture, Aurora global database provides the lowest replica lag in comparison to the logical replication options and provides managed planned failover and manual unplanned failover from Region-wide outages for your Aurora PostgreSQL-Compatible Edition databases.
In summary, Amazon Aurora provides several options that allow you to use the most appropriate replication method based on your business use case.
Leave any thoughts or questions in the comments section.
About the Author
 Shayon Sanyal is a Sr. Solutions Architect specializing in databases at AWS. His day job allows him to help AWS customers design scalable, secure, performant and robust database architectures on the cloud. Outside work, you can find him hiking, traveling or training for the next half-marathon.
Shayon Sanyal is a Sr. Solutions Architect specializing in databases at AWS. His day job allows him to help AWS customers design scalable, secure, performant and robust database architectures on the cloud. Outside work, you can find him hiking, traveling or training for the next half-marathon.