AWS Database Blog
Cross-Region disaster recovery using Amazon Aurora Global Database for Amazon Aurora PostgreSQL
Critical workloads with a global footprint have strict availability requirements and may need to tolerate a Region-wide outage. Traditionally, this required a difficult trade-off between performance, availability, cost, and data integrity, and sometimes required a considerable re-engineering effort. Due to high implementation and infrastructure costs that are involved, some businesses are compelled to tier their applications, so that only the most critical ones are well protected.
Amazon Aurora Global Database is designed to keep pace with customer and business requirements for globally distributed applications. This allows Amazon Aurora to span multiple AWS Regions and provide the following:
- A disaster recovery solution that can handle a full Regional failure with a low recovery point objective (RPO) and a low recovery time objective (RTO), while minimizing performance impact to the database cluster being protected
- Fast local reads with read-only copies in the secondary Regions to serve users close to those Regions rather than having to connect to the Aurora cluster in a primary Region
- Cross-Region migration from a primary Region to the secondary Region by promoting the Aurora cluster in the secondary Region within a minute
Recovery time objective (RTO) is the maximum acceptable delay between the interruption of service and restoration of service. This determines what is considered an acceptable time window when service is unavailable. Recovery point objective (RPO) is the maximum acceptable amount of time since the last data recovery point. This determines what is considered an acceptable loss of data between the last recovery point and the interruption of service. For example, an RPO of 1 hour means that you could lose up to 1 hour’s worth of data when a disaster occurs.
This post shows how to set up cross-Region disaster recovery (DR) for Amazon Aurora PostgreSQL-Compatible Edition using an Aurora global database spanning multiple Regions. Aurora Global Database uses global storage-based replication, where the newly promoted cluster as primary cluster can take full read and write workloads in under a minute, which minimizes the impact on application uptime.
Solution overview
Aurora is a relational database that was designed to take full advantage of the abundance of networking, processing, and storage resources available in the cloud. While maintaining compatibility with MySQL and PostgreSQL on the user-visible side, Aurora makes use of a modern, purpose-built distributed storage system. For details on the Aurora purpose-built distributed storage system, see Introducing the Aurora Storage Engine.
Aurora Global Database is created with a primary Aurora cluster in one Region and a secondary Aurora cluster in a different Region. Aurora Global Database uses the dedicated infrastructure in the Aurora purpose-built storage layer to handle replication across Regions. Dedicated replication servers in the storage layer handle the replication, which allows you to meet enhanced recovery and availability objectives without compromising database performance even during load on the system. Aurora Global Database uses physical storage-level replication to create a replica of the primary database with an identical dataset, which removes any dependency on the logical replication process.
The following diagram shows an Aurora global database with an Aurora cluster spanning primary and secondary Regions.

The process includes the following steps:
- The primary instance of an Aurora cluster sends log records in parallel to storage nodes, replica instances, and replication server in the primary Region.
- The replication server in a primary Region streams log records to the replication agent in the secondary Region.
- The replication agent sends log records in parallel to storage nodes and replica instances in the secondary Region.
- The replication server in a primary Region pulls log records from storage nodes to catch up after outages.
The Aurora storage system automatically maintains six copies of your data across three Availability Zones within a single Region, and automatically attempts to recover your database in a healthy Availability Zone with no data loss, which significantly improves durability and availability. Write quorum requires an acknowledgement from four of the six copies, and the read quorum is any three out of six members in a protection group. Data is continuously backed up to Amazon Simple Storage Service (Amazon S3) with Aurora in real time, with no performance impact to the end user.
The following diagram shows an Aurora global database with physical storage-level outbound replication from a primary Region to multiple secondary Regions.

We can configure up to five secondary Regions and up to 16 read replicas in each secondary Region with Aurora Global Database. Each secondary cluster must be in a different Region than the primary cluster and any other secondary clusters.
With an Aurora global database, you can choose from two different approaches to failover:
- Managed planned failover – To relocate your primary DB cluster to one of the secondary Regions in your Aurora global database, see Managed planned failovers with Amazon Aurora Global Database. With this feature, RPO is 0 (no data loss) and it synchronizes secondary DB clusters with the primary before making any other changes. RTO for this automated process is typically less than that of the manual failover.
- Manual unplanned failover – To recover from an unplanned outage, you can manually perform a cross-Region failover to one of the secondaries in your Aurora global database. The RTO for this manual process depends on how quickly you can manually recover an Aurora global database from an unplanned outage. The RPO is typically measured in seconds, but this depends on the Aurora storage replication lag across the network at the time of the failure.
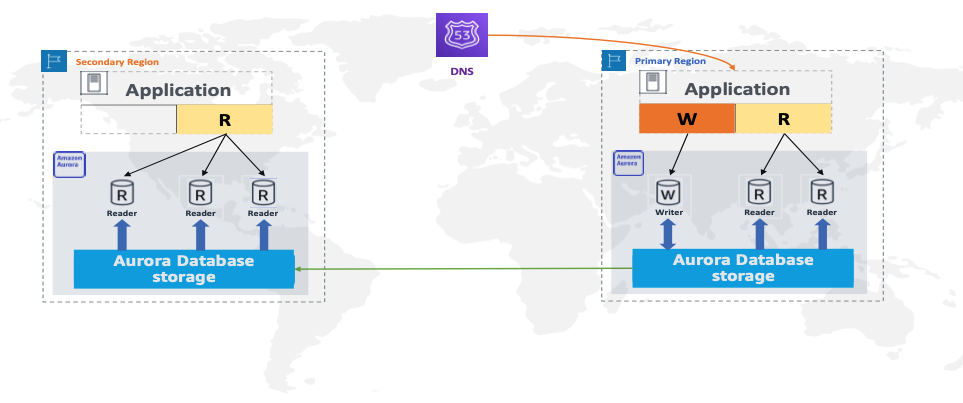
The following diagram with an Aurora global database for Aurora PostgreSQL shows two main components:*
- An application connected to an Aurora cluster in a primary Region, which performs reads and writes from the writer instance and only reads from read replicas.
- Applications connected to an Aurora cluster in a secondary Region, which perform only reads from read replicas.

Amazon Route 53 friendly DNS names (CNAME records) are created to point to the different and changing Aurora reader and writer endpoints, to minimize the amount of manual work you have to undertake to re-link your applications due to failover and reconfiguration. For more information, see Opening connections to an Amazon RDS database instance using your domain name.
In the unlikely scenario that an entire Region’s infrastructure or service becomes unavailable at the primary Region, causing a potential degradation or isolation of your database during unplanned outages, you can manually initiate the failover by promoting a secondary cluster to become a primary, or can script the failover understanding the potential data loss, which is quantified by the RPO.
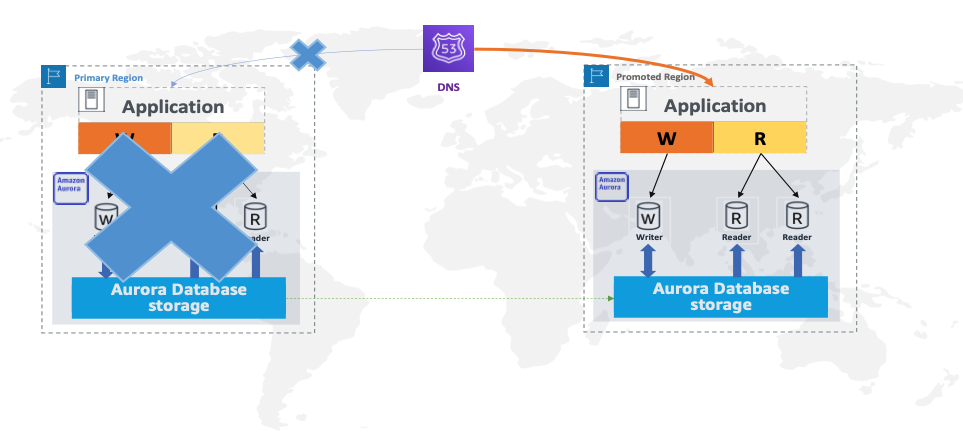
Upon completion of failover, this promoted Region (the old secondary Region) acts as the new primary Aurora cluster and can take full read and write workloads in under a minute, which minimizes the impact on application uptime. When the old primary Region’s infrastructure or service becomes available, adding a Region allows it to act as new secondary Aurora cluster, taking only read workloads from applications during unplanned outages. As of this writing, Aurora Global Database doesn’t provide a managed unplanned failover feature.
To deploy this solution, we set up Aurora Global Database for an Aurora cluster with PostgreSQL compatibility. You can create an Aurora global database from the AWS Management Console, AWS Command Line Interface (AWS CLI), or by running the CreateGlobalCluster action from the AWS CLI or SDK.
Prerequisites
Before you get started, make sure you complete the following prerequisites:
- Choose a primary Region and secondary Region to deploy Aurora Global Database to serve your applications with low latency and disaster recovery purpose.
- Confirm compatibility for Aurora Global Database for Aurora with PostgreSQL. Compatibility is available for versions 10.14 (and later), 11.9 (and later), and 12.4 (and later).
- Create a read/write Aurora PostgreSQL database in your primary Region. To create an Aurora PostgreSQL database using an AWS CloudFormation template, see Deploy an Amazon Aurora PostgreSQL DB cluster with recommended best practices using AWS CloudFormation.
Create an Aurora global database for a pre-existing Aurora PostgreSQL cluster
For this post, we use a pre-existing Aurora PostgreSQL cluster in our primary Region. To create an Aurora global database, complete following steps:
- On the Amazon RDS console, choose Databases.
- Choose your source cluster. This post chooses
sourceclusterin theus-east-1Region. - On the Actions drop-down menu, choose Add region.

- On the Add a region page, for Global database identifier, enter a name for your global database; for example,
globalcluster.
This is the name of the global cluster that contains both the writer and reader Regions.
- For secondary Region, choose your target Region. This post chooses US West (Oregon).

- For the remaining settings on this page, use the same settings that you use to create an Aurora DB cluster.

When the global cluster creation is complete, the view on the console looks similar to the following screenshot.

At this point, both the writer and reader clusters are online and ready to accept traffic.
Monitor an Aurora global database for Aurora PostgreSQL cluster
To monitor your database, complete the following steps:
- Connect to the Aurora global database primary cluster endpoint in the writer Region using psql or pgadmin.
- Use the
aurora_global_db_statusfunction to see lag times of the global database secondary DB clusters:
The output includes a row for each DB cluster of the global database with the following columns:
- aws_region – The Region that this DB cluster is in. For tables listing Regions by engine, see Regions and Availability Zones.
- highest_lsn_written – The highest log sequence number (LSN) currently written on this DB cluster.
- durability_lag_in_msec – The timestamp difference between the highest LSN written on a secondary DB cluster (
highest_lsn_written) and thehighest_lsn_writtenon the primary DB cluster. - rpo_lag_in_msec – The RPO lag. This lag is the time difference between the most recent user transaction commit stored on a secondary DB cluster and the most recent user transaction commit stored on the primary DB cluster.
- last_lag_calculation_time – The timestamp when values were last calculated for
replication_lag_in_msecandrpo_lag_in_msec. - feedback_epoch – The epoch the secondary DB cluster uses when it generates hot standby information.
- feedback_xmin – The minimum (oldest) active transaction ID used by the secondary DB cluster.
- Use the
aurora_global_db_instance_statusfunction to list all secondary DB instances for both the primary DB cluster and secondary DB clusters:
The output includes a row for each DB instance of the global database with the following columns:
- server_id – The server identifier for the DB instance
- session_id – A unique identifier for the current session
- aws_region – The Region that this DB instance is in
- durable_lsn – The LSN made durable in storage
- highest_lsn_rcvd – The highest LSN received by the DB instance from the writer DB instance
- feedback_epoch – The epoch the DB instance uses when it generates hot standby information
- feedback_xmin – The minimum (oldest) active transaction ID used by the DB instance
- oldest_read_view_lsn – The oldest LSN used by the DB instance to read from storage
- visibility_lag_in_msec – How far this DB instance is lagging behind the writer DB instance
Aurora exposes a variety of Amazon CloudWatch metrics, which you can use to monitor and determine the health and performance of your Aurora global database with PostgreSQL compatibility. For more information, see Monitoring Amazon Aurora metrics with Amazon CloudWatch.
- On the Amazon Relational Database Service (Amazon RDS) console from secondary Region, select the secondary DB cluster (
targetclusterin this post).
On the Monitoring tab, you can view the following key metrics relevant to global clusters, and secondary DB clusters more specifically:
- AuroraGlobalDBReplicatedWriteIO – The number of write I/O replicated to the secondary Region
- AuroraGlobalDBDataTransferBytes – The amount of redo logs transferred to the secondary Region, in bytes
- AuroraGlobalDBReplicationLag – How far behind, measured in milliseconds, the secondary Region lags behind the writer in the primary Region
The following screenshot shows the console view of the metrics.

You can use the CloudWatch dashboard on the CloudWatch console to monitor for the latency, replicated I/O, and the cross-Region replication data transfer for Aurora Global Database.
Test DDL and DML for Aurora Global Database with Aurora PostgreSQL
To test DDL and DML for your global database, complete the following steps:
- Connect to the global database primary Aurora PostgreSQL cluster writer endpoint in the primary Region (
sourceclusterin this post). - Create a sample table and data, and perform DML with the following code to test replication across Regions:
- Connect to the global database secondary Aurora PostgreSQL cluster reader endpoint in the secondary Region (
targetclusterin this post). - Query the data using the following code:
Manage recovery for Aurora global databases with Aurora PostgreSQL
The recovery point objective (RPO) is the acceptable amount of lost data (measured in time) that your business can tolerate in the event of a disaster. You can use a managed RPO to control the maximum amount of data loss as the secondary DB clusters in secondary Region lag behind the primary DB cluster after a failover, in case of disasters such as network or hardware failures that affect the primary DB cluster. This data loss is measured in time, and is called the RPO lag time. When you set the RPO, Aurora PostgreSQL enforces it on your global database as follows:
- Allows transactions to commit on the primary DB cluster if the RPO lag time of at least one secondary DB cluster is less than the RPO time.
- Blocks transaction commits if no secondary DB cluster has an RPO lag time less than the RPO time. If Aurora PostgreSQL starts blocking commits, it inserts an event into the PostgreSQL log file. It then emits wait events that show the sessions that are blocked.
- Allows transactions to commit again on the primary DB cluster as soon as the RPO lag time of at least one secondary DB cluster becomes less than the RPO time.
RPO settings
A good practice is to use the Aurora parameter group of the primary cluster and secondary cluster of an Aurora global database with the same settings. This way, in the event of a failure of the primary Region, the new primary cluster in the secondary Region has the same configuration as the old primary.
- On the Amazon RDS console, identify the primary DB cluster’s parameter group of the global database.
- Open the primary DB cluster parameter group and set the
global_db_rpoparameter.
For instructions, see Modifying parameters in a DB cluster parameter group.
- Set the
global_db_rpoparameter value to the number of seconds you want for the recover point objective.
Valid values start from 20 seconds.

This approach ensures that Aurora PostgreSQL doesn’t allow transaction commits to complete that would result in a violation of your chosen RPO time.
Failover for Aurora global databases for Aurora PostgreSQL
Your Aurora global database might include more than one secondary Region, and you can choose which Region to fail over to if an outage affects the primary Region. Monitor the replication lag for all your secondary Regions to determine which secondary Region to choose. Choosing the secondary cluster with the least replication lag means the least data loss.
If an entire cluster in one Region becomes unavailable, you can promote another secondary Aurora PostgreSQL cluster in the global database to have read and write capability. You can manually activate the failover mechanism if a cluster in a different Region is a better choice to be the primary cluster.
Promote the secondary Aurora PostgreSQL cluster
To promote the secondary Aurora PostgreSQL cluster in the secondary Region to an independent DB cluster, complete the following steps:
- On the Amazon RDS console, navigate to the Aurora PostgreSQL cluster details page of the secondary DB cluster in the secondary Region.
- Select the secondary DB cluster (for this post,
targetcluster). - On the Actions menu, choose Remove from Global.

A message appears to confirm that this will break replication from the primary DB cluster.
- Choose Remove and promote.

In this post, targetcluster in us-west-2 is promoted to a standalone cluster.
The promotion process should take less than 1 minute. When it’s complete, you should see the old secondary DB cluster and the DB instance is now a writer node.

Your application write workload should now point to the cluster writer endpoint of the newly promoted Aurora PostgreSQL cluster, targetcluster.
Summary
This post covered how to implement cross-Region disaster recovery for an Aurora cluster with PostgreSQL compatibility using Aurora Global Database. This allows you to create globally distributed applications and maintain a disaster recovery solution with minimal RPO and RTO for the failure of an entire Region, and can provide low-latency reads to Regions across the world. Get started with Amazon Aurora Global Database today! We welcome your feedback. Please share your experience and any questions in the comments.
About the Author
 Nethravathi Muddarajaiah is a Senior Partner Database Specialist Solutions Architect at AWS. She works with AWS Technology and Consulting partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions.
Nethravathi Muddarajaiah is a Senior Partner Database Specialist Solutions Architect at AWS. She works with AWS Technology and Consulting partners to provide guidance and technical assistance on database projects, helping them improve the value of their solutions.