AWS Database Blog
Choose shard keys to optimize Amazon DocumentDB Elastic Clusters
As applications grow, data grows as well, so it’s imperative for a modern cloud-based application to have a database that can automatically scale. Amazon DocumentDB (with MongoDB compatibility) is a fully managed, native JSON database built with a flexible schema for enterprise applications that decouples storage and compute, improving scalability and reducing time-consuming administrative tasks. Amazon DocumentDB Elastic Clusters allows your document database to scale to millions of reads and writes per second, with little to no downtime or performance impact. This removes the need for developers to choose, manage, or upgrade instances for Amazon DocumentDB.
In this post, we introduce the Elastic Clusters feature and best practices around shard key selection, ensuring optimal performance as your data scales out. Elastic Clusters go beyond the architectural boundaries of Amazon DocumentDB by enabling automated horizontal scaling.
Benefits of Amazon DocumentDB Elastic Clusters
Elastic Clusters are designed to scale with your needs as your workloads evolve, and store petabytes of data in an easy and cost-effective way. Costs are predictable—you pay only for what you consume, without managing the underlying infrastructure. Most importantly, scaling can handle millions of reads and writes per second.
Elastic Clusters have the following benefits:
- Fast and scalable – You can scale to millions of reads and writes per second with petabytes of storage capacity. I/O auto scales, removing the management around provisioning for more networking.
- Fully managed – Built-in high availability deploys each shard of the Elastic Cluster across multiple Availability Zones for redundancy. Automatic patching, durability, and security best practices are built in by default, reducing administrative overhead.
Sharding with Amazon DocumentDB Elastic Clusters
Elastic Clusters use hash-based sharding to partition data across distributed storage. With hashed sharding, Elastic Clusters provide a more even data distribution across the partitioned cluster. Sharding splits large datasets into small datasets that are spread across multiple nodes, enabling horizontal scaling. Each shard has its own compute capacity, writer, and storage partition. Elastic Clusters copy data efficiently between distributed storage systems rather than re-partitioning collections by moving small chunks of data between compute nodes. The shards are organized based on a shard key, a single field hashed index used to partition data across the cluster.
The shard key is a field in the JSON document that Elastic Clusters use to distribute read and write traffic to matching shards—it tells the system how you want to partition the data. The field selected can directly impact performance of the clusters, so it’s important to understand your dataset and the best practices around shard keys before deploying. You don’t want to have one of the shards with too much data—this leads to uneven data distribution. Hot shards are a direct result of uneven distribution, with one node taking the majority of the activity.
Best practices around selecting shard keys
When selecting shard key, it’s important to choose a field with a high cardinality. The most optimal selection would be a field that has a high number of unique values. Keys with high cardinality could be ID numbers, user names, or email addresses, allowing for even distribution of the data across shards. Uneven data distribution could lead to heavy processing for one of the shards, impacting service performance.
It’s also imperative to think about query frequency and usage patterns. Forethought into the query load while selecting a shard key ensures the distribution of queries will be even across the dataset, reducing latency and increasing performance.
Example use case
In the following sample dataset, for customer data, customer_id was selected as the shard key due to its uniqueness across fields. The high cardinality field allows for more effective distribution of the processing of both reads and writes. Conversely, if the shard key field has low cardinality, the processing of the data could overload one shard.

When more data is added, Elastic Clusters use hash sharding to redistribute the data across the available shards. The redistribution is self-managed, eliminating any manual maintenance. As additional data is inserted into the table, there is an automated rebalancing to ensure the data is distributed evenly. The following diagram illustrates the redistribution of data across the available shards.
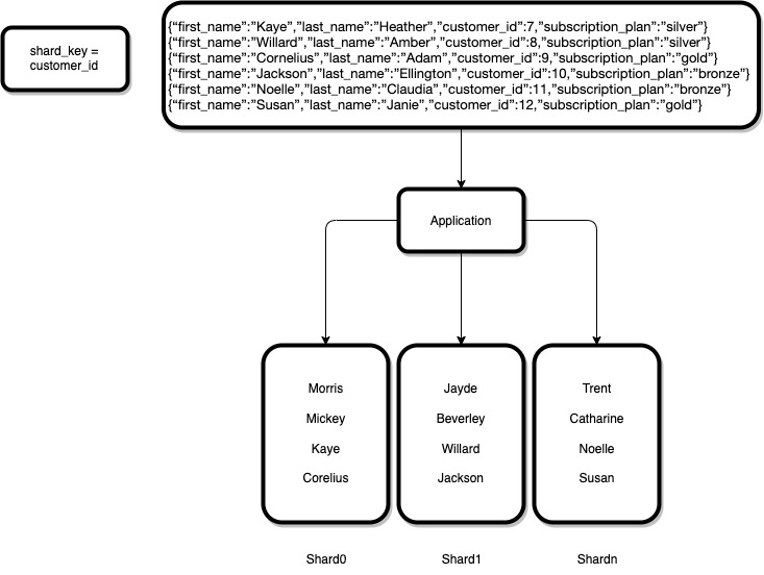
As more shards are added to the cluster, the dataset continues to distribute the data by shard key across the partitions, allowing for even processing of reads and writes. Elastic Clusters handle the redistribution of the dataset in the event that the number of nodes in the cluster is increased, decreased, or deleted.
Conclusion
Amazon DocumentDB Elastic Clusters offers a new scalable way to partition data in a fully managed service. As modern cloud-based applications continue to increase, so does the need for a service that can self-manage the data storage and processing for even the most demanding applications. With simple analysis into the application’s data usage and query patterns, following the shard key selection best practices will provide a launching point for Elastic Clusters to scale for any future growth.
If you have any comments or questions, leave them in the comments section.
About the Author
 Jason D’Alba is an AWS Solutions Architect leader focused on databases and enterprise applications, helping customers architect highly available and scalable solutions.
Jason D’Alba is an AWS Solutions Architect leader focused on databases and enterprise applications, helping customers architect highly available and scalable solutions.