AWS Database Blog
Everything you don’t need to know about Amazon Aurora DSQL: Part 2 – Shallow view
I started this blog post series with an overview of foundational database concepts and how they apply to Amazon Aurora DSQL.
In this second post, I examine Aurora DSQL’s architecture and explain how its design decisions impact functionality—such as optimistic locking and PostgreSQL feature support—so you can assess compatibility with your applications. I provide a comprehensive overview of the underlying architecture, which is fully abstracted from the user. By interacting solely with the Regional endpoint, users gain direct access to the service’s capabilities. I firmly believe that understanding the service’s architecture empowers you to strategically use its full potential.
Service overview
Aurora DSQL is a modern, serverless, distributed SQL database designed specifically for online transaction processing (OLTP) workloads. Built with PostgreSQL compatibility in mind, with a subset of its features, it employs an active-active deployment model where all database resources function as peers capable of handling both read and write traffic, both within a Region and across Regions. The service adopts a pay-per-use pricing model that charges customers based on their actual resource consumption and data storage requirements.
The service provides zero data loss for both single and multi-Region clusters due to its synchronous data replication system, providing strong read-after-write consistency for reads.
The following diagrams show the high-level overview of Aurora DSQL infrastructure, demonstrating scalability for single-Region (left) and multi-Region (right) synchronized clusters with witness Region.
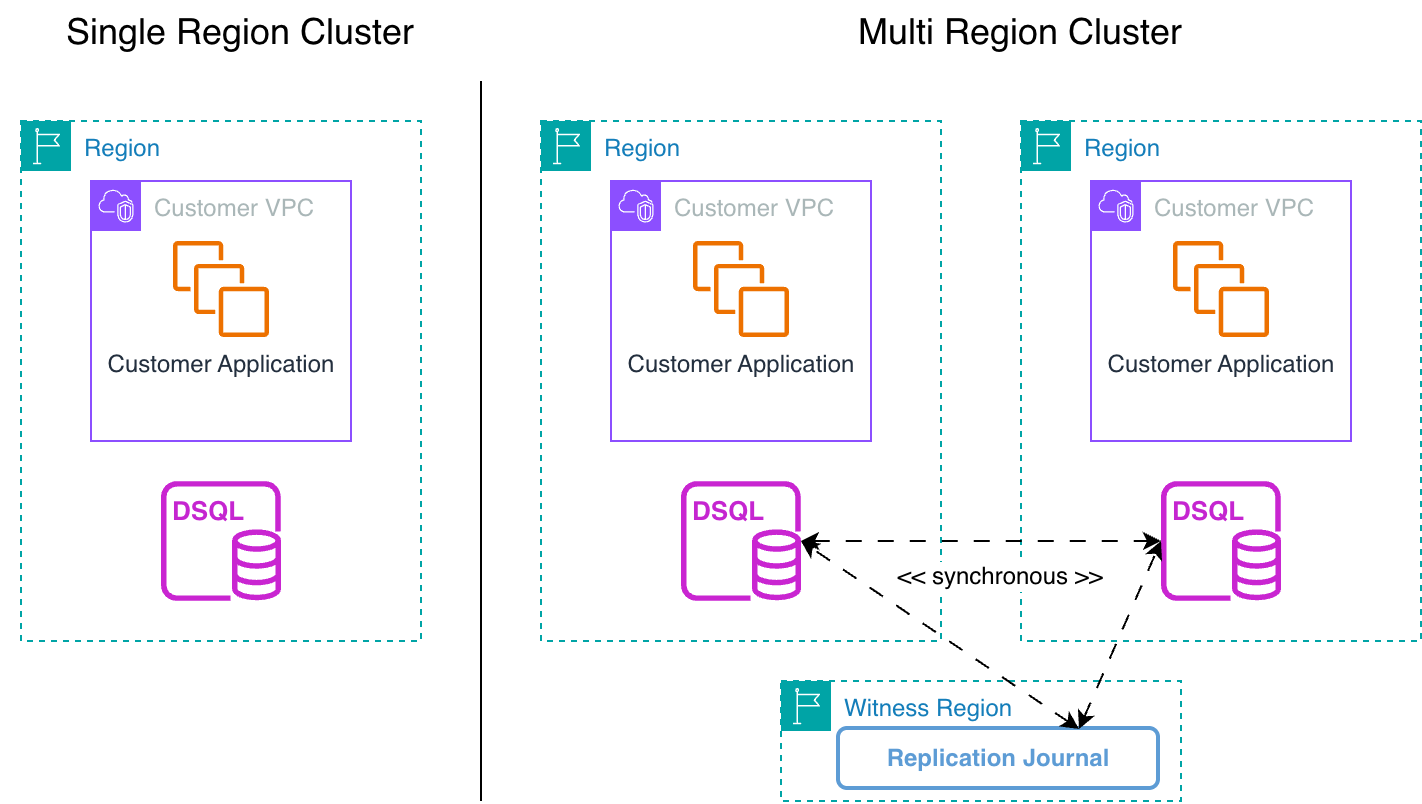
The architecture in a single Region consists of a multi-tier processing model with compute, transaction log, and storage layers spread across three Availability Zones for local high availability. It provides application access through a dedicated endpoint.
The multi-Region clusters consist of two synchronized Regions, each mirroring the infrastructure of the single-Region setup, and a third region called the witness Region. The witness Region’s function is to participate in transaction quorum and to be a tiebreaker in the case of network partition.
The service provides 99.99% availability when deployed in a single Region and you achieve even higher availability (99.999%) with the multi-Region cluster configuration. To benefit from this enhanced level of reliability, it’s not enough to simply have your service running in multiple Regions – your application must be designed to automatically switch between Regions when needed. This means if one Region experiences problems, your application should be able to connect to another working Region. It’s like having backup power systems – the true benefit comes not only from having multiple backup sources, but from your ability to switch to whichever one is working properly. This design approach protects against correlated failures, where one Region’s issues won’t bring down your entire service if your application can successfully connect to the remaining operational Region.
Read operations in Aurora DSQL are serviced in the Region of origin, eliminating cross-Region latency entirely. Writes, on the other hand, incur cross-Region latency solely at the commit time. On the operational front, Aurora DSQL presents several advantages that simplify database management and enhance scalability. The service’s architecture facilitates independent scaling of components, encompassing compute, commit, and storage layers. This facilitates precise resource allocation based on workload demands, which is executed behind the scenes and fully managed by AWS, rendering it a truly serverless service. Consequently, it eliminates the necessity for maintenance windows, thereby reducing operational overhead and improving system availability.
Aurora DSQL is deeply integrated with other AWS services, facilitating interaction with services such as AWS Identity and Access Management (IAM) for access control and AWS CloudTrail for audit logging.
Aurora DSQL architecture
Aurora DSQL is a new distributed database system that takes advantage of numerous Amazon innovations, such as the Firecracker virtualization. DSQL’s design reduces complexity by reimagining single-instance database components, such as compute and storage, as loosely coupled multi-tenant fleets able to focus on specific tasks with well-defined contracts to ensure coordination. Each component makes design decisions that are most optimal for its domain. This aligns with three fundamental properties:
- Each component independently makes changes and improvements
- Components scale individually
- Different security isolation decisions are made for each component
Here are the most important components of Amazon Aurora DSQL: Query processors (QPs) act as a dedicated PostgreSQL engine for each connection and handle most of the SQL processing locally, returning data in response to reads and spooling written data until the transaction commits. Adjudicators determine whether a read-write transaction commits or not and will communicate with other adjudicators to ensure isolation. Journals are an ordered data stream that make committed transactions durable and replicate data between availability zones, and in a multi-Region cluster also across Regions. The Crossbar merges data streams from journals and routes them to storage. Storage nodes provide access to the data and stores data based on a shard key. They also contain multiple read replicas of data.
The following diagram distinctly shows write paths (solid lines) and read paths (dotted lines), emphasizing the system’s ability to optimize for different access patterns.
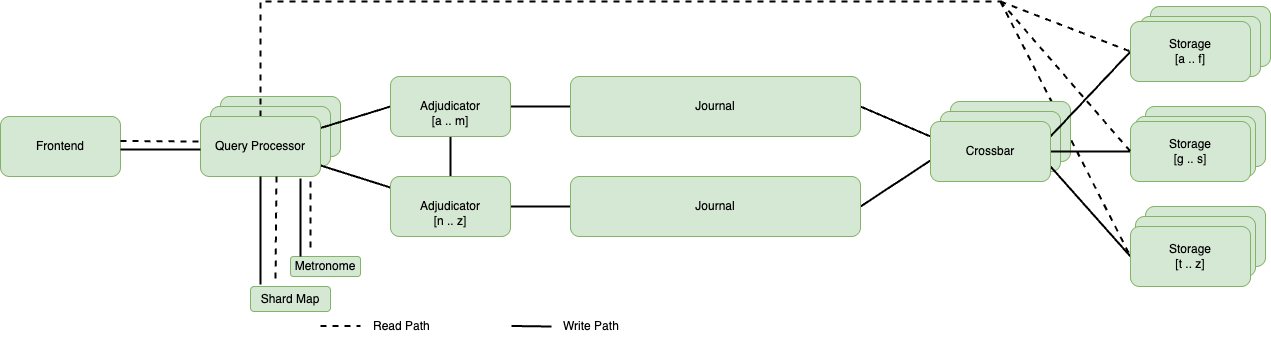
System architecture diagram illustrating data processing workflow within Amazon Aurora DSQL
The frontend acts as transaction and session router, routing each connection to its own Query Processor. The QP is responsible for executing SQL queries and returning the corresponding data in response to reads, coordinating with a metronome (a timing component) to provide consistent processing through time-based isolation and coordination. The QP consults a local shard map to determine which keys are placed where on storage (for reads) and adjudicator (for committing read-write transactions). It also buffers data in response to writes and manages the transaction protocol. Transactions in Amazon Aurora DSQL have a maximum lifetime of 300 seconds (hard limit), and transactions that exceed this duration are rejected. Notably, QPs never communicate with other QPs, and they request rows, not disk pages. Amazon Aurora DSQL also pushes predicates down to storage for performance enhancement and to reduce data communicated back to the QPs. This means that a significant portion of the heavy lifting, including filtering, aggregation, and projection, is performed on the storage layer. Each transaction receives its own QP, enabling scaling horizontally and ensuring each transaction gets its own compute resource neither affecting nor being affected by other transactions. The compute stack within Aurora DSQL consists solely of the QP.
At commit time, the QP submits the transaction to adjudicators, who execute the optimistic concurrency control protocol. Adjudicators are assigned specific key ranges and coordinate with peers for transactions affecting multiple key sets. They determine if a transaction can commit within their shard, collaborating when necessary. In multi-Region clusters, adjudicators detect conflicting writes across all Regions. This approach uses optimistic concurrency control, allowing transactions to proceed without acquiring locks until the validation phase. It manages simultaneous operations while maintaining data consistency across distributed systems. By checking for conflicts at the end of transactions, this method prevents issues like dirty reads and lost updates, making it particularly suitable for scenarios where conflicts are rare.
Journals are ordered data streams that make committed transactions durable, which will acknowledge the write back to the client. The commit stack within Amazon Aurora DSQL is composed of the adjudicators and journals, with each journal being exclusively associated with a single adjudicator.
Crossbars merge the journal streams in chronological order (in contrast to the journal storing commits in transaction order) and publish writes to storage.
Storage consists of multiple storage nodes with data distributed across the nodes by range-partitioning based on primary key. Storage nodes exist to serve reads and are not responsible for short-term durability. Storage may create additional read replicas of nodes to serve higher volumes of reads to keys on the nodes.
Overview of Aurora DSQL benefits based on the architecture
The following is an overview of the benefits (not an extensive list) you obtain through this distributed architecture:
- Aurora DSQL provides atomicity, consistency, isolation, and durability (ACID) transactions with strong consistency with synchronous data replication, snapshot isolation, atomicity, and cross-AZ and cross-Region durability.
- Aurora DSQL implements snapshot isolation and a lock-free concurrency control. One major benefit of this approach is that read-only transactions do not incur cross-AZ or cross-Region latency while maintaining strong consistency.
- Write-transactions incur two round-trip times (RTTs) of cross-Region latency at commit time. The latency occurs per transaction, not per statement, so it doesn’t matter how many statements there are.
- Anything that happens before commit occurs locally at the QP, which means that slow clients don’t slow down others because each connection gets its own dedicated QP resource.
- Each component within Aurora DSQL is designed for the individual task it receives, which allows it to scale individually and be sharded individually, and the database easily adapts to different read-write, compute-read, and compute-write ratios dynamically
- The components are deployed independently and are distributed over multiple stateless hosts. The service takes care of moving them from host to host when needed, which doesn’t impact the customer and doesn’t require a maintenance window.
Considerations when using Aurora DSQL
Aurora DSQL is a PostgreSQL-compatible distributed database that offers virtually unlimited scale and high availability. While it is PostgreSQL-compatible, Aurora DSQL does not offer every feature that is available in PostgreSQL today. This gap in features will narrow over time, but some features will be different because of the distributed nature of Aurora DSQL. For complete transparency on the supported PostgreSQL feature set you can refer to the Aurora DSQL documentation, helping you align your application needs with the service. The result is a database that combines PostgreSQL’s trusted foundation with advanced distributed computing capabilities, positioning your applications for future growth and scale.
When designing your workload for Aurora DSQL, consider the following factors (not an extensive list):
- Aurora DSQL doesn’t implement locking due to its optimistic concurrency control. If your application relies on logic that implements explicit database locks, you may need to refactor some parts of your application. For more detailed information refer to Concurrency control in Amazon Aurora DSQL.
- The service doesn’t support a multi-Region configuration with more than two read-write endpoints, which means that this service doesn’t support use cases that require data being synchronously replicated in more than two Regions.
- Aurora DSQL performs best when you follow two key design principles: avoid hot key writes and avoid hot key ranges. With Amazon Aurora DSQL it is ideal to define random primary keys for your tables. This could mean a single key based on a UUID, or a composite of several columns that together create a key with high cardinality
- The service’s optimistic concurrency model means that when multiple transactions attempt to modify the same data simultaneously (hot key writes), one will succeed while others must retry.
- Similarly, concentrating operations within specific key ranges (hot key ranges) undermines DSQL’s distributed architecture.
- To achieve multi-Region strong consistency for read-write operations (doesn’t apply to read-only operations) in multi-Region deployments, Aurora DSQL introduces an additional 2 RTT latency at commit time, which is directly proportional to the distance between the two Regions selected.
By aligning your design with these principles, you’ll be well-positioned to make the most of the substantial benefits of Aurora DSQL, setting the stage for growth and robust performance as your data needs expand.
Conclusion
In this post, I explored Amazon Aurora DSQL architecture and its contributions to its architecture, benefits as well as considerations using the service. In the subsequent post, I will dive into the end-to-end transaction processing capabilities of Aurora DSQL.