AWS Database Blog
Everything you don’t need to know about Amazon Aurora DSQL: Part 4 – DSQL components
Amazon Aurora DSQL employs an active-active distributed database design, wherein all database resources are peers and serve both write and read traffic within a Region and across Regions. This design facilitates synchronous data replication and automated zero data loss failover for single and multi-Region Aurora DSQL clusters.
In this blog series on Aurora DSQL, I’ve covered foundational concepts, explored features and caveats, and analyzed transaction behavior. In this post, I discuss the individual components and the responsibilities of a multi-Region distributed database to provide an ACID-compliant, strongly consistent relational database.
In the second blog post of this five-part series, I introduced the following image that illustrates the fundamental components of Aurora DSQL. In this post, I look at each component in more detail. I recommend revisiting the corresponding section in the second post to establish a comprehensive understanding of the subject matter. The following diagram is the system architecture diagram, illustrating data processing workflow within Aurora DSQL.
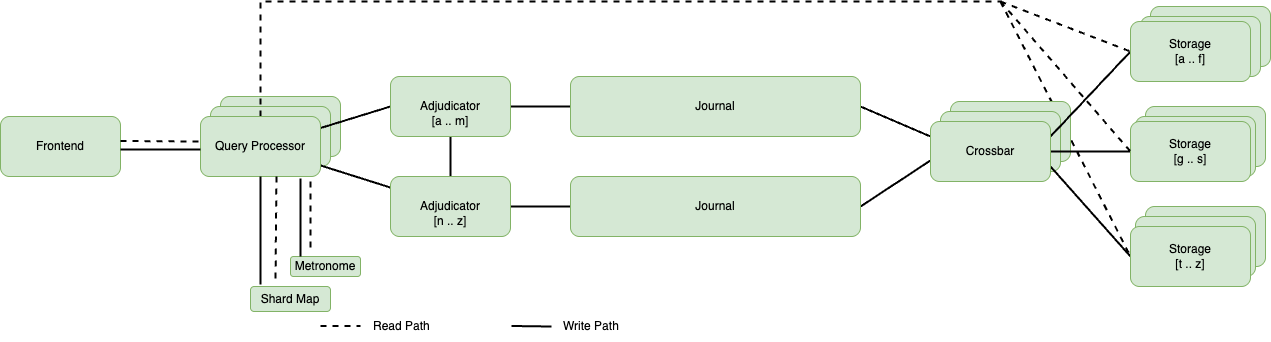
System architecture diagram illustrating data processing workflow within Amazon Aurora DSQL
The query processor (QP) oversees the complete SQL execution lifecycle. It parses incoming SQL statements, constructs execution plans, and optimizes these plans for processing. The QP manages data fetching, merges results, and performs necessary aggregations before returning the result set to the client. During transaction processing, it tracks both read and write sets, temporarily spooling writes until a transaction commits or rolls back. Upon transaction completion, the QP orchestrates the entire COMMIT protocol, providing proper coordination with other system components (as discussed in the preceding post).
The QP is designed as a transient, shared-nothing component with soft-state characteristics. Consequently, it isn’t responsible for several traditional database functions such as durability, consistency enforcement, concurrency control, fault tolerance, or scale-out operations. These functionalities are handled by the other components within the Aurora DSQL architecture. From an infrastructure perspective, QPs operate within Firecracker micro-virtual machines (microVMs) on QP hosts, with each host supporting multiple QPs. Each transaction is served by a single, dedicated QP. A dedicated per-database QP pooler manages the mapping of connections to active QPs, providing efficient resource utilization while maintaining strict database isolation.
Aurora DSQL employs caching exclusively for database catalog and metadata, deliberately opting out of data caching altogether. This design decision might appear counterintuitive, considering that databases typically cache to address three primary challenges:
- High storage latency compared to memory access
- The necessity of multiple points of access for data structures such as BTrees
- The requirement to maintain crash consistency through I/O latching
However, Aurora DSQL addresses these challenges differently. This architecture provides several benefits: The QP operates without holding locks, storage fleet placement and performance are optimized, and operations are pushed down to minimize round trips. This innovative approach delivers the same consistent performance at all levels of scale without the need for caching mechanisms.
The Aurora DSQL QP operates on a single-transaction processing model. Unlike data warehouse systems, a query executes within a single QP rather than being distributed across multiple processors. This means that all query execution happens on the QP, slow clients are not slowing down the database or impacting other clients (no noisy neighbors).
The adjudicator
The adjudicator system in Aurora DSQL operates as a distributed component, with multiple adjudicators sharing responsibility across the database. Each adjudicator owns specific key ranges. This sharding approach means that no single adjudicator becomes a bottleneck, enabling the system to scale across multiple Regions.
Adjudicators implement a sophisticated lease-based system to maintain consistency during failures and partitions. When an adjudicator takes responsibility for a key range, it acquires a lease against a journal and maintains it through periodic heartbeats. This lease system means that at any given time, exactly one adjudicator has authority over any key, preventing conflicting decisions during failure scenarios.
Through these mechanisms, the adjudicator system provides robust consistency guarantees while maintaining the scalability and reliability requirements of a distributed database system.
The journal
The journal serves as a critical component in the Aurora DSQL architecture, fundamentally reimagining the implementation of database durability. In contrast to conventional databases where the storage layer assumes responsibility for durability, Aurora DSQL delegates this task to the journal. This architectural choice significantly simplifies the database engine by separating concerns. A transaction is deemed committed after it’s committed to the journal, establishing a distinct boundary between transaction processing and durability guarantees. The journal stores comprehensive post-images of transactions rather than merely logging operations or modifications. This approach, while necessitating greater storage capacity, presents several advantages:
- It facilitates predictable recovery operations.
- It optimizes storage node processing.
- It minimizes computational overhead during replication.
The journal employs a sophisticated scaling model through the parallel operation of multiple journals to manage high throughput. Due to ordering guaranteed by the adjudicator, transactions can write to any available journal. Journal selection can be optimized for performance by selecting journals within the same Availability Zone as the committing adjudicator.
The journal stores data as snapshots in Amazon Simple Storage Service (Amazon S3) to provide recovery capabilities. The system captures periodic snapshots to capture the complete storage state. During recovery, the system loads the latest snapshot and replays the journal from that point forward. This approach eliminates the necessity to replay the entire transaction history while maintaining durability guarantees.
The crossbar
The journal component of Aurora DSQL provides transaction data to the crossbar component, which serves as an intermediary within the system. The crossbar merges data from multiple journals into a fully ordered sequence and distributes the data to appropriate storage shards. A critical consideration is that the crossbar must wait for all journals to process up to a specific timestamp before initiating its operations.
The crossbar functions as a sophisticated fan-out mechanism, subscribing to all partially ordered journals in the system to generate a unified, fully ordered stream of transactions. Its primary responsibility entails breaking down atomic transactions based on key ranges, so that each storage node receives the data pertinent to its assigned key space. This targeted distribution significantly enhances system efficiency and minimizes redundant data transfer.
One of the crossbar’s key functions is managing the timing of data delivery to storage nodes. It forwards data after it has observed a specific timestamp across all journals it monitors. This synchronization mechanism provides consistency but introduces potential latency challenges. To address this, the system employs a low-water mark that advances when data is available across all relevant journals.
The crossbar implements an innovative tail latency reduction approach using erasure codes. In this system, the adjudicator divides messages into M segments, where the original message can be reconstructed from any k segments (where k is less than or equal to M). These segments are distributed across multiple journals, enabling the crossbar to proceed after it has received k segments of any message. This design provides both scalability and fault tolerance.
Through these mechanisms, the crossbar manages the intricate task of coordinating data flow between journals and storage nodes while maintaining consistency and performance. The overall design contributes to the scalability and reliability of Aurora DSQL.
The storage
The storage layer in Aurora DSQL serves as the foundation for data persistence and retrieval, distinguishing itself significantly from conventional database storage systems. Its primary functions encompass providing long-term data durability and executing data queries, all within a unique architectural framework that segregates concerns across multiple components.
Write operations traverse a distinct path through the system, commencing at the journal and proceeding through the crossbar, which segments data into appropriate shards. Subsequently, the data reaches the storage nodes, where appliers integrate it into the storage system. In contrast, read operations adopt a more direct route, directly flowing from the QP to storage, thereby bypassing intermediate components for enhanced efficiency.
Rather than handling immediate durability (which falls under the journal’s purview), the storage layer focuses on long-term durability through periodic snapshots stored in Amazon S3. These snapshots support multiple critical functions:
- recovery following failures
- scaling operations
- index creation
- backup and restore functionality, including point-in-time recovery
The storage system implements a garbage collection mechanism based on a trim horizon concept, aligning with the low-water mark employed by the adjudicator of 5 minutes, which corresponds to the maximum transaction time. This approach facilitates each component to manage its own garbage collection based on local time, eliminating the necessity for intricate coordination.
In the event of a storage node’s failure, the system redistributes partition members to other storage nodes, using snapshots to restore the system’s state. This approach, coupled with the journal’s short-term durability guarantee, provides both high availability and data durability.
The storage layer’s design reflects the emphasis in Aurora DSQL on robust data management while delegating traditional database responsibilities such as concurrency control to specialized components.
Conclusion
In this post, I explored the individual components of Amazon Aurora DSQL, their operational mechanisms, and unique features. Additionally, I discussed the distribution of responsibilities within the system. In the subsequent post, I discuss the concept of clocks within Aurora DSQL.