AWS Database Blog
Generate an assessment report for a fleet of database servers using the AWS SCT multiserver assessor
AWS Schema Conversion Tool (AWS SCT) is a service that allows you to migrate heterogeneous databases by converting your existing database schema from one supported database engine to another. This tool has a functionality called assessment reporting. Based on the source and target database engines you choose and the object attributes in your source schema, the assessment tool generates reports on complexity level and efforts needed on your migration tasks and action items. You can use the effort estimates and plan the migration accordingly.
With release 647, AWS SCT introduced a new feature called the multiserver assessment report. Instead of one source and one target in one project, you can add multiple sources, and for each source, you can specify one or more potential target engines. The process is now simplified—you no longer need to create a project before you run the assessment report. The interface accepts three inputs: the project name, a location (where you want to save your assessment report), and the connections file (a CSV file containing multiple source schemas, their database server connection information, and the target database engines). The AWS SCT multiserver assessor evaluates the fleet of database servers to produce an aggregated report on top of the regular engine-specific reports, and shows the estimated complexity for each migration pair.
In this post, we show you how to configure the AWS SCT multiserver assessor to generate an aggregated report.
Solution overview
The solution is best suited for the following use cases:
- You need to perform a fleet-wide database assessment
- You need to profile the schema, objects, and attributes in the source database to identify the complexity and level of effort of a migration
- You need to run an aggregated assessment report for all possible heterogenous database migration targets in AWS
- You need to compare migration complexity for multiple target databases in AWS
Fleet-wide database migration assessment can be complicated. It involves running multiple assessment reports. Without the AWS SCT multiserver feature, adding additional migration pairs is challenging and requires tremendous effort.
With AWS SCT multiserver assessment, you use a single file as input. This reduces the cumbersome process of manually running on each server and enables automation through programmatic access. You don’t need to pre-create the target database engines—they’re actually virtual. You don’t even need to have AWS Cloud access; you can run AWS SCT from your on-premises machines. Enterprise customers with a large number and variety of source database engines can now process assessments more efficiently. You can quickly develop a migration strategy by comparing the target engines based on effort levels provided by AWS SCT multiserver assessment reports and build the roadmap of your database migration to AWS.
This post uses a Windows server to run AWS SCT. To demo the most common database conversion scenarios, we consider the source and target engines in the following table:
| Source Database | Target Database |
| Oracle | Amazon Aurora MySQL, Amazon Aurora PostgreSQL, Amazon Redshift |
| DB2 | Amazon RDS for MySQL, Amazon Aurora PostgreSQL |
| SQL Server | Amazon Aurora MySQL, Amazon Aurora PostgreSQL, Amazon RDS for MariaDB |
| Sybase | Amazon Aurora MySQL, Amazon Aurora PostgreSQL |
The solution includes the following high-level steps:
- Download and install AWS SCT
- Download the JDBC drivers for the source databases
- Configure JDBC drivers in AWS SCT global settings
- Configure memory settings for AWS SCT performance
- Create an input CSV file
- Run the multiserver assessment report
- Locate and view the assessment reports
Prerequisite
Before you run the multiserver assessment report, make sure you complete the following prerequisites:
- Make sure the server where you run AWS SCT has access/connectivity to your source databases.
- In each of your source databases, you should create an AWS SCT user and grant the user the required privileges. For details on granting permissions, refer to the following resources:
Download and install AWS SCT
For instructions on getting started with AWS SCT, refer to Installing, verifying, and updating AWS SCT. The process consists of three steps:
- Download the latest AWS SCT software for Microsoft Windows
- Extract the installer file
- Install it by opening the .msi file
Download JDBC drivers for the source databases
Download the required drivers for each of the source databases:
- Oracle driver – ojdbc8.jar
- SQL Server driver – mssql-jdbc-7.2.2.jre11.jar
- IBM DB2 LUW driver – db2jcc-db2jcc4.jar
- SAP ASE driver – jconn4.jar
Configure JDBC drivers in AWS SCT global settings
To configure your JDBC drivers, complete the following steps:
- Launch your AWS SCT client
- On the Settings menu, choose Global settings
- Choose Drivers
- Choose Browse and choose the JAR file for each source database engine
- Choose OK
For more details or to download and install other database drivers, refer to Installing the required database drivers.
Configure memory settings for AWS SCT performance
The AWS SCT assessment report can consume a large amount of memory, especially when you have many objects in a schema. The default allocated memory to AWS SCT is less than 1 GB. To avoid an OutOfMemoryError, you should allocate more memory to AWS SCT before you run the report.
- On the Settings menu, choose Global settings
- Choose Performance and memory
- Select Balance speed and memory consumption (experimental mode)
- Choose JVM options
- Choose Edit config file
- Choose OK on the confirmation page
- Edit the file by adding two lines to the JavaOptions section. For example, if you have 16 GB memory available to your server, you can set the minimum JVM to 1 GB and maximum JVM to 12 GB.
Xmx12288M
Xms1024M - Save the file and restart AWS SCT
Create an input CSV file
AWS SCT accepts a connections file as input. In the file, you describe your source schema, server connection information, and target engines.
The following is an example connections file in Excel. It shows the column values and syntax for Oracle, SQL Server, DB2, and Sybase as sources. The conversion targets are Amazon Aurora MySQL-Compatible Edition, Amazon Aurora PostgreSQL-Compatible Edition, Amazon Redshift, and Amazon Relational Database Service (Amazon RDS) for MariaDB.

Substitute the parameters with true values and save it as CSV file on your local computer.
The following is an example created for this demo:
Run the multiserver assessment report
To run the multiserver assessment report, complete the following steps:
- Launch AWS SCT
- On the File menu, choose New multiserver assessment
- For Project name, enter a name for your assessment project (for this post,
Multiserver assessment1) - For Location, enter the directory where you want the reports to be generated
- For Connections file, enter the full path for the CSV file you created
- Choose Run
Figure 1 shows example entries for step 1 through step 6.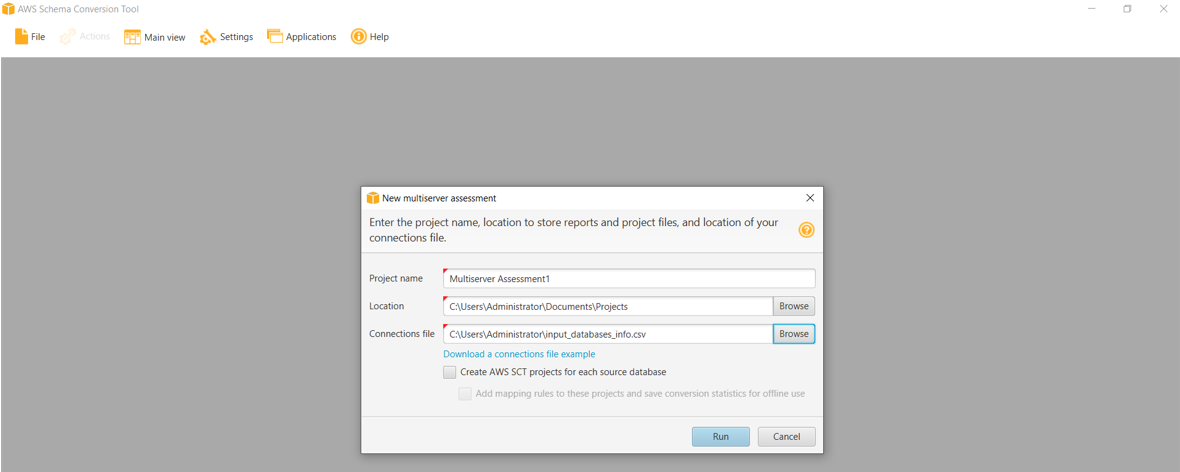
Figure 1 – AWS SCT Multiserver assessment interface 1
- Choose Yes to proceed on the confirmation page as in Figure 2.

Figure 2 – AWS SCT Multiserver assessment interface 2
After the report runs successfully, a pop-up message appears with a button Open Report as shown by Figure 3.

Figure 3 – AWS SCT Multiserver assessment report run completed page
Locate and view the assessment reports
AWS SCT builds a directory tree and saves the reports in each directory according to the parameters you entered earlier. In the following example, as shown by Figure 4, the AWS SCT reports are generated under c:\Users\Administrator\AWS Schema Conversion Tool\Projects\Multiserver assessment1.

Figure 4 – AWS SCT Multiserver assessment report directory structure
Aggregated report
The aggregated report presents conversion complexity by each source schema and its targets. Conversion complexity is the level of difficulty to perform the migration to the target engine. 1 represents the lowest level of complexity, and 10 represents the highest level of complexity.
For example, Figure 5 is part of the aggregated report. It shows the conversion complexity for each source schema targeting at Aurora MySQL and Aurora PostgreSQL. Based on this report, you may choose MySQL or PostgreSQL as the target engine for your Sybase and DB2 schemas because the complexity levels are low (equal to 1). However, for Oracle and SQL Server schemas, Aurora PostgreSQL may be a better choice because Aurora MySQL costs three times the effort compared to Aurora PostgreSQL.
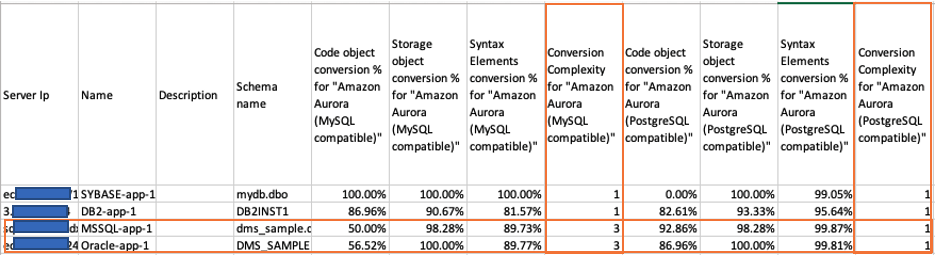
Figure 5 – AWS SCT Multiserver assessment aggregated report
Specific engine assessment reports
In additional to the aggregated report, AWS SCT generates four reports for each specific source and target pair. For example, Figure 6 displays the files created for Oracle to Aurora PostgreSQL conversion.

Figure 6 – AWS SCT Multiserver assessment reports for a specific source and target engine pair
AWS SCT assigns an Action item number to the conversion issues that can’t be resolved by AWS SCT automatically in the detailed CSV report. It then summarizes the number of occurrences and assigns a score for Learning curve efforts (effort needed to design an approach) and Efforts to convert an occurrence of the action item (effort needed to convert each action item, per the designed approach) in the summary report. See Figure 7.

Figure 7 – AWS SCT Action Items summary report for a specific source and target engine pair
In Figure 7, action item 5025 in the packaged procedure SELLRANDOMTICKETS has unsupported syntax. AWS SCT assigned 8 to the learning curve effort and 160 to the conversion effort for each occurrence. Compared to other items, it’s considered an expensive item because the scores for both columns are higher. You should plan accordingly to allocate more time to this item.
Summary
In this post, we showed you how to configure and run an AWS SCT multiserver assessment report. We also demonstrated where to locate and view the reports. The multiserver feature allows you to mix and match your source and target engines so that you can get the most benefit from one process. AWS SCT aggregates and analyzes the action items, assesses the conversion effort for the entire schema as well as specific items, and presents these in a group of reports.
You can use these estimates to efficiently plan ahead for your database migrations. We appreciate your feedback!
About the Authors
 Shunan Xiang is a Senior Database Consultant with the Professional Services team at AWS. He works as a database migration specialist to help Amazon customers in design and implementing scalable, secure, performant, and robust database solutions on the cloud.
Shunan Xiang is a Senior Database Consultant with the Professional Services team at AWS. He works as a database migration specialist to help Amazon customers in design and implementing scalable, secure, performant, and robust database solutions on the cloud.
 Li Liu is a Senior Database Specialty Architect with the Professional Services team at Amazon Web Services. She helps customers to migrate traditional on-premise databases to AWS cloud. She specializes in database design, architecture and performance tuning.
Li Liu is a Senior Database Specialty Architect with the Professional Services team at Amazon Web Services. She helps customers to migrate traditional on-premise databases to AWS cloud. She specializes in database design, architecture and performance tuning.
 Vaibhav Khandelwal is a Senior Product Manager with the AWS Database Migration Services (AWS DMS) and AWS Schema Conversion Tool (AWS SCT) team. He leads the roadmap for AWS SCT and helps customers migrate and modernize their legacy database and analytics systems on AWS.
Vaibhav Khandelwal is a Senior Product Manager with the AWS Database Migration Services (AWS DMS) and AWS Schema Conversion Tool (AWS SCT) team. He leads the roadmap for AWS SCT and helps customers migrate and modernize their legacy database and analytics systems on AWS.