AWS Database Blog
How to solve some common challenges faced while migrating from Oracle to PostgreSQL
Companies are experiencing exponential data growth year-over-year. Scaling the databases and the hardware infrastructure to keep up is becoming more and more challenging. If your workloads just are not suitable for non-relational data stores, how do you overcome the scaling challenges without spending tons of money in managing the underlying infrastructure?
Amazon RDS for PostgreSQL and Amazon Aurora with PostgreSQL compatibility make it easy to set up, operate, and scale PostgreSQL cloud deployments in a cost-efficient manner. During the last year, we have migrated more than 100 Oracle databases (ranging from hundreds of GBs to several TBs) to Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL.
In this post, I walk through some of the most common issues that surfaced during our migrations. I assume that you already have some experience moving data from one database to another using AWS Database Migration Service (AWS DMS). I also used AWS Schema Conversion Tool (AWS SCT) quite a bit. I’ll start with the issues you might face during the data extraction process. I’ll then cover issues during data migration. Finally, I’ll discuss performance issues to watch for in PostgreSQL after the migration.
Extraction phase issues
A common issue during this phase was slow data extraction for large tables, which triggers an ORA-01555 error (snapshot too old) in the source DB. Our experience is that tables larger than 500 GB can encounter issues more frequently. It is relative though and depends on the environment. The following section explains the ORA-01555 error and how to avoid it in order to accelerate your extraction process.
ORA-01555 during extracting data from the source
Problem description – If you’re migrating large tables or table partitions from Oracle, the query may fail with an ORA-01555 error due to longer runtime of the extract query. If you’re familiar with Oracle, chances are you have seen this error at some point in the past. The query is requesting an old image of the block that can’t be created. The undo information required to create that image has already been overwritten. If your target database has limited throughput, it can lead to an increase in overall migration time causing extracts with ORA-01555 error.
Solution – There are different approaches to solve this issue. The idea is to either:
- Reduce the extract query runtime by optimizing the query in the source DB.
- Make sure the source is retaining the old image of data longer than the extract query runtime.
Here are some ways to avoid this error –
- Tuning the extract query: Any performance improvement reduces the chance of encountering an ORA-01555 error. So, make sure you have the right indexes in the source for the extract queries to run faster. In some cases, you can create new indexes specific for the migration. Consider the amount of data you’re moving. Do you need to transfer all the data (all rows of any table)? If not, you can filter the data using DMS or purge the data in the source before staring the migration. This is an important step as you don’t want to spend time in migrating unwanted data.
- If you’re still facing the ORA-01555 error after improving the extract queries, another common solution is increasing the undo retention size in the source DB. For example, if the longest extract query in your database is running for an hour then setting your undo retention more than an hour might avoid this error. If the rate of data change is high, unexpired undo blocks can still get overwritten before undo retention expires. Increasing undo retention might not help in such cases. Also, in cases where the extract runs very long, increasing undo retention may not work. Keep in mind that increasing undo retention can have a performance impact and it should be increased gradually after testing in development environment.
- The next step is to investigate additional options to make the query faster. If the cause of slow extract is limited I/O from a replication instance, then using a lager replication instance can help. Larger replication instances with more disk storage have more I/O bandwidth, This can speed up the migration and reduce the total extract time in the source and reduce the chances of ORA-01555.
- Consider source-filter options and depending on the size of the table, you can run the tasks using different filters from different replication instances. This distributes the loading with more computational power, making extract faster and might help in avoiding ORA-01555.
- If you have such a high data change rate that none of the above solutions are working for your use case then you can create an active data guard (read-only physical standby) and take it out of replication. After replication is stopped and you have the static copy of the data, you can start the full load from standby database and take note of the starting timestamp so it can later be used to start the change data capture (CDC) from primary database. Using this approach, you’re running the full load against the static data copy, which minimizes the chances of running into ORA-01555.
To summarize, find the best solution for your use case. For example, if you’re migrating a table and full load is failing after 90-95% of data copy, increasing the undo retention might be the right way to fix this issue. However, if you have decent size undo retention and full load is failing after 20% data copy, look for other alternatives such as data purge, source filter, or bystander etc.
Migration phase issues
This is the trickiest phase as it combines schema conversion and data migration. You have to deal with data type conversion issues, character set mismatch issues, issues with large objects migration and so on. The following are some of the most common issues.
Data type conversion Issues
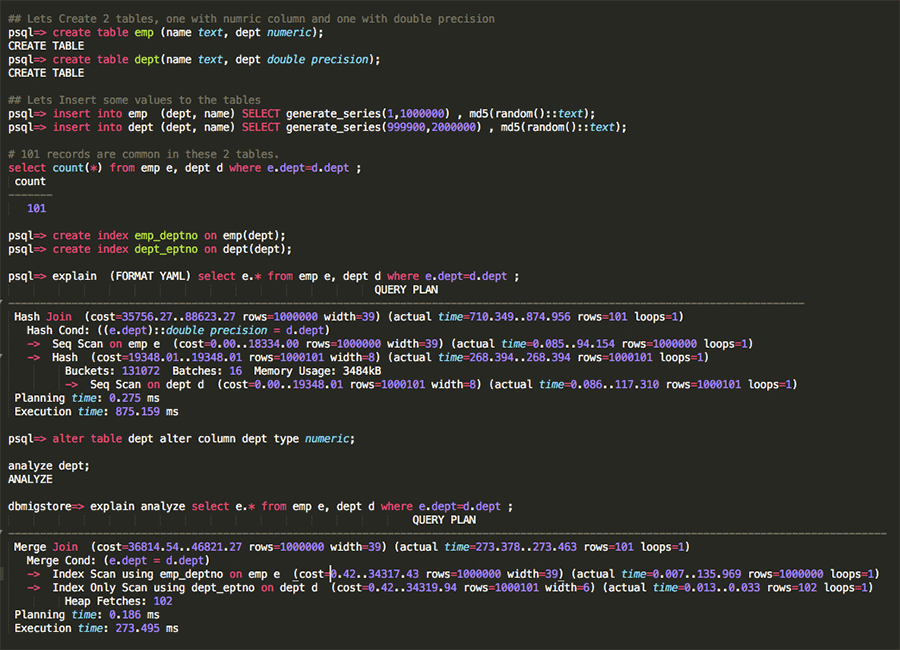
Problem description – During schema conversion, SCT converts number data types (without precision) to double precision data types and number data types (with precision) remains as numeric(p) in PostgreSQL. When you perform a join on these columns, the PostgreSQL optimizer cannot leverage an index on these columns, which causes performance degradation.
Solution – To illustrate this problem, I have created two tables in PostgreSQL, one with numeric columns and one with double precision. I have also added indexes on these two columns. As you can see from the execution plan listed below, the optimizer chooses Seq Scan when the tables are joined on numeric and double precision columns. As soon as you change the column data type from double precision to numeric for dept table, the optimizer chooses the right execution plan i.e. Index Scan. Make sure you pay attention to columns without any precision during the migration and override number columns (without any precision) to Numeric.
In addition to this, it’s really important to choose the right numeric data type in PostgreSQL, later in the document point #4 provides detailed insight on that.
Empty string vs null in PostgreSQL
Problem description – Unlike Oracle, empty strings are not treated as null in PostgreSQL. Oracle automatically converts empty strings to null values but PostgreSQL doesn’t. If your application is inserting empty strings and treating it as a null value in Oracle, modify how the application inserts or extracts the data before moving to PostgreSQL. You might understand this better with a use case.
Working – I have compared how null values and empty strings are handled by Oracle and PostgreSQL side by side. In the example below, I am creating exact same table in Oracle, PostgreSQL and inserting one row with name column as null and one with name column having empty string in both databases.

As you can see the null is treated as same by both databases. However, when I insert an empty string, Oracle stores it as null and you can query it using predicate “where name is null” and both values are displayed. On the other hand, PostgreSQL doesn’t display the row with empty string when I query using same predicate “where name is null”. To find the row in PostgreSQL, I query using “=” operator and look for the empty string in predicate.
Conclusion – Your application has different results in PostgreSQL if it’s inserting empty strings and fetching data assuming empty strings as null values. Before migrating to PostgreSQL, you must change the way the application inserts data to PostgreSQL by confirming you add null for all null values (not empty strings) or that you modify all your select queries to include “like” operator for empty strings along with null. So, your queries may look something like [select * from emp where name is null or name like ”] to replicate Oracle’s null behavior.
Null behavior in composite unique index
I can’t stress enough how important it is to pay attention to queries and application design that require changes based on how differently PostgreSQL handles null from Oracle. If you’re migrating from Oracle, you’re likely to run into issues with null. Many of our applications are designed to handle nulls specifically according to how Oracle treats nulls. The same is likely true of other DB platforms moving to PostgreSQL.
I’ll dig farther to find out what happens if you have a unique composite index and you’re inserting null in one of those columns. Again, I’m comparing Oracle and PostgreSQL behavior side by side.
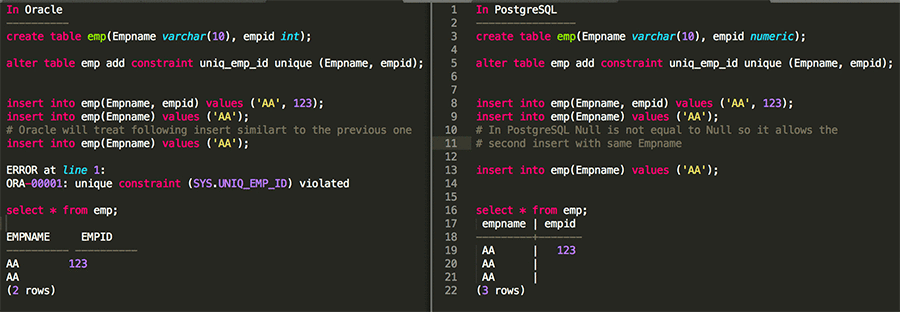
As you can see from above use case, I have added a composite unique constraint on Empname, empid columns. Now, when you try to insert duplicate value of first column Empname as ‘AA’ with empid as null, Oracle throws an exception (unique constraint violated). However, in PostgreSQL two nulls are not equal so it allows duplicate ‘AA’ values considering second column (empid) is different. In PostgreSQL, the null value represents an unknown value, and it cannot decide whether two unknown values are equal.
One way to replicate Oracle’s behavior is to use partial index in PostgreSQL, following snippet demonstrates the usage of partial index.

I would also recommend reading parameter Transform_null_equals in PostgreSQL documentation if you’re dealing with null issues and your application code is using ‘=’ operator for null comparison. It should only be used as a temporary workaround, not a permanent fix. It’s bad practice to keep it around.
Choosing numeric data type in PostgreSQL (numeric vs BIGINT)
This was a common mistake I saw while migrating from Oracle to PostgreSQL. By default, many DBAs pick the numeric data type in PostgreSQL over smallint, integer, bigint for converting all number columns in Oracle. There can be many reasons for this: The fact that I only pay attention to things that result in errors during migration. I go over the PostgreSQL documentation only on an as-needed basis. Maybe I am so used to working on particular RDBMS that I tend to think around the viable options for that RDBMS.
The question I should be asking is, are Oracle number and PostgreSQL numeric the same? Well, maybe in some way, as both holds the numeric values but with one big difference. ln Oracle, the largest number data type can hold 38 digits, however, in PostgreSQL, the largest numeric data type can hold 131,072 digits. PostgreSQL offers several other number data types: smallint, integer, bigint. Find the right balance between range, performance and storage to choose the optimal number data type.
If you pick numeric over bigint/interger, you pay the penalty in term of performance. I can find out by comparing it side-by-side.
In the following snippet I am comparing two different PostgreSQL data types side by side. Actually, I compared three data types: bigint, integer and numeric. Integer behaved similarly to bigint, so for this illustration, I removed it.
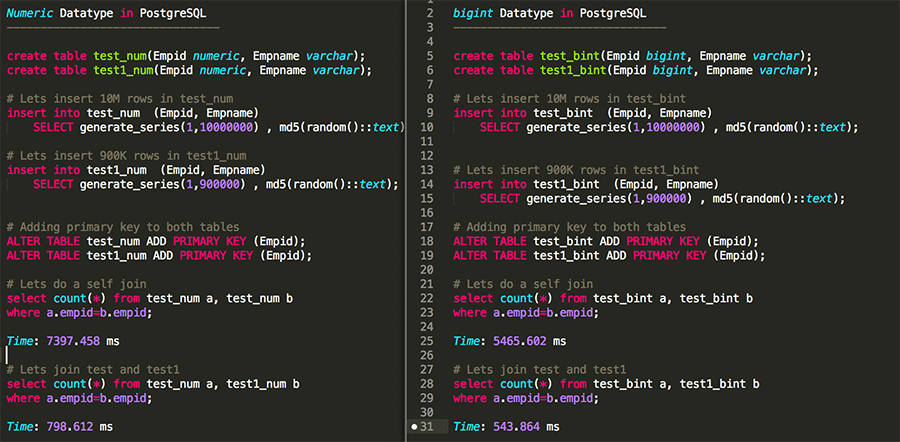
As you can see from the test, using bigint over numeric can provide you a significant 30–35% performance gain even with the smaller dataset.
SEQUENCE cache behavior in PostgreSQL
Problem description – Sequence values in PostgreSQL are cached by engine process and can result in unexpected results if the sequence has a cache value greater than one and it is used by multiple sessions concurrently.
Working – To illustrate the problem, compare how the sequence values are generated in Oracle and PostgreSQL side by side. In the following snippet, I have a sequence starting with 100 and cache size of 20. Session A and session B are using the same sequence to generate the next value in Oracle and PostgreSQL.

In Oracle (left half of the snippet), session A and session B access the database object to generate the next value of the sequence and thus the sequence number generated by different sessions are in order.
In PostgreSQL, session A caches values from 100–120 and session B caches values from 121–140. So, session B generates values from 120 onwards while session A keeps on generating the value from 100–119.
As you can see due to session-based caching in PostgreSQL, sequence values are not in order and if both sessions are inserting to same table concurrently, value 121 from session B can be inserted before value 102 from session A. This can cause problems if your application has any dependency on the order of values generated by sequence.
Solution – If your application has such dependency, either change the application design or go with cache size of 1 for all sequences.
Final cutover and post migration issues
One issue before the final cutover to PostgreSQL is how to manage the performance impact that can surface during text searches after switching the reads to PostgreSQL. In this section, I talk about this issue in detail.
Performance issues with plaintext searches in PostgreSQL
Problem description – Full text searches are generally slow in PostgreSQL database compared to few other RDBMS and using a normal Btree index may not help in text searches. For example, SQL running with ‘like’ operator can slow down drastically as the engine query optimizer chooses to do full table scan (seq scan) as opposed to an index scan in Oracle.
Solution – Generalized Inverted Index (GIN) and Generalized Search Tree (GiST) indexes can be used to speed up the text searches in PostgreSQL. GIN indexes can be helpful in scenarios where you have to do a full text search. In order to use GIN or GiST indexes, install the pg_trgm extension. After you have added the extension, you can quickly create GIN indexes. I refer to only GIN index in this post, but I would recommend you to go through the pros and cons of both GIN and GiST indexes before implementing these in your environment. In summary, GIN is good for static data and provides faster lookups but slower to update, and GIST is good for dynamic data and faster to update but slower lookups.
Working – To illustrate the problem, create an employee table (emp). I am using the random md5 to populate the table and using the like operator for the full text search. As you can see below, the optimizer filters all rows and uses a Seq Scan, reasonably so I don’t have any index.
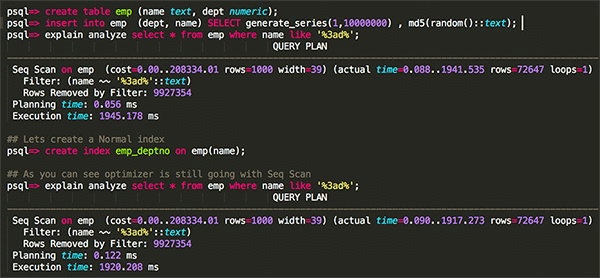
In the next step I add the Btree index and find out what changes.
Wait. The optimizer is still choosing Seq Scan opposed to Index Scan? With only 10M records and small row length it’s taking ~1900 ms for one execution. In a real production environment if you have to scan through the logs for text matches, this operation can take significant amount of time and probably be unacceptable for most business use cases. So, how do you speed up such a query?
Take a look at GIN (Generalized Inverted Index) indexes. The primary purpose of GIN indexes is to support highly scalable text searches in PostgreSQL so if you’re looking for a word or a pattern in a text log file, GIN Index can help speed up the search.

As you can see below, after creating a GIN index, optimizer is picking the optimal plan with Index Scan. Overall execution time of the query went down from ~1900 to ~83 ms.
In this case I am using three letters (‘%3ad%’) for the search. If you increase the number of letters (to certain extent) in search condition, you get better performance. I can see what happens when we use six letters (‘3adfgk’) in search condition.

As you can see from above that query executes much faster (0.129ms) in this case. Keep in mind that adding the right search condition might help in superior performance.
While having more letters in search condition help in execution time in most cases, you might be wondering what happens when I use fewer than three letters in search condition? Here it is:

Well, above query is not using the index at all, why? To understand the reason why the index wasn’t picked by optimizer in this case, I want to first understand the gin_trgm_ops operator that was used while creating the GIN index.
gin_trgm_ops operator class is used here for creating trigram index. Trigram is basically a text broken down to sequence of three letters so any search should have at least one trigram for optimizer to use the index. When I use only two letters during the search condition (%3a%), trigram index can’t be used due to unavailability of trigram. Thus, it’s important to have at least three letters in search patter to make use of trigram index.
Spaces are also counted in trigram meaning ‘%a %’ (two spaces after a) is a trigram and optimizer uses GIN index if you’re searching based on this condition. You can easily find trigrams of any particular word by running the following command:
GIN index lookups are faster but GIN indices are much slower to update. So, carefully benchmark it against your workload before using it. GIN indexes are best for static kind of workload. Also, keep in mind you can use normal Btree index if your search pattern is left anchored, for example ‘abc%’. Only for search patterns that are not left anchored ‘%abc%’, you may have to go with GIN/Gist Indexes for best results as Btree indexes can’t help for such search patters.
Conclusion
This post provides you an overview of some of the most common issues you can run into while migrating from Oracle to RDS PostgreSQL.
If you’re looking to learn even more about the migration process, I recommend reading Migrate-your-oracle-database-to-PostgreSQL/. Also, check out our migration playbook for Oracle to Amazon Aurora migrations. The playbook is helpful and provides step-by-step instructions that you can adjust according to your migration requirements.
Follow AWS DMS best practices and the latest version of replication instance for your migration. But if you run into issues, hopefully this post might help you mitigate the issues or guide you in the right direction. If you have any questions or suggestions, please leave a comment. Good Luck!
About the Author
 Abhinav Sarin is a Database Manager with the Big Data Technologies team at Amazon. He works with internal Amazon customers to move several services from on-prem Oracle to Aurora, RDS PostgreSQL, RDS MySQL databases.
Abhinav Sarin is a Database Manager with the Big Data Technologies team at Amazon. He works with internal Amazon customers to move several services from on-prem Oracle to Aurora, RDS PostgreSQL, RDS MySQL databases.