AWS Database Blog
How to Migrate Your Oracle Database to PostgreSQL
Knievel Co is a database engineer at Amazon Web Services.
This blog post provides an overview on how you can migrate your Oracle database to PostgreSQL. The two biggest parts of a database migration are the schema conversion and the data replication. We go over how to use the AWS Schema Conversion Tool (AWS SCT) and the AWS Database Migration Service (AWS DMS) to tackle these two parts.
Before we cover SCT and DMS, you should take some preliminary steps that have been proven to be helpful for every migration. One way to make the migration easier is to have what is usually called a modernization phase before the migration. This phase involves taking an inventory of objects in your Oracle database and then making a few decisions.
First, deprecate any objects that are no longer needed. Don’t waste time migrating objects that no one cares about. Also, purge any historical data that you no longer need. You don’t want to waste time replicating data you don’t need, for example temporary tables and backup copies of tables from past maintenance. Second, move flat files and long strings stored in LOBs, CLOBs, LONGs, and so on into Amazon S3 or Amazon Dynamo DB. This process requires client software changes, but it reduces the complexity and size of the database and makes the overall system more efficient. The objects, like PL/SQL packages and procedures, need to be manually migrated if SCT cannot translate them, or considered to be moved back to the client software.
In this blog, we will focus on migrating the database from Oracle to PostgreSQL, using the steps suggested below. If you aren’t moving to a different platform, you might find more appropriate native tools or other techniques to move your database.
- Create your schema in the target database.
- Drop foreign keys and secondary indexes on the target database, and disable triggers.
- Set up a DMS task to replicate your data – full load and change data capture (CDC).
- Stop the task when the full load phase is complete, and recreate foreign keys and secondary indexes.
- Enable the DMS task.
- Migrate tools and software, and enable triggers.
Create your schema in the target database
Begin your migration by taking a look at the schema that you want to migrate. In our case, we use the AWS Schema Conversion Tool (AWS SCT) to perform the analysis. When you start the application, you need to create a new project, with the source being Oracle and the target being PostgreSQL. When you’re connected, select the name of the schema that you want to migrate on the left side. Right-click the schema name and choose Convert Schema. Then choose View / Assessment Report View.
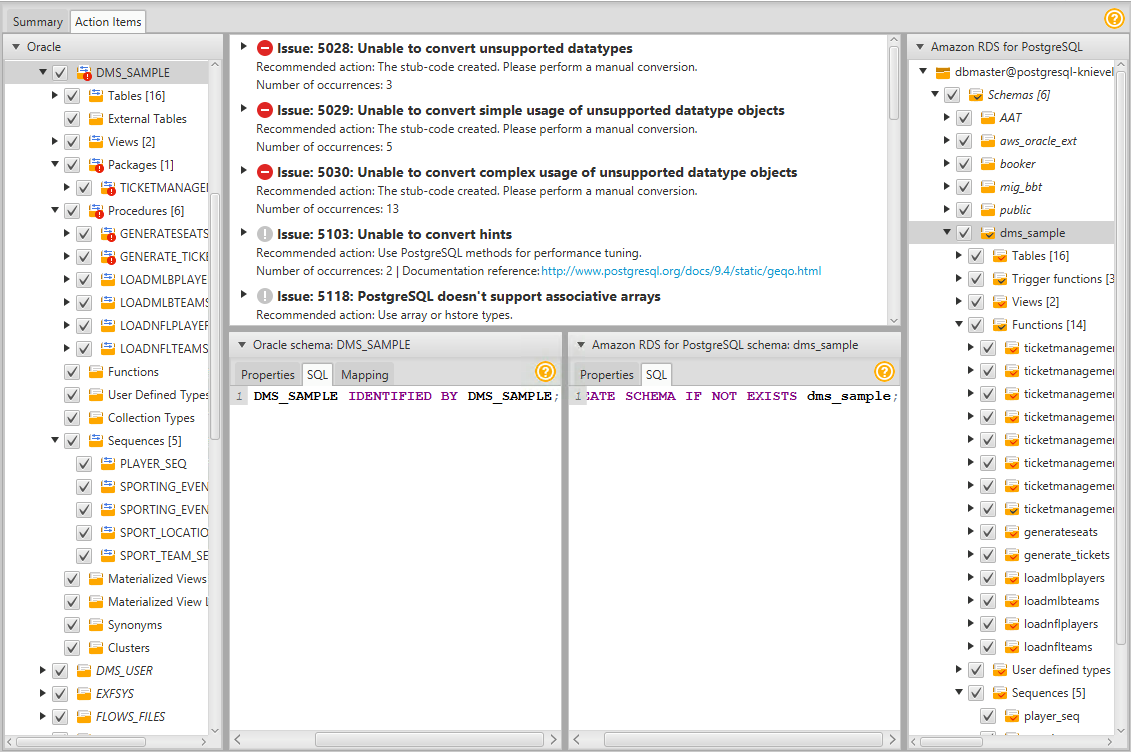
The AWS SCT assessment report is a high-level overview of the effort required to convert your Oracle database to PostgreSQL. The following is an example of what the assessment report looks like:

The report breaks down by each object type the manual work effort needed to successfully convert it. Generally packages, procedures, and functions have some issues to resolve. AWS SCT also tells you why to fix these objects and gives you hints on how to do it.

If your schema doesn’t convert automatically, here are some helpful hints to fix the issues:
- Modify objects on your source Oracle database so that AWS SCT can convert them to the target PostgreSQL.
- Try converting the schema as-is and modifying the scripts generated by AWS SCT manually before applying them to the target PostgreSQL database.
- Ignore the objects that cannot be converted and replace the functionality with another AWS service or equivalent.
When you make improvements to the convertibility of the schema, you can go through an iterative process to regenerate the report and schema. The Action Items view provides you with an issue by issue listing as you work through the conversion process. When you are happy with the converted schema results, you can apply them to the target PostgreSQL database.
We recommend that you browse through the schema of the target database and do a cursory check of column data types, object names, and so on. For more information about data types, refer to the Reference for AWS Database Migration Service for source and target data types. Also, because the conversion is from Oracle to PostgreSQL, one concern is that object names are uppercase in Oracle and lowercase in PostgreSQL.
Drop foreign key constraints and secondary indexes; disable triggers
When we settle on the schema that we want on the target, we have to prepare it for migrating the actual data from the source. We will be using the AWS Database Migration Service (AWS DMS). DMS has two phases: full load and change data capture (CDC). During the full load phase, the tables are loaded out of order. Thus, we have some foreign key constraint violations if we keep constraints enabled on the target. Also, during the full load, secondary indexes should be disabled because they can slow down the table replication. They do so because the indexes need to be maintained as the records are loaded.
On the target PostgreSQL database, run a query to generate DDL on the database tables’ foreign key constraints and save the output. You can find many sample queries online to do this. You should get a similar to the following. Doing this gives us the DDL to recreate the foreign key constraints later.
Then, similarly, run a DDL-generating query to drop all the foreign key constraints on the target database.
Now do the same for the secondary indexes – generate the create commands and the results, then drop the secondary indexes.
Next, disable triggers.
If you are using sequences for ID columns, we recommend that when you create them on the target, you set the next values higher than they are on the source database. Leave enough of a gap to make sure that the values are still higher than for the source database at your migration cutover date. This approach avoids collisions in sequence IDs after the migration.
Set up a DMS task to replicate your data
Now that we have prepared the schema on the target PostgreSQL database, we are ready to replicate the data. This is where DMS comes in. The great thing about DMS is that not does it replicate data for each table, but it keeps that data up to date with CDC mode until you’re ready to migrate.
Prepare the source Oracle database:
- Make sure that the Oracle login has the necessary permissions.
- Set up the supplemental logging that DMS needs to capture changes from the Oracle source database.
- For additional preparation information, see the DMS documentation about the source Oracle database.
In the AWS console, bring up DMS. First, you will need to create a replication instance. A replication instance runs the DMS task. This instance is an intermediary server that connects to both your source Oracle database and target PostgreSQL database. Select an appropriately sized server, especially if you expect to create multiple tasks, migrate a large number of tables, or both.

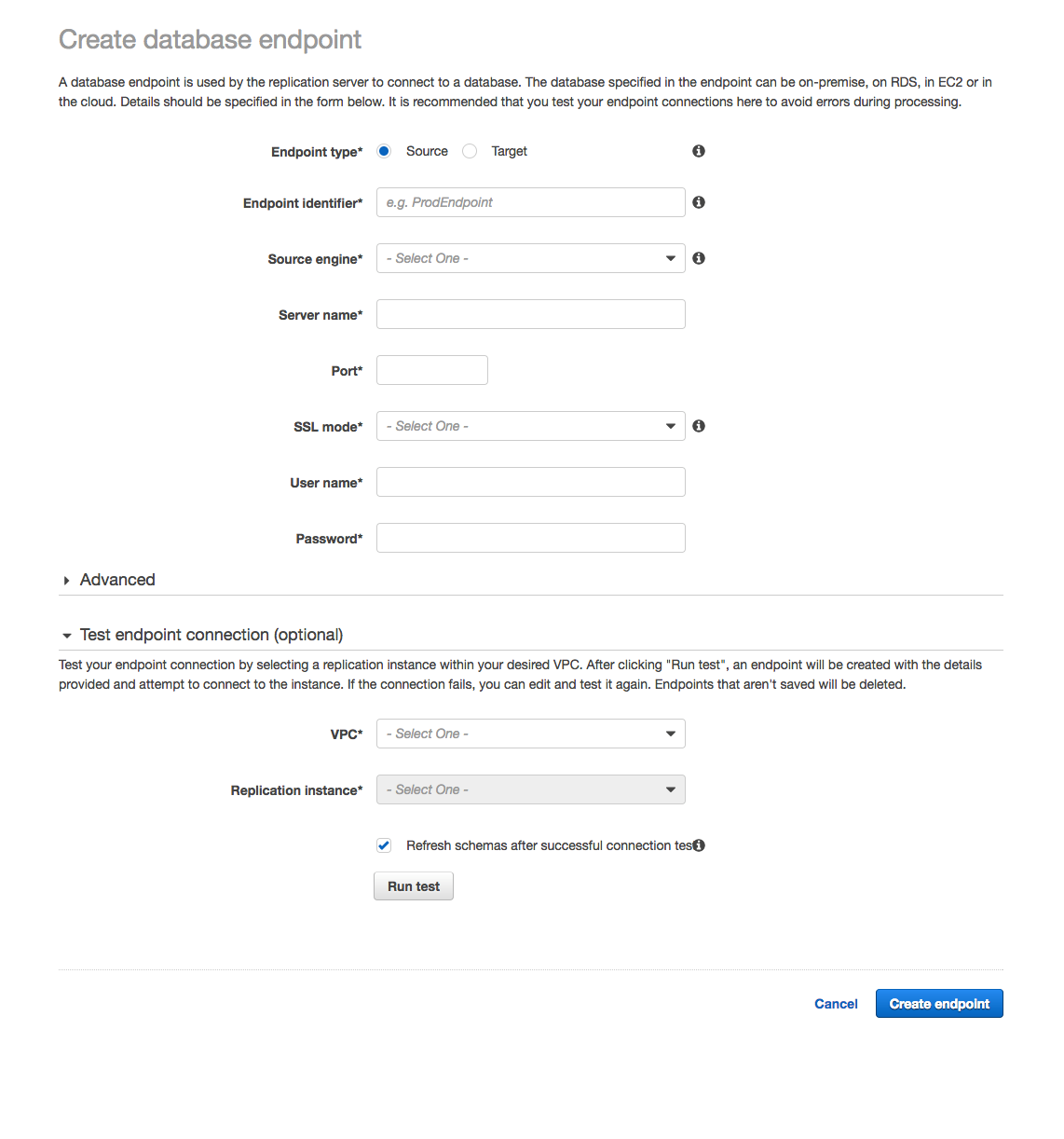
Next, create an endpoint for your source database and another endpoint for your target database. Enter all the appropriate connection information for the Oracle database and the PostgreSQL database. Make sure that you select the Refresh schemas option after a successful connection test and Run test before you finish creating each endpoint.
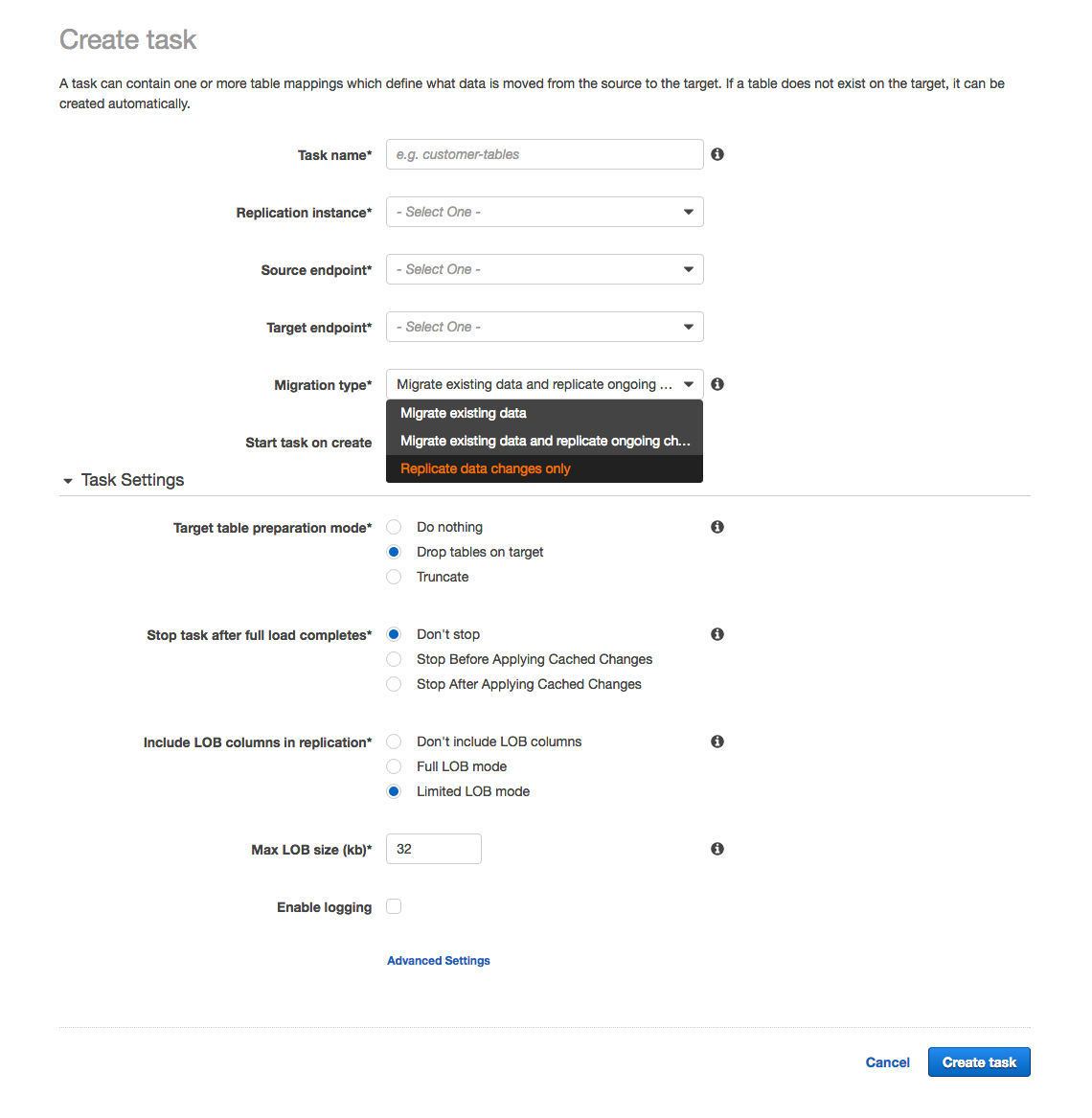
Now you’re ready to create a task. Enter a task name, select the replication instance you’ve created, and the source and target endpoint. For Migration Type, you’ll want to use Migrate existing data and replicate ongoing changes. Because we are using AWS SCT to precreate the schema, select Do nothing or Truncate for Target table preparation mode.
Select Stop After Applying Cached Changes for the option Stop task after full load completes. We want the task to stop temporarily after the full load completes and the cached changes are applied. Cached changes are changes that have occurred and accumulated while the full table load process was run. This is the step just before CDC is applied.
Hopefully, we modernized our source Oracle database and moved LOBs to S3, DynamoDB, or another similar service. If not, then we have a couple options on how to handle LOBs. For the option Include LOB columns in replication, select Full LOB mode if you want to replicate the entire LOB for all tables. Select Limited LOB mode if you want to only replicate the LOBs up to a certain length. You specify the length of the LOB to migrate in the Max LOB size (kb) text box.
Finally, we suggest that you choose Enable logging so that you can see any errors or warnings that the task encounters and troubleshoot those issues. Choose Create task.
Next, under Table mappings, select which schema you want to migrate and choose Add selection rule. Choose the JSON tab. Select the Enable JSON editing check box. Then enter the following JSON string, replacing the schema name DMS_SAMPLE with your schema name.
This JSON string transforms the schema name, table names, and column names to lowercase for PostgreSQL.
When the task is created, it starts automatically. You can monitor its progress using the DMS console by selecting the task and clicking on the Table statistics tab. When the full load is complete and cached changes are applied, the task stops on its own.

Stop the task when full load is complete; recreate foreign keys and secondary indexes
Your table loads are now complete! Now is probably a good time to review the logs to make sure that there are no errors in the task.
The next phase of the task is CDC, which applies changes in the order that they occurred in the source database. This approach means that foreign keys can be recreated because the parent tables are updated before child tables on the target database.
Recreate foreign keys and any secondary indexes that were dropped earlier by adjusting the generated script as required. The secondary indexes are important in this phase of the task. This phase is important because any updates done on the source database with a where clause are also index lookups on the target database also. If updates are missing indexes, these updates run as full table scans.
Hold off enabling triggers until the migration switchover, because they can update data coming from the source.
Enable the DMS task
Now that we have the foreign keys and secondary indexes back, we can enable the DMS task. Simply go to the DMS console and choose Tasks. Select the task in the list and choose Start/Resume. Select the Start option and choose Start task.

Migrate tools and software; enable triggers.
Finally, the cutover point is here. When the tools and software connections have stopped accessing the source database and the DMS task has replicated the last data changes to the target database, stop the DMS task in the DMS console. Then enable triggers on the target database.
Helpful hints
- To make your schema easier to convert, use AWS SCT to get an assessment report and iterate through the action items. You need to generate the target schema multiple times until you come to the final version of the target PostgreSQL schema.
- To ensure that the queries on the new schema works on the new platform, test your application on your target system. AWS SCT can also convert your application queries to PostgreSQL – for details check out the AWS SCT documentation. You’ll also want to implement load testing on the target system to ensure that the target server size and database settings are correct.
- Practice the actual migration steps outlined preceding, and streamline your process. These steps mentioned are just a starting point, and each database is unique.
Further reading
We recommend that you look through the following:
- Documentation for AWS SCT and AWS DMS
- DMS Step-by-Step Walkthroughs
- DMS Best Practices
- DMS sample database on GitHub
- Related blog post: Use SQL to Map Users, Roles, and Grants from Oracle to PostgreSQL