AWS Database Blog

Synchronizing a Backup on-premises Db2 Server with Amazon RDS for Db2
In this post, we provide guidance on implementing a hybrid architecture where a self-managed Db2 instance remains synchronized with Amazon RDS for Db2 via continuous archive log application, ensuring organizations maintain strategic deployment options without compromising the advantages of cloud-native managed services.

Automated parameter and option group change monitoring in Amazon RDS and Amazon Aurora
In this post, you will learn how to build a serverless monitoring solution sending detailed alerts whenever Amazon RDS parameter groups are modified, including which databases are affected and whether a restart is required.

Export Amazon SimpleDB domain data to Amazon S3
As AWS continues to evolve its services to better align with customer needs and modern workloads, we’re excited to introduce a new export functionality for Amazon SimpleDB . By using this feature, you can export domain data to Amazon S3 in JSON format, unlocking new opportunities for long-term storage, and migration to purpose-built databases. The export generates a complete JSON representation of Amazon SimpleDB data. In this post, we walk you through how to use the new export functionality, highlight best practices, and share monitoring functionality to help you make the most of it.

Migrate Cloud SQL for MySQL to Amazon Aurora and Amazon RDS for MySQL Using AWS DMS
In this post, we demonstrate how to migrate from Cloud SQL for MySQL 8+ to Amazon RDS for MySQL 8+ or Amazon Aurora MySQL–Compatible using AWS DMS over an AWS Site-to-Site VPN. We cover preparing the source and target environments, exemplifying cross-cloud connectivity, and setting up DMS tasks.

From bottlenecks to breakthroughs: Dutchie’s database migration journey
Dutchie, a leading technology platform serving the cannabis industry, manages critical operations for thousands of dispensaries across multiple states, processing millions of transactions annually. In this post, we explore how Dutchie successfully navigated the challenges of migrating mission-critical workloads to Amazon RDS for SQL Server in preparation for 4/20 week in 2025.

Automating Amazon RDS backup and maintenance windows for Daylight Saving Time shifts
In this post, you’ll learn how to deploy a serverless solution using AWS CloudFormation that automatically adjusts RDS maintenance and backup windows for DST transitions.

Set up and troubleshoot IAM database authentication in AWS DMS
In this post, we demonstrate how to configure IAM database authentication in AWS Database Migration Service (AWS DMS). You’ll also learn the structured troubleshooting approach you follow to address the errors when configuring IAM database authentication with AWS DMS

Replicate spatial data using AWS DMS and Amazon RDS for PostgreSQL
In this post, we show you how to migrate spatial (geospatial) data from self-managed PostgreSQL, Amazon RDS for PostgreSQL, or Amazon Aurora PostgreSQL-Compatible Edition to Amazon RDS for PostgreSQL or Amazon Aurora PostgreSQL using AWS DMS. Spatial data is useful for applications such as mapping, routing, asset tracking, and geographic visualization. We walk through setting up your environment, configuring AWS DMS, and validating the successful migration of spatial datasets.
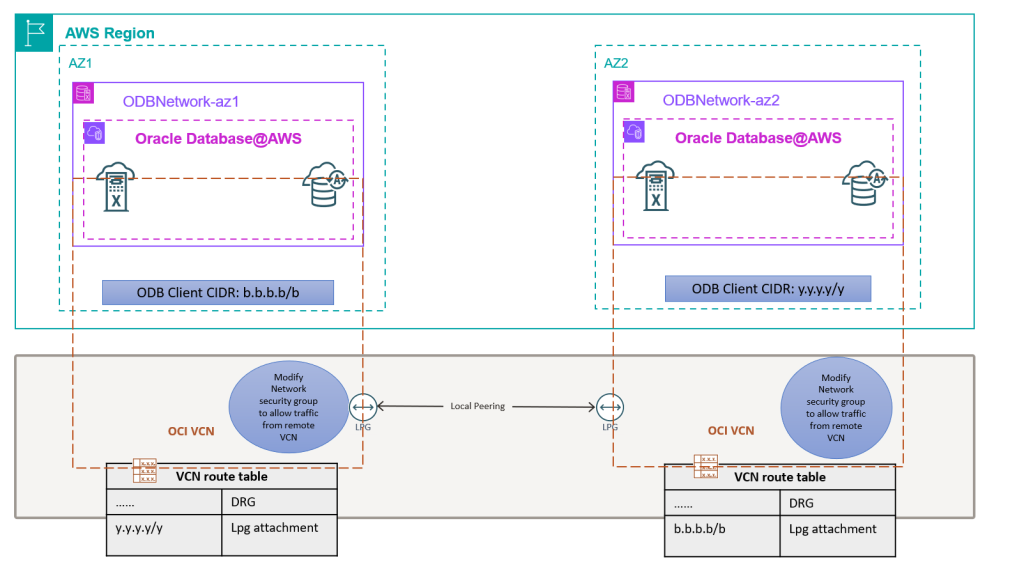
Well-Architected design for resiliency with Oracle Database@AWS
Oracle Database@AWS delivers enterprise-grade database capabilities through database services that use Oracle Exadata infrastructure managed by Oracle Cloud Infrastructure (OCI) within Amazon Web Services (AWS) data centers. High availability (HA) and disaster recovery (DR) options are important aspects to consider when migrating or deploying your critical database in Oracle Database@AWS to help make sure the architecture can meet the service level agreement (SLA) of the application. This post will help you implement and maintain Data Guard configurations that follow Oracle’s Maximum Availability Architecture (MAA) best practices and the AWS Well-Architected Framework. We will show how to select the right network architecture and configure Data Guard associations for both cross-AZ and cross-Region deployments, making sure your applications maintain seamless connectivity during role transitions.

Resilience testing on Amazon ElastiCache with AWS Fault Injection Service
In this post, we guide you on how to run resilience tests on Amazon ElastiCache using AWS Fault Injection Service and how you can use it to strengthen the resilience strategy of your application.