AWS Database Blog
Improve Aurora PostgreSQL throughput by up to 165% and price-performance ratio by up to 120% using Optimized Reads on AWS Graviton4-based R8gd instances
AWS has been continuously improving the performance and price-performance ratio of AWS Graviton processors and Amazon Aurora with each new release. You can now use Graviton4-based R8gd (with local NVMe-based SSD) instances with Amazon Aurora PostgreSQL-Compatible Edition featuring Optimized Reads-enabled tiered cache and temporary objects. By upgrading from Graviton2-based db.r6g to Graviton4-based db.r8gd, you can achieve up to 165% higher throughput, up to 120% better price-performance ratio, and improve the application response time by up to 80%.
In this post, we demonstrate how your workloads can benefit from upgrading Graviton2-based R6g and R6gd instances to Graviton4-based R8gd instances with Aurora PostgreSQL 17.5 on Aurora I/O-Optimized using an Optimized Reads-enabled tiered cache.
Scaling database cache using Aurora PostgreSQL with Optimized Reads
Startups, mid-size companies, and enterprises running applications, ranging from generative AI to internet-scale and real-time analytics, have rapidly growing data volumes. As the working dataset exceeds database memory, the database starts reading from storage instead of memory, which can increase query latencies, make them unpredictable, reduce throughput, increase I/O costs, and ultimately delay business processes and deliver a sub-par user experience.
The Aurora I/O-Optimized configuration provides a way to improve write throughput for I/O-intensive applications while keeping the price predictable. But maintaining consistently low read latencies when the working dataset exceeds database memory can be challenging. To overcome this, you can scale up the database instances to increase memory and keep the working dataset cached. However, when other hardware resource utilization remains low, this approach isn’t cost-effective.
To address this common scenario, Aurora offers I/O-Optimized with Optimized Reads-enabled tiered cache. This feature extends the database caching capacity by up to 5 times the instance memory using local NVMe SSDs, enabling more data to be cached locally and reducing network storage access. Aurora Optimized Reads-enabled tiered cache delivers faster query response times with predictable latency, higher throughput, and better price-performance ratio.
Customers are already seeing significant benefits from the Amazon Aurora Optimized Reads-enabled tiered cache. For example, Mindbody achieved substantial results across multiple metrics: 50% CPU reduction, 90% decrease in read IOPS, up to 59x faster query execution, and 23% cost savings. For more information, see How Mindbody improved query latency and optimized costs using Amazon Aurora PostgreSQL Optimized Reads.
In another success story, Claroty improved their system’s performance by reducing API request times from approximately 30 seconds to under one second on average, while cutting operational costs by 50%. For more information, see How Claroty Improved Database Performance and Scaled the Claroty xDome Platform using Amazon Aurora Optimized Reads.
Optimized Reads-enabled tiered cache can also enhance your generative AI/vector workloads by accelerating vector operations and reducing latency for vector similarity search. For more information, see Improve the performance of generative AI workloads on Amazon Aurora with Optimized Reads and pgvector.
Benefits of Aurora PostgreSQL 17 with Optimized Reads and Graviton4 R8gd
Aurora PostgreSQL 17 major version introduced significant performance improvements for I/O-Optimized cluster configurations with enhancements to database write path, including:
- Smarter storage batching algorithms that dynamically adjust flush sizes and frequencies based on real-time storage performance.
- Optimized writes by minimizing interference from background maintenance tasks and delivering more consistent performance with improved commit latency and throughput.
- Improved allocation of Write-Ahead Log (WAL) stream numbers, resulting in increased throughput for write-heavy workloads on the Graviton4-based instances.
Aurora PostgreSQL 17.4 allows you to dynamically adjust temporary objects storage size up to six times of instance memory.
Aurora PostgreSQL 17.5 also allows you to store up to 256 TiB in a single database cluster, making it straightforward to handle application scaling and data management in a single cluster.
With Graviton4-based R8gd, you can scale your Aurora PostgreSQL with Optimized Reads up to 48xl (from the previous maximum of 32xl), which gives 192 vCPU in a 1:1 core ratio (192 CPU cores), 50 Gigabit of network, 1.5 TiB of instance memory, and 10.4 TiB of local NVMe capacity. The local NVMe SSD capacity extends the local database cache up to 7.34 TiB (using default shared buffer).
Aurora PostgreSQL 17 optimizations combined with Graviton4 R8gd enhanced hardware specifications deliver superior performance for the following use cases:
- Internet scale applications such as payments processing, billing, e-commerce with strict performance SLAs.
- Real-time reporting dashboards that run hundreds of point queries for metrics/data collection.
- Generative AI applications with the pgvector extension to search exact or nearest neighbors across millions of vector embeddings.
For more information about Aurora Optimized Reads capabilities and usage recommendations, see Improving query performance for Aurora PostgreSQL with Aurora Optimized Reads.
For more information about Aurora PostgreSQL on AWS Graviton4-based instances, see Achieve up to 1.7 times higher write throughput and 1.38 times better price performance with Amazon Aurora PostgreSQL on AWS Graviton4-based R8g instances.
To demonstrate the hardware and software enhancements, we conducted comprehensive benchmarking using industry-standard workloads. In the following topics, we explore the benchmark methodology, the environment architecture, and the gains.
Benchmark workload and methodology
We used HammerDB, an open source database load testing and benchmarking tool that generates consistent and repeatable test scenarios. HammerDB simulates online transaction processing (OLTP) workloads across various database engines, including PostgreSQL. The TPROC-C workload in HammerDB is modeled after the TPC-C benchmark, which executes multiple transaction types, including read and write operations with concurrent sessions.
Test environment configuration
We used HammerDB to load the database and run workloads on an Amazon Aurora PostgreSQL 17.5 cluster. The warehouse configuration generated database sizes of approximately 128GB for small workloads (2xlarge) and 1,024GB for medium workloads (16xlarge) sizes, with both sizes exceeding the instance memory. We used concurrency as two times the vCPU with 10 minutes ramp-up and 20 minutes run in a 2xlarge (small workload) and 16xlarge (medium workload).
The HammerDB ran on Amazon Elastic Compute Cloud (Amazon EC2) using the same size and Availability Zone as the database instance.
Metrics
We measured and compared HammerDB new orders per minute (NOPM) throughput and application response time.
Instances capacity
The following table summarizes the instance types and hardware specifications used in this benchmark.
| Instance Size | Processor | vCPU | Cores | GHz | Memory (GiB) | DRAM | Instance Storage (GB) – NVMe SSD | Optimized Reads-enabled Tiered Cache size (GB) | Optimized Reads-enabled Temporary object size (GB) | Network Baseline/Burst (Gbps) |
|---|---|---|---|---|---|---|---|---|---|---|
| db.r6g.2xlarge* | Graviton2 | 8 | 8 | 2.5 | 64 | DDR4 | N/A | N/A | N/A | 2.5 / 10 |
| db.r6gd.2xlarge* | Graviton2 | 8 | 8 | 2.5 | 64 | DDR4 | 1 x 474 (474) | 262 | 137 | 2.5 / 10 |
| db.r8gd.2xlarge* | Graviton4 | 8 | 8 | 2.8 | 64 | DDR5 | 1 x 474 (474) | 262 | 137 | 3.75 / 15 |
| db.r6g.16xlarge | Graviton2 | 64 | 64 | 2.5 | 512 | DDR4 | N/A | N/A | N/A | 25 |
| db.r6gd.16xlarge | Graviton2 | 64 | 64 | 2.5 | 512 | DDR4 | 2 x 1,900 (3,800) | 2,105 | 1,099 | 25 |
| db.r8gd.16xlarge | Graviton4 | 64 | 64 | 2.8 | 512 | DDR5 | 2 x 1,900 (3,800) | 2,105 | 1,099 | 30 |
* These instances have a baseline bandwidth and can use a network I/O credit mechanism to burst beyond their baseline bandwidth on a best effort basis. Other instance types can sustain their maximum performance indefinitely. For more information, see Amazon EC2 instance network bandwidth. For details about instance specifications, see Specifications for Amazon EC2 memory optimized instances.
Benchmark environment’s architecture
The following diagram illustrates the benchmark environment’s architecture, where we deployed EC2 instance running HammerDB (driver) to benchmark the Aurora cluster (target) with one writer and one reader instance, although no workload was running on the reader.
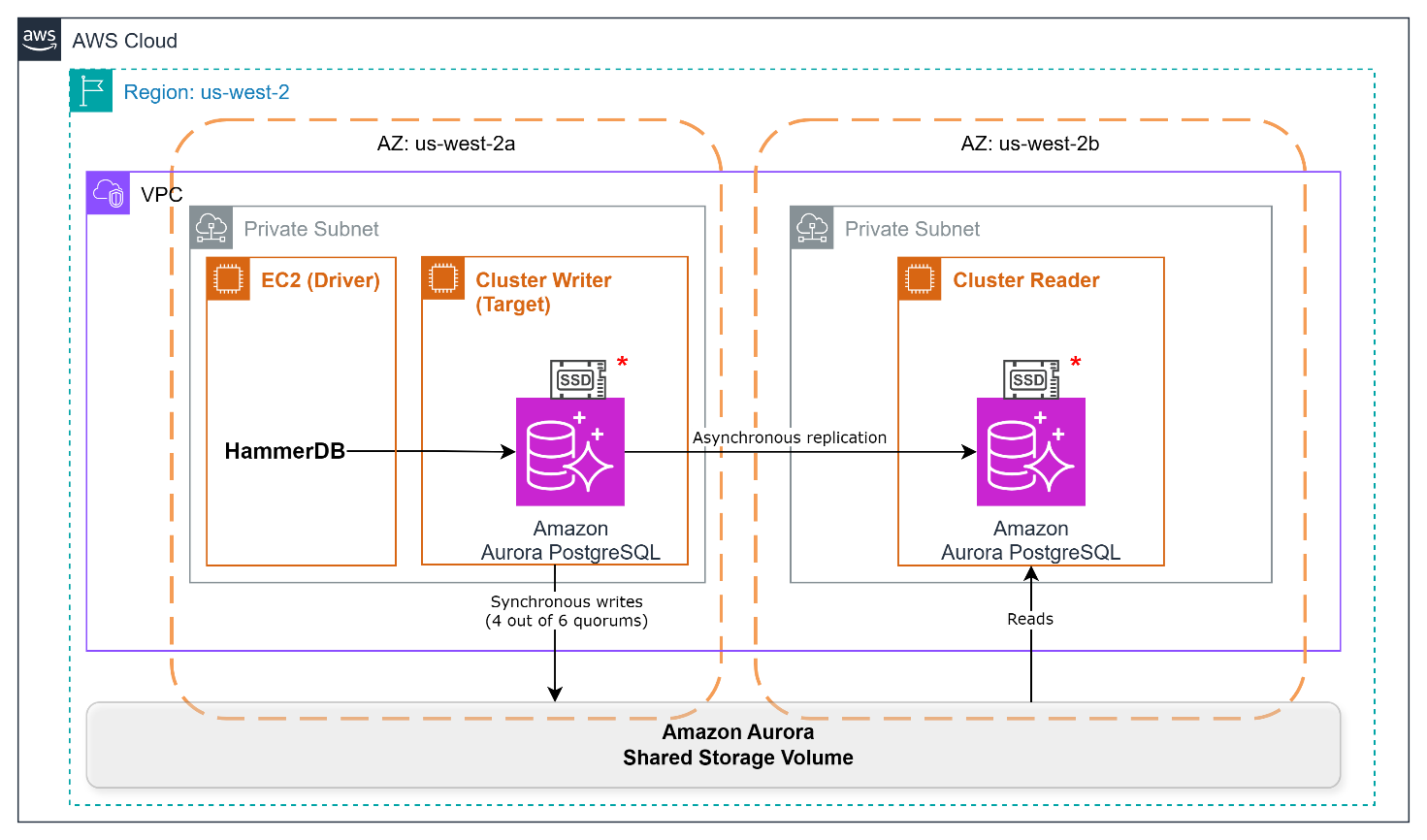
Note that Graviton-4 based db.r8gd and Graviton2-based db.r6gd instances include local NVMe SSD storage, whereas db.r6g instances do not.
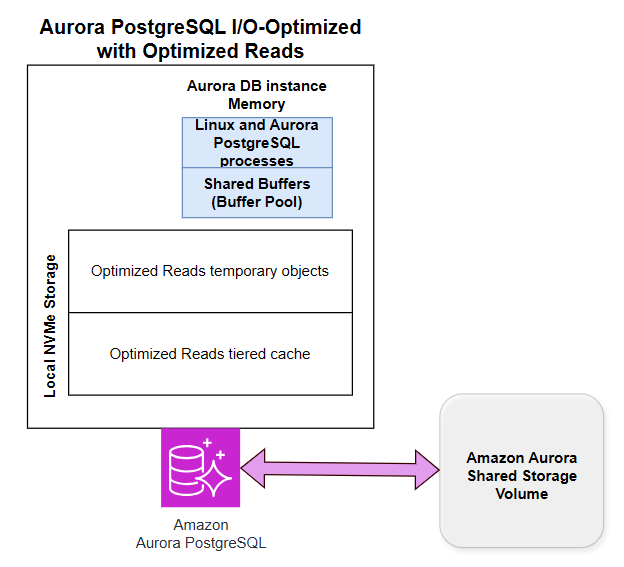
The following diagram illustrates the architecture for Aurora PostgreSQL I/O-Optimized with local NVMe storage, Optimized Reads-enabled tiered cache, and temporary objects.
Benchmark comparison
When evaluating and comparing Aurora DB instance class types, you must consider multiple factors to make an informed decision. Key areas to assess include throughput, application response time, and price-performance ratios. By examining these aspects, you can have a broader understanding of the performance and price-performance ratio gains, and how the application performance can benefit with a lower and more consistent response time.
In this post, we discuss two possible upgrade paths and the benefits from each path.
- Enabling Aurora Optimized Reads by using the db.r8gd instances – Shows the benefits you can get from using the Optimized Reads feature and upgrading from db.r6g to db.r8gd instance.
- Upgrading from db.r6gd to db.r8gd instances – Shows the benefits you get from upgrading an existing Aurora Optimized Reads cluster from a db.r6gd to a db.r8gd instance.
Throughput comparison
We measure database throughput in NOPM, which is a performance metric that measures how many new orders per minute the database can process within a specified time period. This metric evaluates the database’s processing capacity across multiple dimensions: CPU processing speed, query execution time, I/O, network, and memory speed.
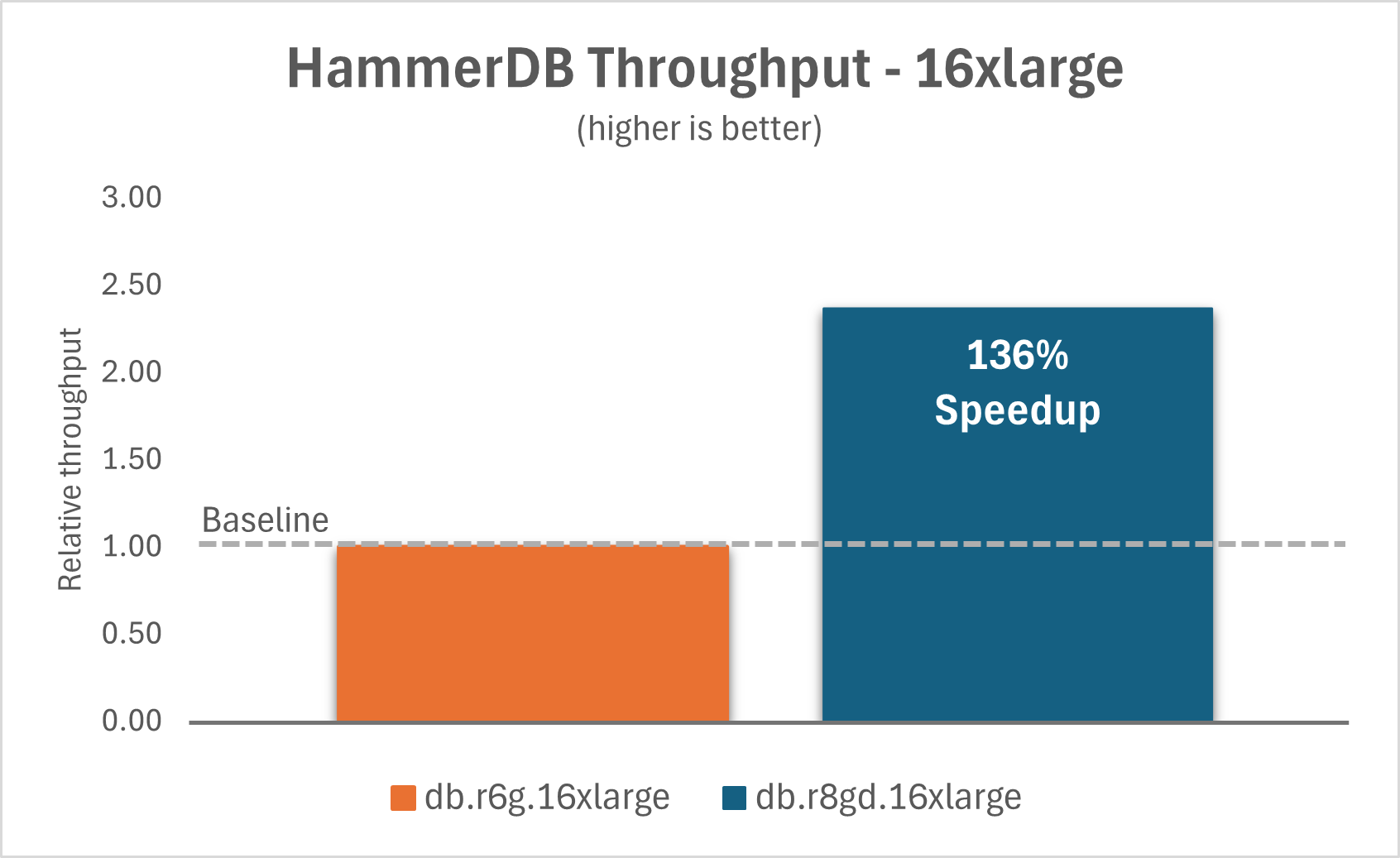
The following charts show that by upgrading Aurora PostgreSQL I/O-Optimized from db.r6g instances to db.r8gd instances with Optimized Reads, you can achieve a 165% improvement in throughput for the 2xlarge instance and a 136% improvement for the 16xlarge instance.
 |
 |
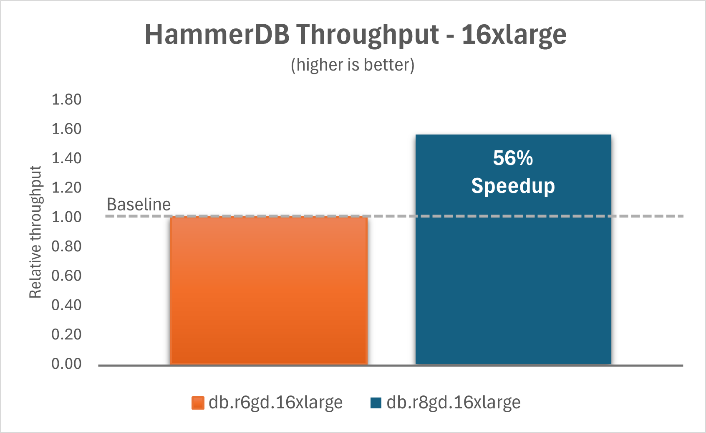
The following charts show that by upgrading Aurora PostgreSQL I/O-Optimized with Optimized Reads on db.r6gd instances to db.r8gd instances, you can achieve a 68% improvement in throughput for the 2xlarge instance and a 56% improvement for the 16xlarge instance.
 |
 |
Price-performance ratio comparison
This metric combines an instance’s performance capabilities with its monthly cost to determine the value (performance) you receive for each dollar invested. We calculated this ratio using HammerDB NOPM divided by the instance’s on-demand monthly price on the US West (Oregon) AWS Region. A higher ratio indicates better value for your investment, because you’re achieving more database transactions per dollar.
This measurement is particularly valuable when planning infrastructure costs because it helps you:
- Optimize your operational expenses while maintaining required performance levels.
- Make data-driven decisions about instance type and size.
- Balance performance requirements with budget planning.
The following charts show that by upgrading Aurora PostgreSQL I/O-Optimized from db.r6g instances to db.r8gd instances with Optimized Reads, you can achieve a 120% improvement in price-performance ratio for the 2xlarge instance and a 96% improvement for the 16xlarge instance.
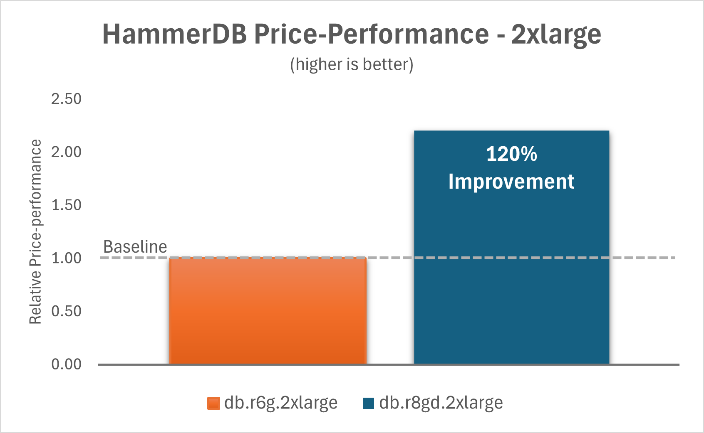 |
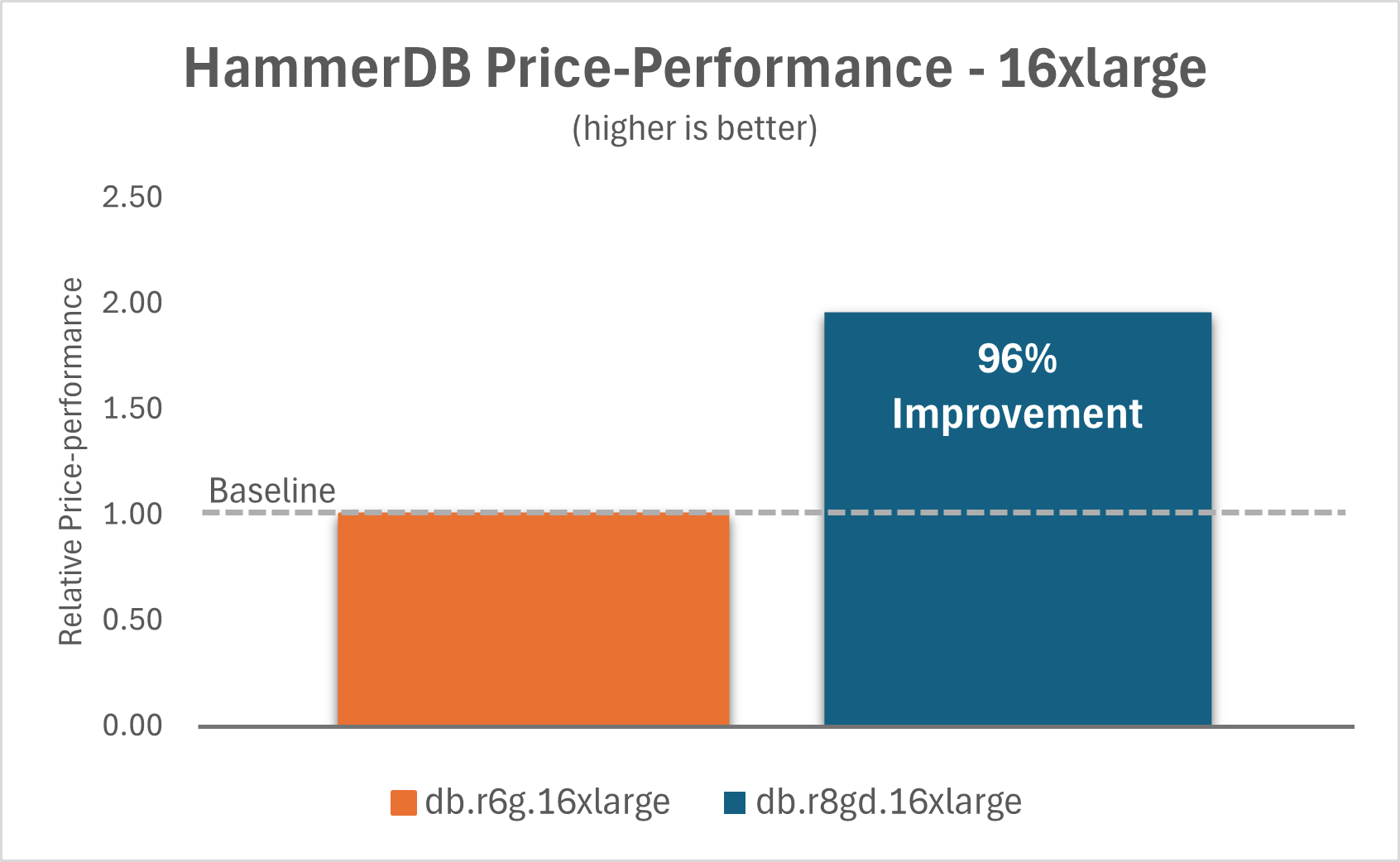 |
The following charts show that by upgrading Aurora PostgreSQL I/O-Optimized with Optimized Reads on db.r6gd instances to db.r8gd instances, you can achieve a 68% improvement in price-performance ratio for the 2xlarge instance and a 56% improvement for the 16xlarge instance.
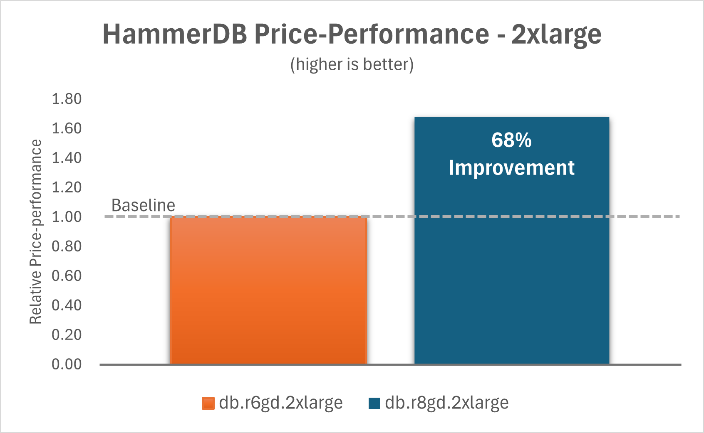 |
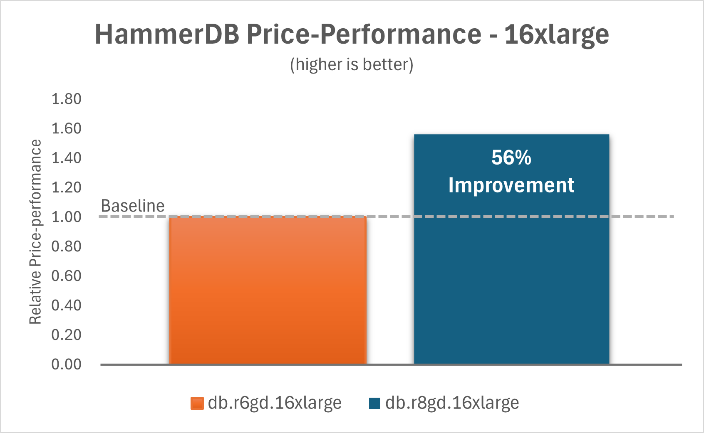 |
Response time comparison
Maintaining low, consistent 99th percentile (p99) response time is critical in high-performance environments. The p99 represents the response time in which 99% of the transactions are complete. HammerDB response time measures how long it takes for the database and application to process and respond to a new order transaction in the TPROC-C workload.
The p99 metric specifically captures the performance of the 1% outlier. For example, if 99 ecommerce transactions complete in 200ms but one takes 20 seconds, the average is 398ms and can be reasonable, but p99 is over 19 seconds which can be problematic. Imagine a peak sales season, this 1% problematic case can be hundreds or thousands of users who may abandon their purchases, impacting revenue and customer experience. During these peak times, p99 response time consistency is also important because it measures whether your worst-case performance remains predictable over time. A system with p99 response time that fluctuates between a few milliseconds to hundreds of milliseconds constantly triggers a poor and inconsistent user experience.
Aurora Optimized Reads-enabled tiered cache addresses these issues by reducing IO, storage network, and CPU utilization through larger local caching, providing sub-millisecond read latency and improving p99 consistency.
The following charts show that by upgrading Aurora PostgreSQL I/O-Optimized from db.r6g instances to db.r8gd instances with Optimized Reads, you can improve the p99 response time by 80% for the 2xlarge instance and by 77% for the 16xlarge instance.
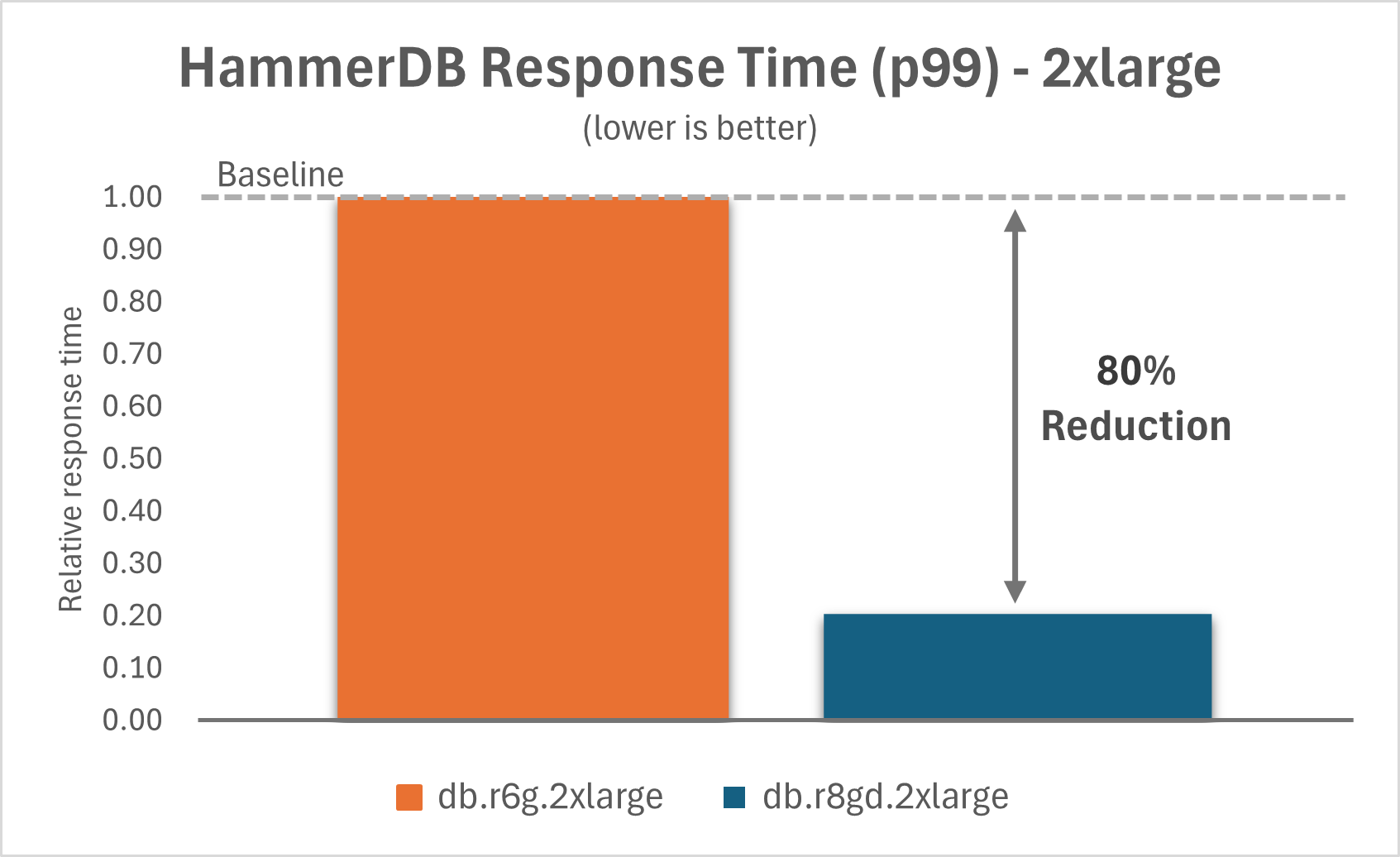 |
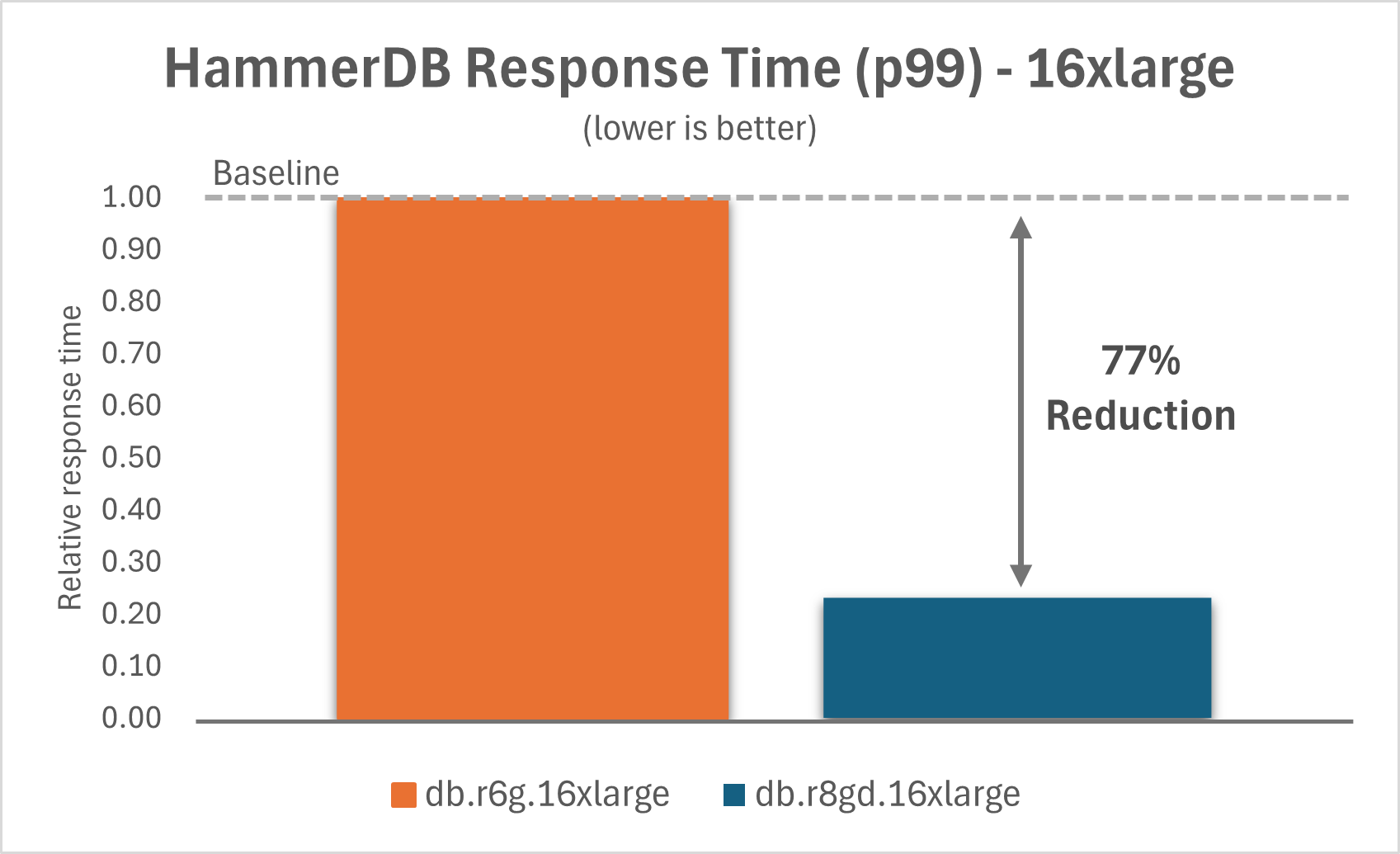 |
The db.r8gd maintains lower response time with superior consistency resulting in more predictable query execution times and improved performance variability. The following chart shows a snippet of HammerDB response time (p99) over time with lower fluctuation.
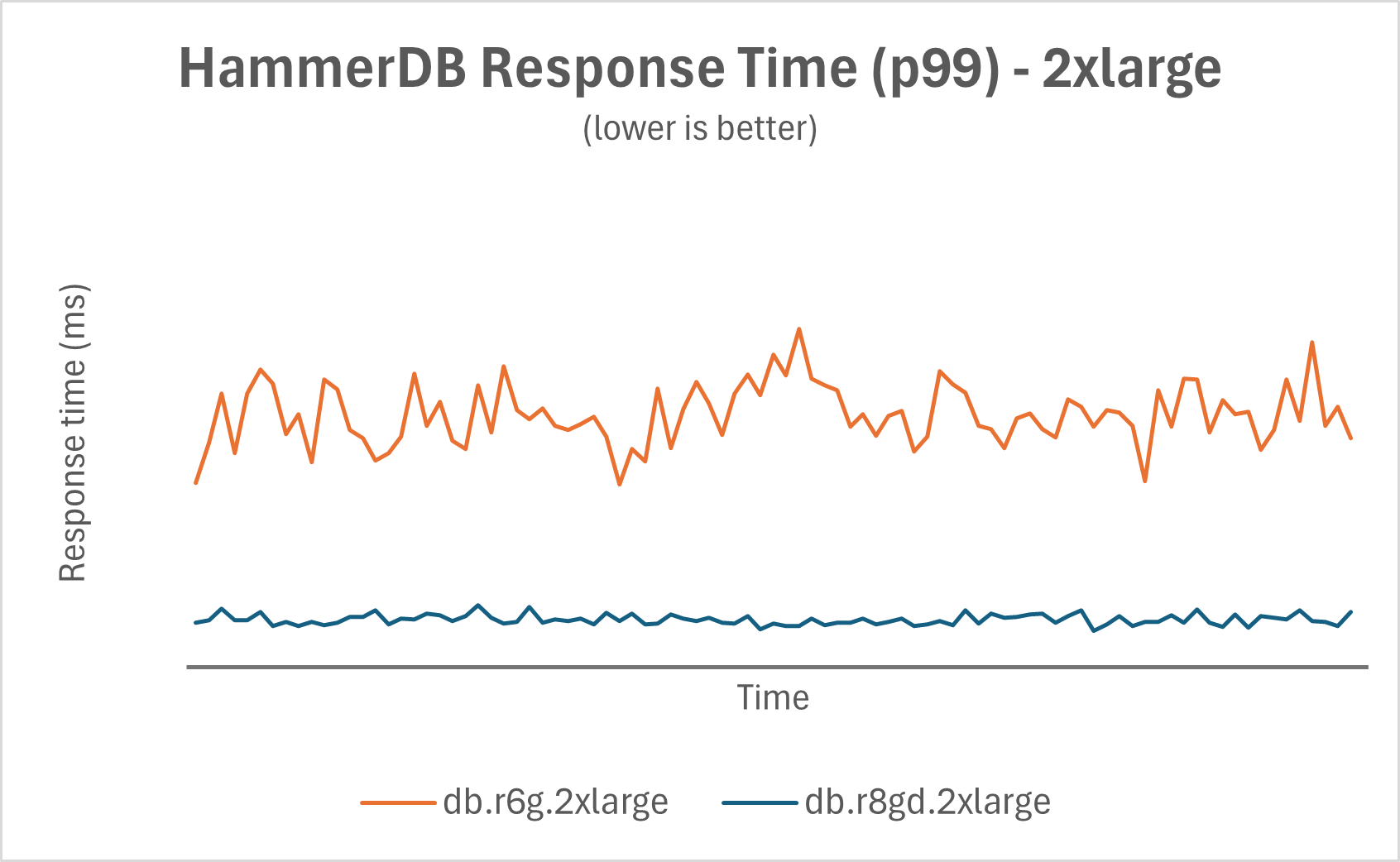 |
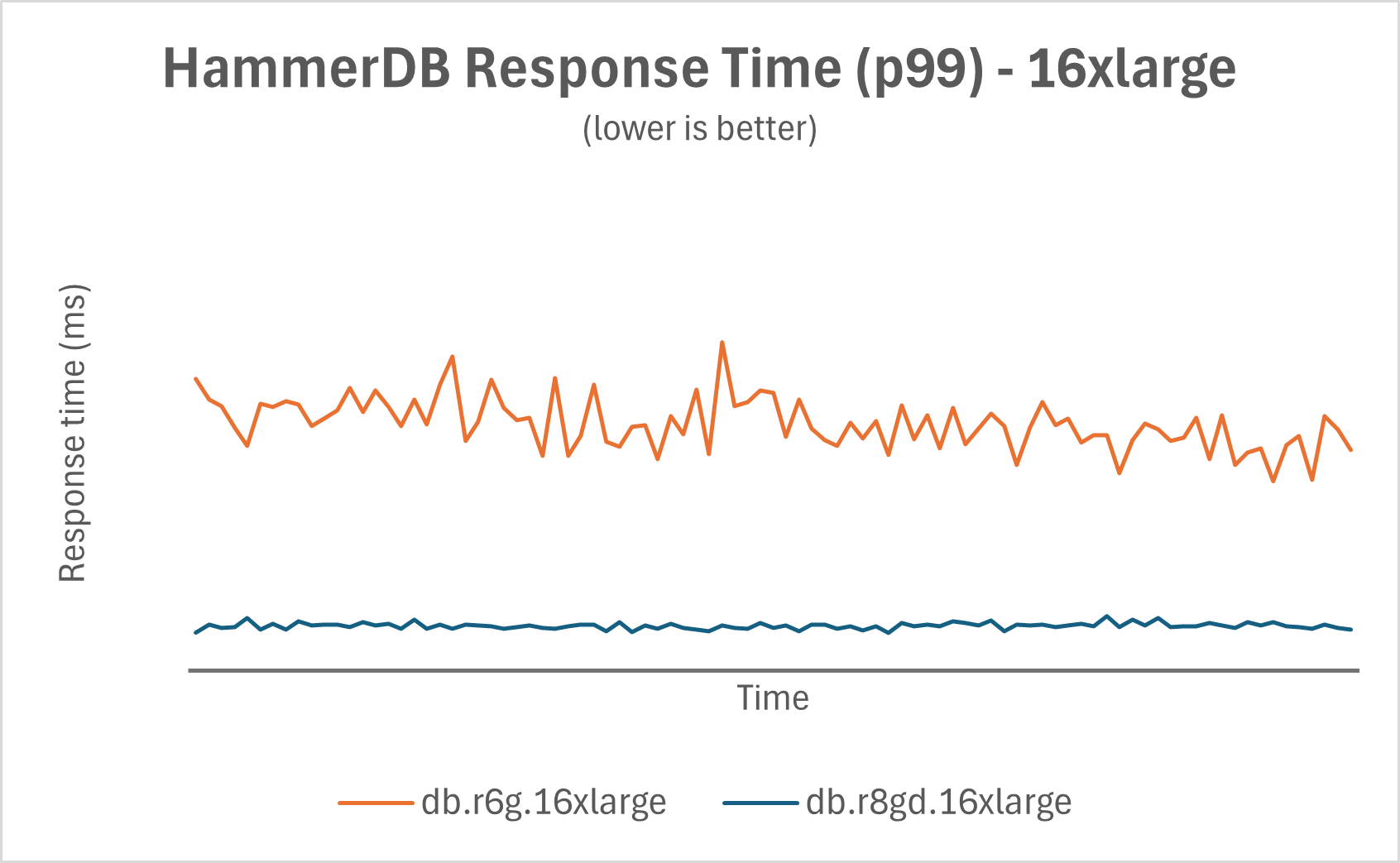 |
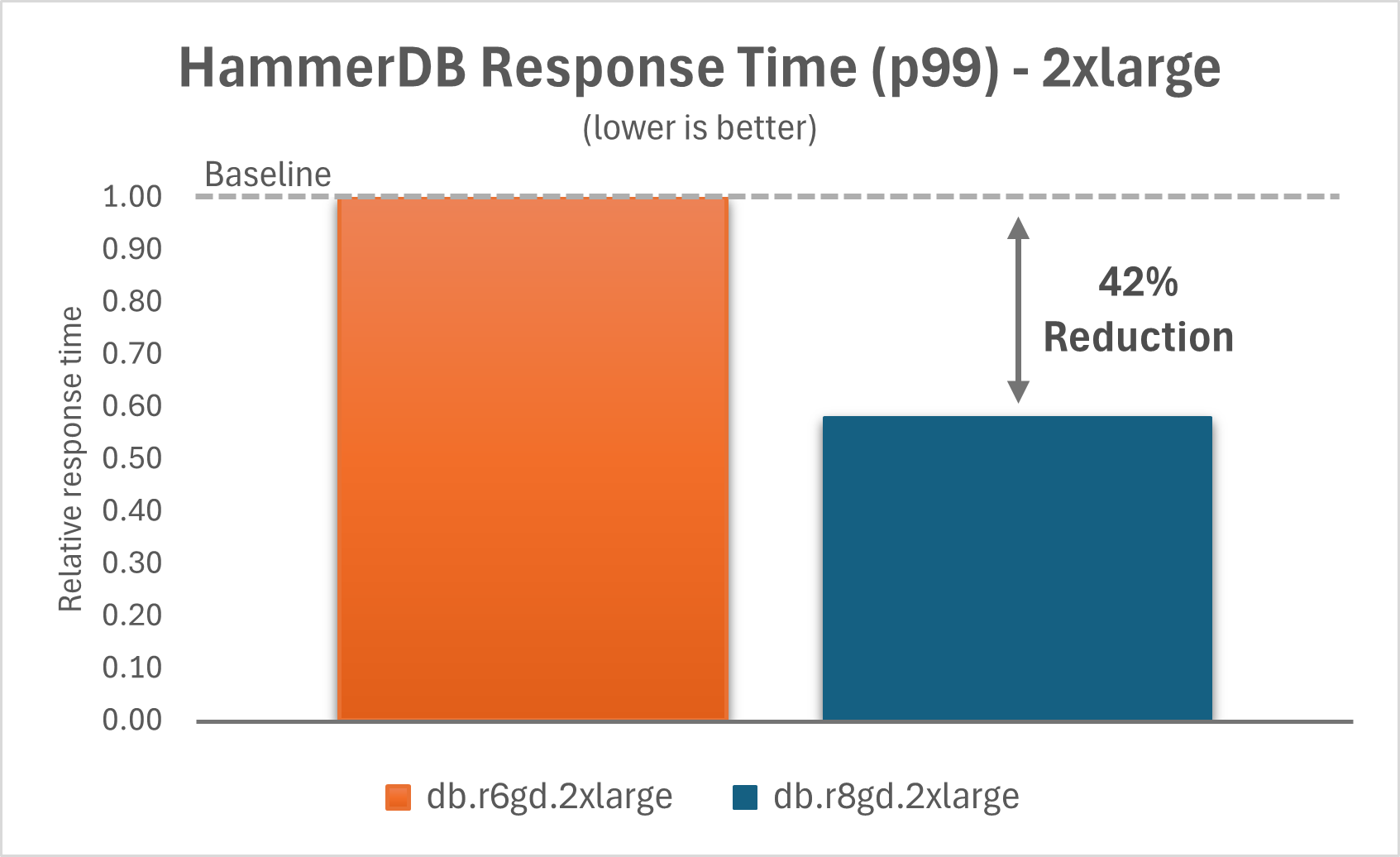
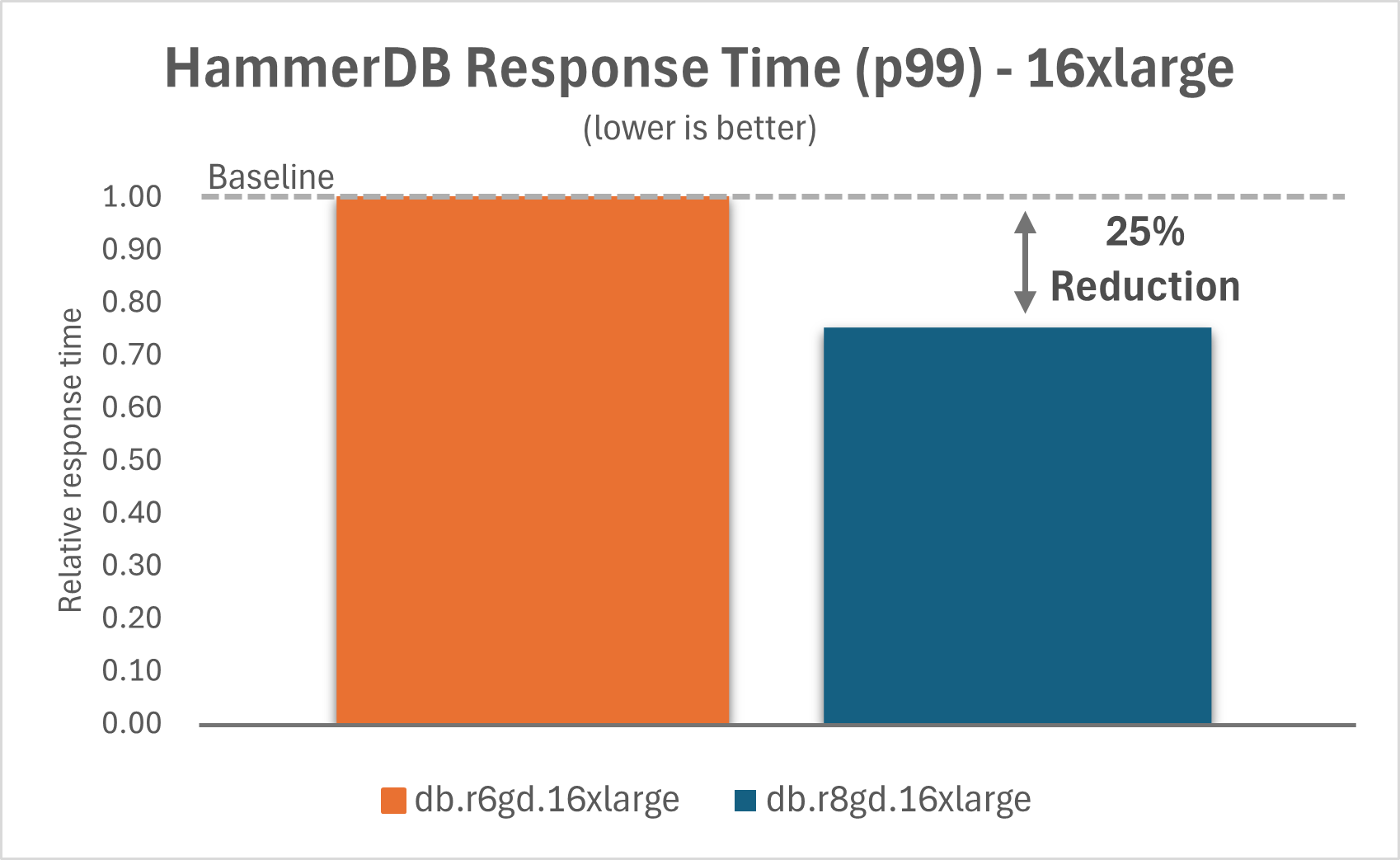
The following charts show that by upgrading Aurora PostgreSQL I/O-Optimized with Optimized Reads on db.r6gd instances to db.r8gd instances, you can improve the p99 response time by 42% for the 2xlarge instance and by 25% for the 16xlarge instance.
 |
 |
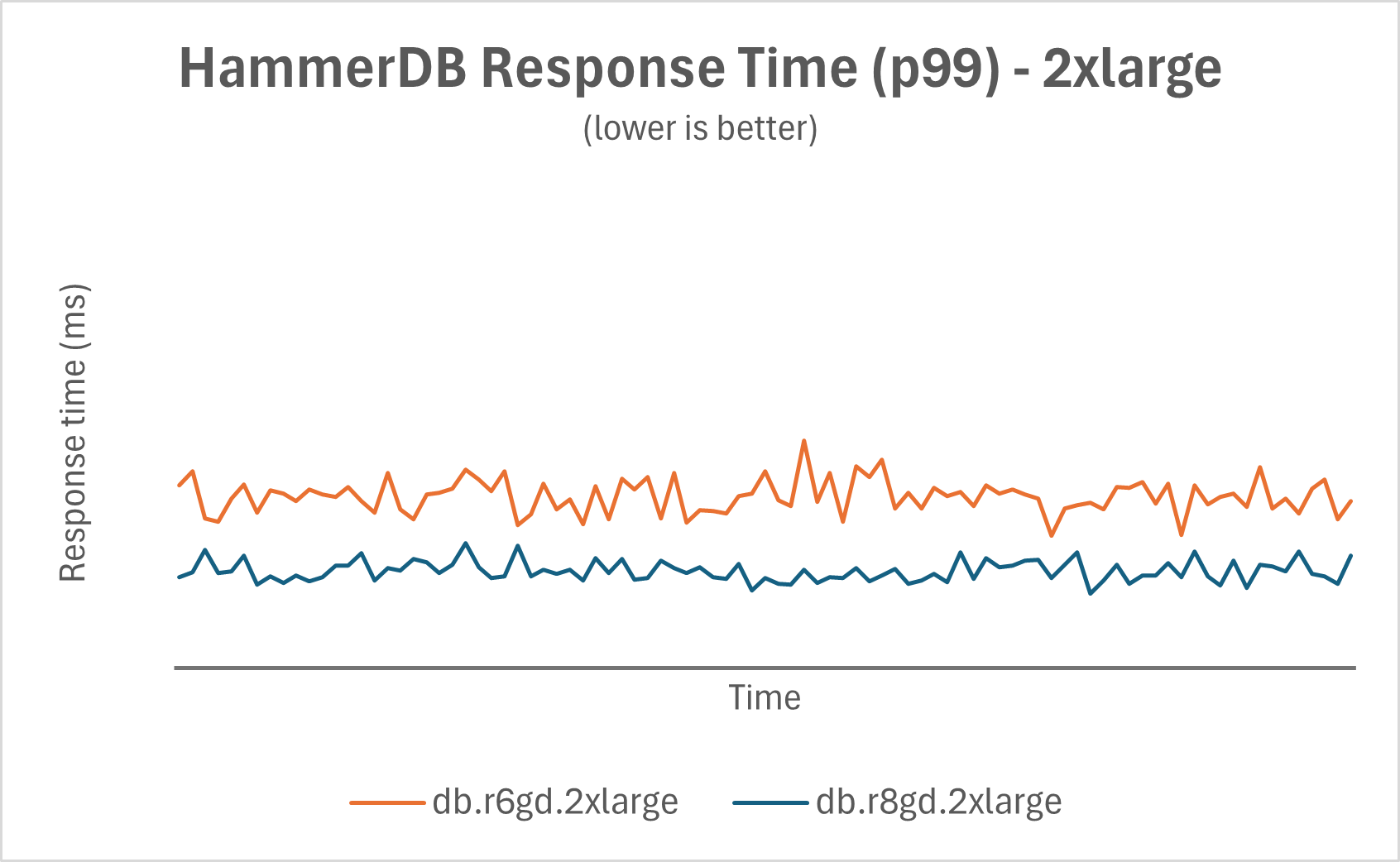
The following chart shows a snippet of HammerDB response time (p99) over time.
 |
 |
Enable Aurora Optimized Reads with tiered cache
After understanding the performance benefits of Aurora PostgreSQL I/O-Optimized with Optimized Reads on db.r8gd instances, let’s walk through how to start using Aurora Optimized Reads-enabled tiered cache.
For new deployments
You can create an Aurora PostgreSQL cluster using the Amazon RDS Console or AWS CLI or RDS API with I/O-Optimized storage and use the Optimized Reads instance class (db.r8gd), which indicates the instance provides local NVMe SSD storage.
For existing clusters
For existing Aurora PostgreSQL clusters, you can upgrade to db.r8gd instances through an instance class modification with minimal downtime by using Aurora high availability features with the following options:
- Create or upgrade the reader instance and then promote the reader to primary.
- Use Amazon RDS blue/green deployments. Refer to Creating a blue/green deployment in Amazon Aurora and New – Fully managed Blue/Green Deployment in Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL.
To disable the Optimized Reads-enabled tiered cache, modify your instance to a type without local NVMe SSD storage. For more information, see Performance and scaling for Amazon Aurora PostgreSQL.
Aurora PostgreSQL I/O-Optimized with an Optimized Reads-enabled tiered cache on db.r8gd is available for Aurora PostgreSQL version 17.4 and higher, 16.3 and higher, 15.7 and higher, 14.12 and higher, in AWS Regions where Optimized Reads instance classes are supported. For more information, see Amazon Aurora DB instance classes.
Conclusion
In this post, we shared the performance, price-performance ratio, and application response time improvements of Aurora PostgreSQL 17.5 with Optimized Reads-enabled tiered cache using the R8gd instance. We also shared the features and enhancements offered in the Aurora PostgreSQL 17 major, 17.4 minor and 17.5 minor versions.
The results show that R8gd instances with Aurora PostgreSQL 17.5 can offer substantial improvements up to 165% higher throughput, up to 120% better price-performance ratio and up to 80% improvement in application response time, while also providing up to 256 TiB of storage space and flexibility of temporary objects storage size adjustments without cluster restart.
The combination of Graviton4-based processors and Aurora PostgreSQL-Compatible with Optimized Reads-enabled tiered cache provides a compelling option for optimizing database performance and query latency for organizations running intensive read and write workloads like internet-scale applications, generative AI applications with pgvector, ecommerce, real-time analytics, financial transactions and billing.
To begin using the Aurora PostgreSQL Optimized Reads-enabled tiered cache with Graviton4-based R8gd, create a new Aurora PostgreSQL cluster or modify an existing cluster through the Amazon RDS Console, AWS CLI, or Amazon RDS API. Select an instance type with local NVMe SSD storage and configure I/O-Optimized storage. For more information, see Improving query performance for Aurora PostgreSQL with Aurora Optimized Reads.