AWS Database Blog
Migrate Oracle reference partitioned tables to Amazon RDS or Aurora PostgreSQL with AWS DMS
Database migrations from Oracle to PostgreSQL are becoming increasingly common as organizations seek to optimize database costs while leveraging the benefits of open-source database solutions. However, these migrations present specific challenges, particularly when dealing with an Oracle-specific feature such as reference partitioning, which doesn’t have a direct equivalent in PostgreSQL.
In this post, we show you how to migrate Oracle reference-partitioned tables to Amazon Relational Database Service (Amazon RDS) for PostgreSQL or Amazon Aurora PostgreSQL-Compatible Edition using AWS Database Migration Service (AWS DMS).
Understanding Oracle reference partitioning
Oracle reference partitioning, introduced in Oracle 11g, allows a child table to inherit the partitioning scheme from its parent table through a referential integrity constraint. This feature ensures that child records are stored physically in the same partition as their corresponding parent records, significantly improving query performance of partition-level joins on these tables. Let’s consider the following reference partition example in Oracle, where a sales tracking system has sales records linked to multiple line items:
- A
SALEStable partitioned bysale_date(monthly) - An
ITEMStable reference-partitioned based on its foreign key relationship toSALES
This reference partitioning design ensures that when sales and the items in those sales are accessed together, the database performs optimized partition-level joins, reducing I/O and improving query performance.
Challenges when replicating reference-partitioned data
When migrating reference-partitioned data to PostgreSQL, you will face the following challenges:
- Feature absence – PostgreSQL doesn’t offer native reference partitioning. Although PostgreSQL supports table partitioning, it doesn’t automatically align child records with their parent partitions.
- Partition key requirements – In PostgreSQL, each partitioned table must be partitioned based on columns in that table. You can’t directly partition a child table based on a parent table’s column.
- Data replication – Oracle’s reference partitioning allows child tables to inherit partitioning schemes from their parents. Though AWS DMS migrates the child table data to PostgreSQL, it replicates it without the partition key data, making standard migration approaches ineffective without special handling.
Solution overview
We demonstrate an approach for migrating Oracle reference-partitioned tables to PostgreSQL. This solution relies on a PostgreSQL BEFORE INSERT trigger that does the following:
- Fetches the partition key from the parent table
- Inserts the record in the child table with the partition key
The trigger ensures that any records inserted in the child table during the migration are stored in the same partition as their corresponding parent, mimicking Oracle’s reference partitioning behavior. Without this trigger, data replication for the child table will fail because of missing partition key information that’s needed for PostgreSQL’s partitioning scheme.
It’s important to note that this trigger-based solution may introduce performance overhead, especially for high-volume transactional workloads. At scale, the trigger can potentially become a performance bottleneck due to the additional database operations required for each insert. Before implementing this solution in a production environment, thoroughly test its performance impact and consider alternative approaches for very large or high-throughput systems.
Prerequisites
You must meet the following prerequisites before proceeding to implement this post’s solution:
- An active AWS account.
- An Oracle instance (for this post, we use Amazon RDS for Oracle) or an on-premises Oracle database.
- An Aurora PostgreSQL or Amazon RDS for PostgreSQL database (for this post, we use Aurora PostgreSQL-Compatible). If you don’t already have an Aurora cluster for your PostgreSQL instance, you can create one. For instructions, see Creating an Amazon Aurora DB cluster.
- AWS DMS set up with a replication instance. For more information, see Getting started with AWS Database Migration Service.
- AWS DMS endpoints for the source and target databases. AWS DMS endpoints provide the connection, data-store type, and location information about your data store.
Create reference-partitioned tables in Oracle database
This post uses an Amazon RDS for Oracle database and creates two sample tables called SALES and ITEMS. In the sample data model, the SALES table is partitioned by sale_date, and the ITEMS table is a reference-partitioned table based on its foreign key relationship with SALES. When a row is inserted into the SALES table, it goes to a specific partition based on its sale_date value. Any corresponding ITEMS rows are automatically placed in the matching partition, maintaining data locality for JOIN operations.
Complete the following steps to create the source tables:
- Create the
SALEStable, partitioned bysale_date: - Create the
ITEMStable with reference partitioning based on theSALEStable: - Use the following procedure to insert sample data:
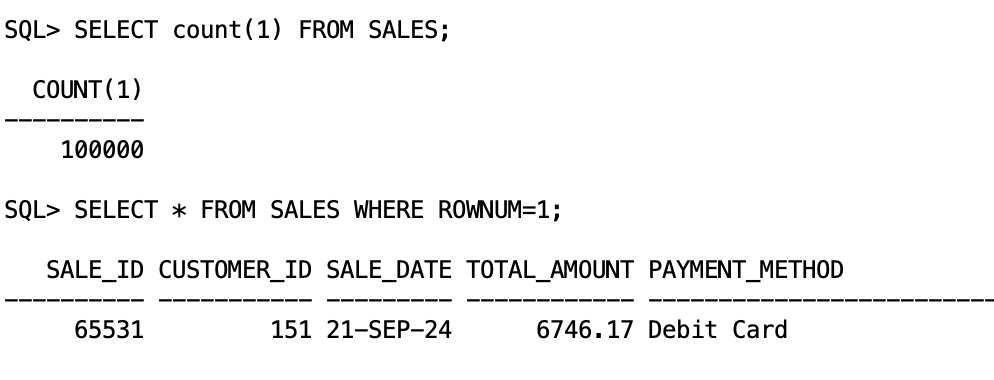
- Verify the data has been inserted:

Create target tables in the PostgreSQL database
Now that we have created our source tables in Oracle, we need to create corresponding target tables in PostgreSQL that will store our migrated data.
- Create a
salestable partitioned bysale_date: - Create an
ITEMStable partitioned bysale_date: - Next, we create the BEFORE INSERT trigger that maintains the relationship between sales and items data in PostgreSQL. This trigger serves as a replacement for Oracle’s reference partitioning:
Configure AWS DMS
Now that you have created your source tables in Oracle database and your target tables in PostgreSQL database, you are ready to migrate your data with the help of AWS DMS. This section of the post walks you through the steps to migrate your data.
Create AWS DMS endpoints for the source and target database. AWS DMS endpoints provide the connection, data store type, and location information about your data store.
For instructions to create your Oracle source endpoint, refer to Using an Oracle database as a source for AWS DMS.
Enable supplemental logging for primary key columns on the Amazon RDS for Oracle source database:
Alternatively, you can add AddSupplementalLogging=true in the source endpoint setting to allow AWS DMS to set up table-level supplemental logging for the Oracle database, if you have not explicitly added supplemental logging.
Create the AWS DMS tasks
Use the following steps to create the AWS DMS task:
- Open the AWS DMS console
- In the navigation pane on the left, under Migrate or Replicate click on Tasks
- Click create task
- For Task identifier, enter an identifiable name
- For Source database endpoint, select the Oracle endpoint you created.
- For Target database endpoint, select the Aurora PostgreSQL endpoint you created.
- Select Task Mode as Provisioned
- For Replication instance, choose the replication instance you created.
- For Migration type, select Migrate.
- For Target table preparation mode, choose Do nothing (because you’ve already created your tables).
- Enable Amazon CloudWatch Logs under the task settings so you can debug issues.
- Under Advanced task settings, set Maximum number of tables to load in parallel to 1. This ensure sequential loading of the tables, which is critical because the
SALEStable must be loaded before theITEMStable for the trigger to work properly. - Under Table mappings, for Editing mode, select JSON editor.
The following JSON shows an example of the table mapping rules for the AWS DMS task. Replace the schema name (“BLOGTEST”) with the name under which you created the table.The load-order setting controls the table migration sequence; tables and views with higher values are loaded first.
SALESis set to “load-order: 2” andITEMSis set to “load-order: 1”, ensuringSALEStable is loaded first. - Uncheck the Premigration assessment checkbox. Though this feature is typically recommended, you disable it as part of this blog post’s solution to simplify the setup process and avoid additional configuration requirements.
- Leave everything else as default and choose Create task to start the task.
Data validation
To verify that your data has been successfully migrated without errors, follow these steps:
- Verify that AWS DMS has replicated the data without any errors or failures.

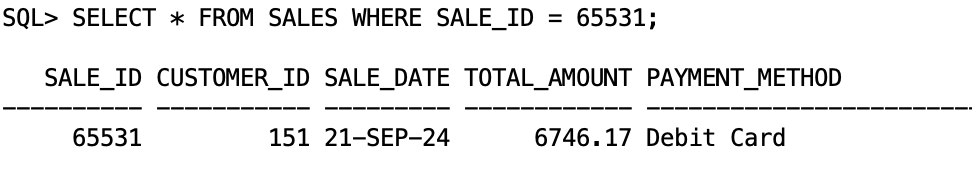
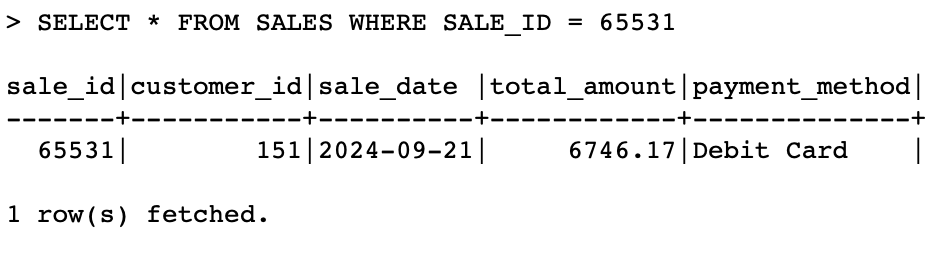
- Execute following queries on target databases to verify data was loaded:

- Compare a sample record between source and target databases:
Clean up
To avoid unnecessary charges, clean up the resources that you built as part of this architecture that you are no longer using:
- Delete the Aurora PostgreSQL cluster.
- Delete the RDS for Oracle database instance.
- Delete the AWS DMS replication instance along with source and target endpoints and tasks.
- If you’ve conducted this test on your existing database and plan to keep it operational, make sure to explicitly drop the test tables from both the source and target databases after you’ve completed this experiment.
Conclusion
Migrating Oracle reference-partitioned tables to PostgreSQL presents unique challenges because of the fundamental difference in how these databases implement partitioning. In this post, we presented a solution that bridges the migration gap between Oracle’s reference partitioning and PostgreSQL’s declarative partitioning by:
- Creating an equivalent partitioning scheme in PostgreSQL.
- Using a trigger mechanism to maintain data colocation.
This approach helps to ensure that your migrated data maintains the same performance benefits of partitioning while smoothly transitioning from Oracle to PostgreSQL by using AWS DMS.
For more information on AWS DMS and its capabilities, refer to AWS DMS documentation. If you have any questions or suggestions about these migration techniques, leave your feedback in the comments.