AWS Database Blog

Recover from a disaster with delayed replication in Amazon RDS for MySQL
July 2023: This post was reviewed for accuracy. Amazon RDS for MySQL now supports a delayed replication, which allows you to set a time period that a replica database lags behind a source database. In a standard MySQL replication configuration, there is minimal delay between the source and the replica. Now you have the option […]
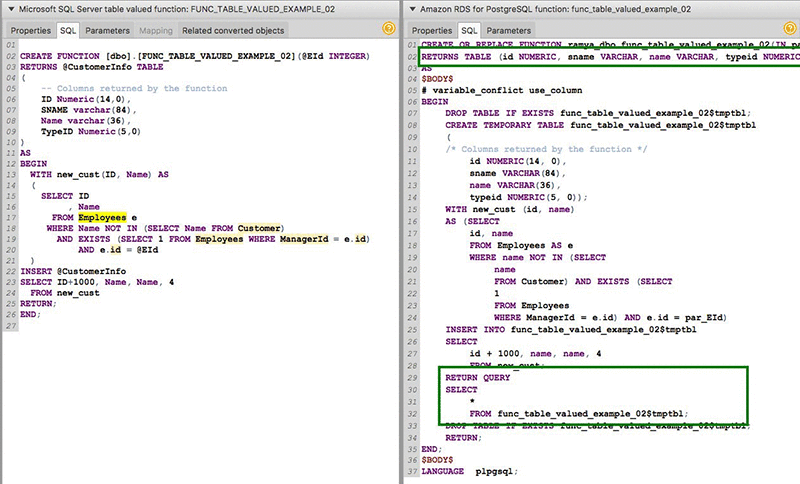
AWS Schema Conversion Tool blog series: Introducing new features in build 617
We are excited to introduce a new version of the AWS Schema Conversion Tool (AWS SCT). This version includes support for table-valued function conversions, additional information in server-level assessment reports, and more. For those of you who are new to AWS SCT, this tool helps convert your existing database schema from one database engine to […]

How SGK simplified the data structure of a highly dynamic workload by migrating from an RDBMS to Amazon DynamoDB
Many database solutions are available today, and choosing the right one for your use case can be difficult. Recently, NoSQL databases have been widely adopted for real-time web applications. Amazon DynamoDB is an example of a NoSQL database that is optimized to yield significant flexibility and performance benefits over a traditional relational database management system […]

How to migrate an application from an on-premises Oracle database to Amazon RDS for PostgreSQL
For years, companies have had to set up their own local databases and maintain the hardware themselves. However, as the cloud infrastructure continues to improve, there’s far less need to own and manage your own hardware. Here at Amazon, we own hundreds (if not thousands) of on-premises databases that over time we have migrated to […]

How to use Amazon Aurora to drive 3x latency improvement for end users
Born on AWS InfoScout was born on AWS, being along for the journey since its inception in 2011. It all started with a single Amazon EC2 instance to collect receipts uploaded from friends and family. Seven years later, we now manage 150+ AWS instances to support our mobile applications, data pipelines, machine learning models, and […]

How to perform ordered data replication between applications by using Amazon DynamoDB Streams
AWS customers use Amazon DynamoDB to store mission-critical data. These customers’ applications make millions of requests per second to individual DynamoDB tables that contain hundreds of terabytes of items. They count on DynamoDB to return results in single-digit milliseconds. In many cases, these applications have requirements to notify other systems and users about specific transactions, […]

How Autodesk Increased Database Scalability and Reduced Replication Lag with Amazon Aurora
Autodesk is a leader in 3D design, engineering, and entertainment software. Autodesk makes software for people who make things. If you’ve ever driven a high-performance car, admired a towering skyscraper, used a smartphone, or watched a great film, chances are you’ve experienced what millions of Autodesk customers are doing with their software. Autodesk has successfully […]

How to plan and optimize Amazon Aurora with MySQL compatibility for consolidated workloads
Amazon Aurora with MySQL compatibility is a popular choice for customers looking to consolidate database workloads. Aurora MySQL is a relational database engine that combines the speed and reliability of high-end commercial databases with the simplicity and cost-effectiveness of open-source databases. It also delivers up to five times the throughput of the standard MySQL community […]
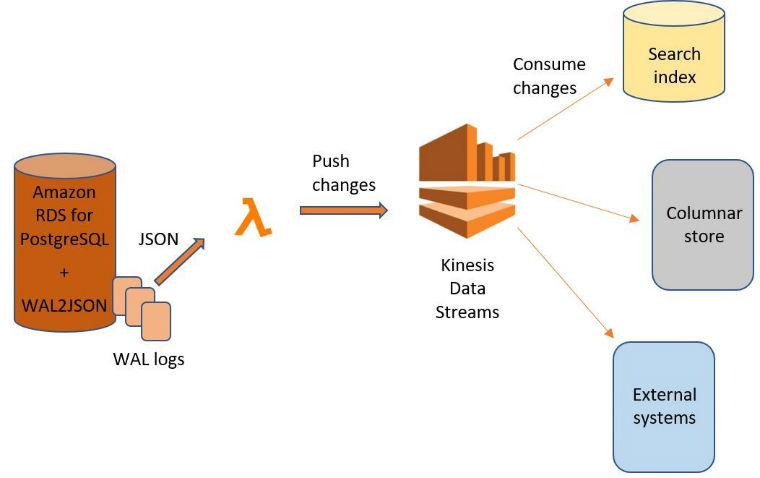
Stream changes from Amazon RDS for PostgreSQL using Amazon Kinesis Data Streams and AWS Lambda
In this post, I discuss how to integrate a central Amazon Relational Database Service (Amazon RDS) for PostgreSQL database with other systems by streaming its modifications into Amazon Kinesis Data Streams. An earlier post, Streaming Changes in a Database with Amazon Kinesis, described how to integrate a central RDS for MySQL database with other systems […]

Best practices for migrating RDS for MySQL databases to Amazon Aurora
MySQL is the most popular open-source database in the world. However, many customers find that the undifferentiated heavy lifting of backups, high availability, and scaling of MySQL databases to be complex, time-consuming, or both. This is one of the leading reasons why customers move their existing MySQL footprint to Amazon RDS for MySQL. Amazon RDS […]