AWS Database Blog
Resetting your graph data in Amazon Neptune in seconds
As an enterprise application developer building graph applications with Amazon Neptune, you may want to delete and reload your graph data on a regular basis to make sure you’re working with the latest changes in your data, such as new relationships between nodes, or to replace test data with production data. In the past, you either had to determine the difference between large datasets and insert incremental data into your graphs, or delete the entire graph database and create new Neptune clusters to load your data. These processes are time consuming and require additional development overhead, such as client changes and policy configurations for the new cluster. Now, with Neptune engine release 1.0.4.0, you can automate the process of deleting old graph data and loading new data into Neptune.
Today deleting graphs in Amazon Neptune can be slow because the process is transactional in nature. If you’re using Resource Description Framework (RDF) to delete data, you must use a cascading delete in SPARQL. If you’re using property graphs, you might start with the command g.V().drop() on the Gremlin console. However, depending on the size of your graph database, the drop command might time out or give an out-of-memory error. Therefore, you may get stuck in a cycle of increasing query timeouts and retrying. You may end up rewriting your queries to drop your graph database in smaller chunks (either by sequencing dropping edges followed by vertices, or writing a multi-threaded Gremlin query).
With the new database reset capability in Neptune, you can remove all data from the graph database using REST APIs or built-in commands which are available via Neptune Workbench. Database reset works for both property graphs and RDF graphs. In this post, we discuss the database reset in detail and what happens when it is invoked.
Solution overview
Database reset in Neptune is a two-step process. The first step issues a time-bound token (valid for 60 minutes). The second step uses the issued token as input to perform the actual reset. This two-step approach offers a protection against accidental deletions.
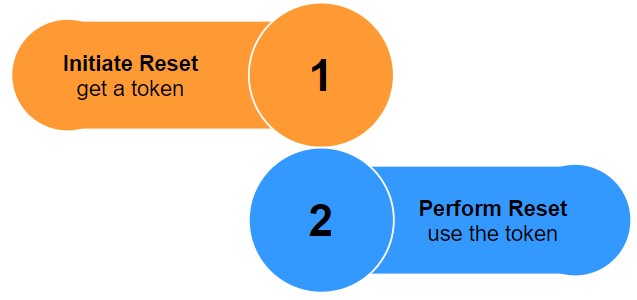
REST APIs
Amazon Neptune exposes a new /system endpoint for performing database reset in two steps: initiateDatabaseReset and performDatabaseReset.
initiateDatabaseReset
You must perform this step on the /system endpoint using the curl command. See the following code:
The response in JSON format provides a reset token:
performDatabaseReset
The second step uses the token from the initiateDatabaseReset command as input. This step works on the /system endpoint using the curl command. See the following code:
The response in JSON format provides a reset token:
The token is valid for 60 minutes. If the token is expired, you get an error response:
Workbench magic commands
You can also initiate a database reset on the Neptune workbench using this two-step process.
db_reset –generate-token
The db_reset --generate-token command generates a time-sensitive token:
db_reset –token
The db_reset --token command needs to provide the token generated in the previous command as input to trigger the reset:
How Neptune performs a database reset
Amazon Neptune performs series of steps to successfully perform a database reset:
- The cluster marks the
resetstatus in database. - A JSON response with
200status is sent to the client. - The cluster stops accepting new incoming requests.
- The cluster tries to cancel any queries that are currently in the queue.
- The cluster re-starts.
- The cluster drops existing database and recreates a blank database.
- The cluster is ready to accept incoming read/write requests.
The operation can take 60–90 seconds before the server is ready to accept new read and write requests. The client application should use the best practice of gracefully handling connection disruptions and reconnecting as necessary prior to submitting any read or write requests.
Conclusion
The newly released database reset capability allows you to remove all data from the graph. This accelerates graph application development because developers can use REST APIs or built-in commands which are available via Neptune Workbench to delete all data quickly and easily. You no longer need to spend time tuning query timeouts or writing complex, multi-threaded queries to delete edges and vertices. Try it out on your Neptune Cluster today.
About the Authors

Niraj Jetly is a Software Development Manager, Neptune. Prior to AWS, Niraj has led several product and engineering teams as CTO, VP-Engineering, and Head of Product Management for over 15 years. Niraj is a recipient of over 15 innovation awards including being named as CIO of the year in 2014 and top 100 CIO in 2013 and 2016. A frequent speaker at several conferences, he has been quoted in NPR, WSJ, and The Boston Globe.
 Navtanay Sinha is a Senior Product Manager for Amazon Neptune at AWS.
Navtanay Sinha is a Senior Product Manager for Amazon Neptune at AWS.