AWS Database Blog
Tag: Amazon Neptune
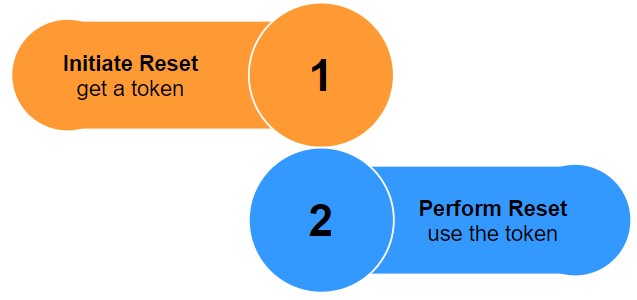
Resetting your graph data in Amazon Neptune in seconds
As an enterprise application developer building graph applications with Amazon Neptune, you may want to delete and reload your graph data on a regular basis to make sure you’re working with the latest changes in your data, such as new relationships between nodes, or to replace test data with production data. In the past, you […]

Building a knowledge graph with topic networks in Amazon Neptune
This is a guest blog post by By Edward Brown, Head of AI Projects, Eduardo Piairo, Architect, Marcia Oliveira, Lead Data Scientist, and Jack Hampson, CEO at Deeper Insights. We originally developed our Amazon Neptune-based knowledge graph to extract knowledge from a large textual dataset using high-level semantic queries. This resource would serve as the […]

How to get started with Neptune ML
Amazon Neptune ML is an easy, fast, and accurate approach for predictions on graphs. In this post, we show you how you can easily set up Neptune ML and infer properties of vertices within a graph. For our use case, we have a movie streaming application and we want to infer the the top genres […]
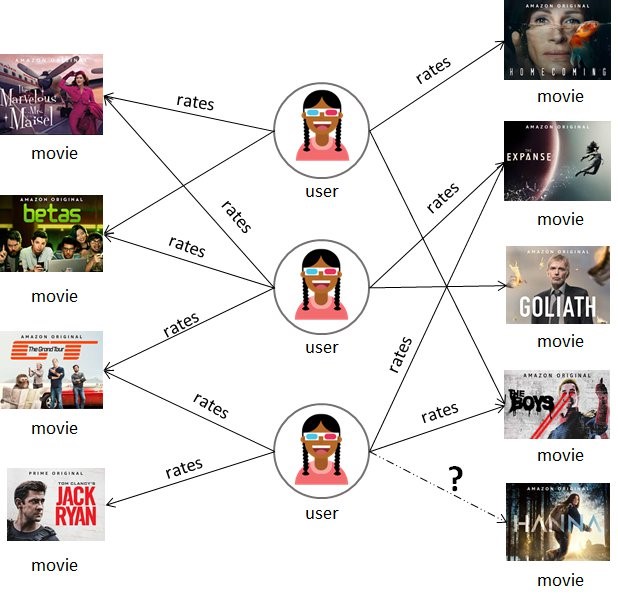
Announcing Amazon Neptune ML: Easy, fast, and accurate predictions on graphs
We’re thrilled to announce the availability of Amazon Neptune ML, an easy, fast, and accurate approach for predictions on graphs. Neptune ML is a new capability that uses graph neural networks (GNNs), a machine learning (ML) technique purpose-built for graphs. With GNNs, you can improve the accuracy of most predictions for graphs by over 50% […]

Building a biological knowledge graph at Pendulum using Amazon Neptune
At Pendulum, we combine state-of-the-art genome sequencing, cell culturing, and manufacturing processes to produce Pendulum Glucose Control, the only medical probiotic clinically shown to lower blood glucose spikes for the dietary management of type 2 diabetes through the gut microbiome. Research and development at Pendulum requires the synthesis of a diverse set of rich data and information streams, and this year we undertook a project to aggregate much of our data into a single database, the Pendulum knowledge graph, which integrates publicly available information on bacterial metabolism with the DNA sequencing data we generate for our strains.

Exploring Apache TinkerPop 3.4.8’s new features in Amazon Neptune
Amazon Neptune engine version 1.0.4.0 supports Apache TinkerPop 3.4.8, which introduces some new features and bug fixes. This post outlines these features, like the new elementMap() step and the improved behavior for working with map instances, and provides some examples to demonstrate their capabilities with Neptune. Upgrading your drivers to 3.4.8 should be straightforward and typically require no changes to your Gremlin code.

Populating your graph in Amazon Neptune from a relational database using AWS Database Migration Service (DMS) – Part 4: Putting it all together
In this four-part series, we cover how to translate a relational data model to a graph data model using a small dataset containing airports and the air routes that connect them. Part one discussed the source data model and the motivation for moving to a graph model. Part two explored mapping our relational data model to a labeled property graph model. Part three covered the Resource Description Framework (RDF) data model. In this final post, we show how to use AWS DMS to copy data from our relational database to Neptune for both graph data models. You may wish to refer to the first three posts to review the source and target data models.

Populating your graph in Amazon Neptune from a relational database using AWS Database Migration Service (DMS) – Part 3: Designing the RDF Model
In this four-part series, we cover how to translate a relational data model to a graph data model using a small dataset containing airports and the air routes that connect them. Part one discussed the source data model and the motivation for moving to a graph model. Part two covered designing the property graph model. In this post, we explore mapping our relational data model to a Resource Description Framework (RDF) model. You may wish to refer to parts one and two of the series to review the model. In part four, we show how to use AWS DMS to copy data from a relational database to Neptune for both graph data models.

Populating your graph in Amazon Neptune from a relational database using AWS Database Migration Service (DMS) – Part 2: Designing the property graph model
In this four-part series, we cover how to translate a relational data model to a graph data model using a small dataset containing airports and the air routes that connect them. Part one discussed the source data model and the motivation for moving to a graph model. In this post, we explore mapping our relational data model to a labeled property graph model. You may wish to refer to part one of the series to review the source relational data model. Part three covers the Resource Description Framework (RDF) data model. In part four, we show how to use AWS DMS to copy data from a relational database to Neptune for both graph data models.

Populating your graph in Amazon Neptune from a relational database using AWS Database Migration Service (DMS) – Part 1: Setting the stage
In this four-part series, we cover how to translate a relational data model to a graph data model using a small dataset containing airports and the air routes that connect them. Part one discusses the source data model and the motivation for moving to a graph model. We discuss this for the labeled property graph in part two and for the Resource Description Framework (RDF) data model in part three. In part four, we show how to use AWS DMS to copy data from a relational database to Neptune for both graph data models.