AWS Database Blog
Tag: Amazon Neptune

Configure Amazon VPC for SPARQL 1.1 Federated Query with Amazon Neptune
In this post, I describe firstly how you can create a new Amazon Neptune cluster on the console. then by using a NAT Gateway configure your Amazon VPC network to enable SPARQL 1.1 Federated Query.

Write a cascading delete in SPARQL
Customers often manage tree structures in their graph applications. Typical examples include categories of topics in a knowledge graph, relationships between people in an identity graph, or transaction networks in a financial application. Often, the structures are actually forests (collections of trees) with shared subtrees. In these applications, you frequently need to traverse a tree, […]

Graph your AWS resources with Amazon Neptune
In this post, we walk through an example we released for Neptune with integration with Altimeter. Altimeter is an open-source project (MIT License) from Tableau Software, LLC that scans AWS resources and links these resources into a graph. You can store, query, and visualize the data in Neptune. You can query the graph to examine the AWS resources and their relationships in an account. For example, you can query for resources or pathways that expose a cluster with a public IP address to check for security and compliance.
Complement Commercial Intelligence by Building a Knowledge Graph out of a Data Warehouse with Amazon Neptune
This is a guest post from Shahria Hossain, Software Engineer, and Mikael Graindorge, Sales Operations Leader at Thermo Fisher Scientific. The continuous expansion of data volume is a growing challenge for businesses to produce strategic solutions for their customers. Thanks to innovative approaches, these challenges have become simpler to solve with the rise of new […]

Cox Automotive scales digital personalization using an identity graph powered by Amazon Neptune
Neptune is a fully managed graph database service that makes it easy to build and run applications using highly connected datasets. Neptune is a purpose-built, high-performance graph database engine optimized for storing billions of relationships and querying the graph with milliseconds latency. Neptune supports both the Property Graph and the Resource Description Framework (RDF) standard.

Load balance graph queries using the Amazon Neptune Gremlin Client
[Updated August 2021] The Gremlin Client for Amazon Neptune is now available from Maven Central. Some APIs have changed since this article was published. Please review the demo code in the GitHub repository for the latest examples of how to use the APIs. Amazon Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and […]

Using collaborative filtering on Yelp data to build a recommendation system in Amazon Neptune
“I’m hungry. Where should I go to eat?” It’s one of the most common questions we ask ourselves every day, and when you’re going out to spend money somewhere, you don’t want to simply pick a random place and try it—you want some sort of assurance that the restaurant you choose matches what you’re looking […]
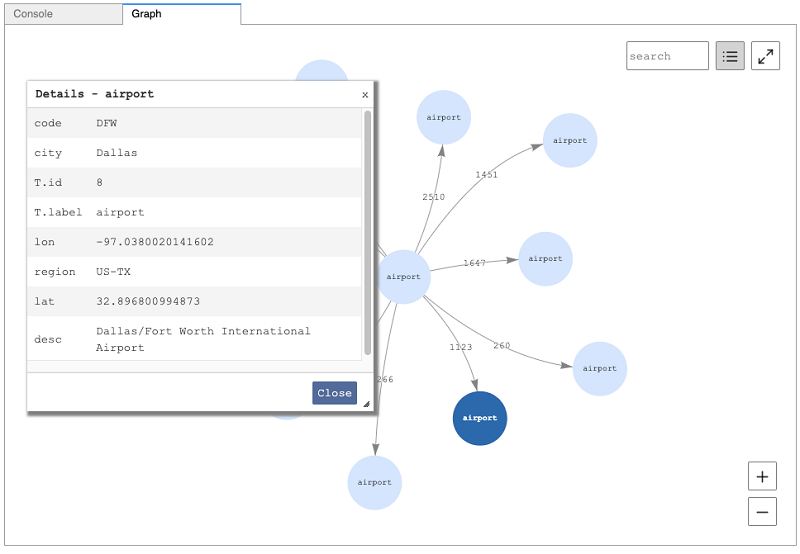
Visualize query results using the Amazon Neptune workbench
In this post, we look at the new visualization features recently added to the Amazon Neptune workbench and released on August 12, 2020. These additional capabilities allow you to produce an interactive graph diagram representing the results of your Gremlin and SPARQL queries. We look at some Gremlin-specific features and then do the same for SPARQL. Finally, we look at some of the more advanced ways you can modify the visualizations. As a sidenote, this entire post was produced using the workbench.

Benefitting from SPARQL 1.1 Federated Queries with Amazon Neptune
In this post, I show you how to use SPARQL 1.1 Federated Query in Neptune to get data about soccer teams in the UK from an external dataset, DBpedia (a well-known public dataset of Wikipedia data). Using the DBpedia publicly accessible SPARQL endpoint, I link the data from DBpedia to data that I add to the Neptune cluster.
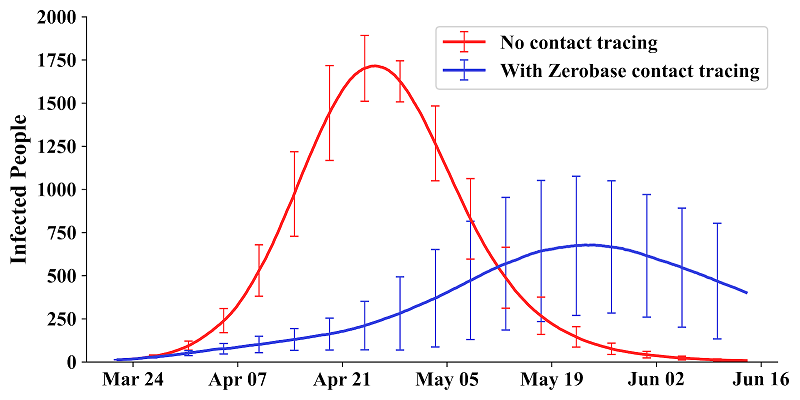
Zerobase creates private, secure, and automated contact tracing using Amazon Neptune
This is a guest post from the Zerobase Foundation. In their own words, “The Zerobase Foundation is a nonprofit organization whose mission is to build free, open-source public health technology for the good of communities around the world. Zerobase’s privacy-first contact tracing platform empowers individuals, communities, and local officials to stop the spread of COVID-19.” […]