AWS Database Blog
The Database Migration Playbook has landed!
We are happy to announce the availability of the first edition in the Amazon Database Migration Playbooks series. We plan for each playbook to be a step-by-step guide that aims to help make heterogeneous database migrations faster and easier and achieve “database freedom.”
What the Database Migration Playbooks do
The Database Migration Playbooks (a joint project by Amazon Web Services and NAYA Tech) are a series of guides focused on best practices for creating successful heterogeneous database migration blueprints. The playbooks are meant to complement existing automated and semi-automated Amazon database migration solutions and tools, including AWS Schema Conversion Tool (AWS SCT) and AWS Database Migration Service (AWS DMS).
Most, if not all, heterogeneous database migrations rely on a mix of automated tools and DBA know-how. The purpose of the Database Migration Playbooks is to capture as much of the DBA know-how part of the database migration equation as possible in easily readable reference documents.
We aim to keep the structure of the playbooks as practical as possible. We do this by listing the features and capabilities that exist in the source database engine and what we believe to be the best comparable solutions available in your selected target database platform.
For the first edition of the playbook, “Oracle to Amazon Aurora Migration,” we focus on best practices for migrating Oracle 11g and 12c database features and schema objects to Amazon Aurora with PostgreSQL compatibility. Doing this, we use both the capabilities that are built into the PostgreSQL database engine itself and also the various available AWS services and solutions.
We cover tons of technical content in the first playbook, including detailed how-to examples and tutorials for migrating Oracle features. We address features such as table partitions, materialized views, triggers, stored procedures and functions, database links, data types, session and instance configuration parameters, usage of DBMS_ packages and v$ views, indexes, SQL language syntax differences, sequences, RMAN, Oracle Flashback Database, JSON storage, Oracle 12c PDBs, and many, many more.
We’re currently working on additional playbooks covering other source and target database platforms. We hope to make these available throughout 2018.
Database Migration Playbook structure
For each Oracle database feature we cover, we provide a source-to-target migration blueprint. This blueprint has both an overview of how the source Oracle feature works and the best equivalent that is available in Amazon Aurora with PostgreSQL compatibility. In cases where Oracle features don’t have one-to-one equivalents in Aurora PostgreSQL, we attempt to present the best workaround that exists.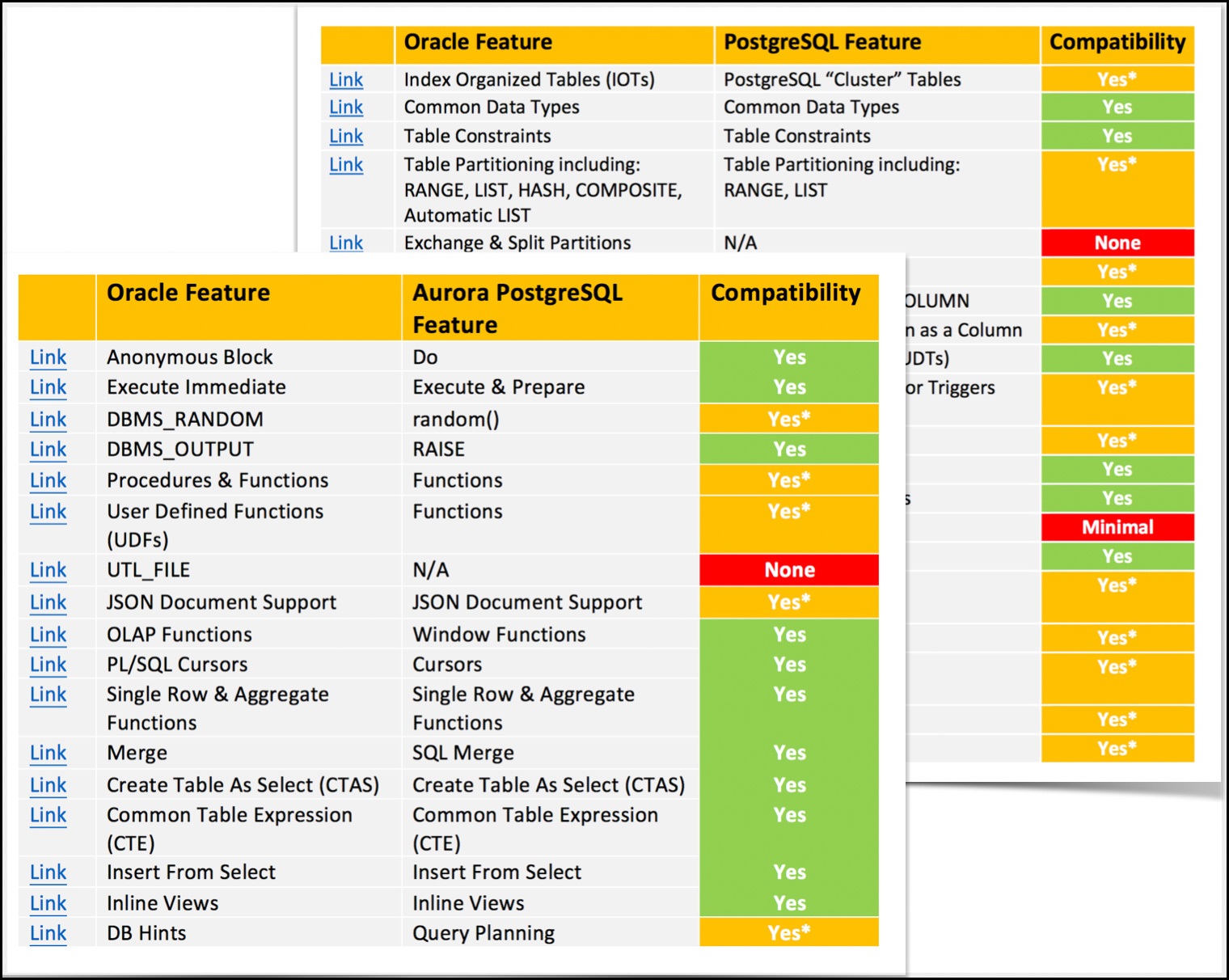
For example, take the topic of Oracle database links, which are schema objects used to interact with remote database objects, such as tables. In this case, we list examples on how database links are created and used in Oracle Database:
And how we can achieve similar capabilities by using either the dblink or postgresql_fdw (Foreign Data Wrapper – FDW) extensions:
In the playbook itself, we provide granular and detailed examples for both dblink and PostgreSQL FDW. However, because using FDW involves additional steps, we omit it from this post and truncate most of the dblink example presented above. The playbook contains both examples in their full.
Another quick example is Oracle Flashback Database, a continuous backup mechanism that can help protect against human errors by providing the capabilities to revert the entire database back to a previous point in time. In our playbook, we present a demo on how to create a Flashback Database restore point. and how to restore the entire Oracle database to that restore point using SQL commands:
Using Aurora PostgreSQL, we can use database snapshots to achieve comparable functionality:
As with the previous database link example, the playbook itself contains the full and detailed step-by-step guide of how to create snapshots. It also shows how to restore your Amazon Aurora cluster from a snapshot using both the AWS Management Console and the AWS CLI.
Who should read the playbooks
In addition to helping you perform database migrations in combination with AWS SCT and AWS DMS, the Database Migration Playbooks are intended as quick reference guides for Oracle Database administrators. We hope that busy Oracle DBAs interested in learning about Aurora PostgreSQL will use the playbook to quickly look up specific Oracle features and their Aurora PostgreSQL best equivalents or alternatives. We hope to save DBAs the trouble of going through all of the extensive documentation that is available online.
Each Database Migration Playbook is meant to be a living document that we continue to revise, expand, and fortify over time as new features are made available in Amazon Aurora and the PostgreSQL database itself. So it should be worthwhile to come back to this blog and stay updated on the latest news and updates regarding the playbook and database migrations in general.
You can find the Oracle to PostgreSQL Aurora Database Migration Playbook in the Resources section of the DMS product page.
About the Authors
 David Yahalom is the CTO of NAYA Tech. He is a certified Oracle, Apache Hadoop, and NoSQL database expert and a cloud solutions architect.
David Yahalom is the CTO of NAYA Tech. He is a certified Oracle, Apache Hadoop, and NoSQL database expert and a cloud solutions architect.
 Doug Flora is a senior product marketing manager for Amazon Relational Database Service (RDS) at Amazon Web Services.
Doug Flora is a senior product marketing manager for Amazon Relational Database Service (RDS) at Amazon Web Services.