.NET on AWS Blog
VTEX accelerates application scale-up by 88% with Amazon EKS
Alberto Frocht and João Borges contributed to this article.
Introduction
VTEX, a global e-commerce company serving over 3,400 customers across 38 countries, has undergone a transformative journey since its inception in 2000. Evolving from a B2B textile software to a cloud-native, microservices-based e-commerce platform, VTEX has prioritized efficiency, resilience, and innovation. As part of the journey to a modernized SaaS application, VTEX realized it’s essential to manage costs while delivering seamless shopping experiences.
In this post, we will explore how VTEX successfully modernized their legacy .NET Framework applications by migrating to Amazon Elastic Kubernetes Service (Amazon EKS). Using Amazon EKS, VTEX reduced scale-up time by 88%, enabling faster and cost-efficient infrastructure deployment.
Understanding the challenge
Many organizations still rely on legacy Windows applications that continue to deliver business value but face technical limitations that hinder further growth and scalability. As these applications reach the end of their lifecycle, engineering teams recognize the high risk, time, and cost involved in rewriting them from scratch. As a result, organizations often choose to build new products or gradually decompose the monolith into modern, decoupled services.
Still, the engineering team remains responsible for keeping the legacy system operational and performing well. These applications were typically built with a monolithic architecture tightly coupled to the underlying infrastructure, making them difficult to adapt to modern technologies. This challenge is even more significant in Windows-based environments, where scaling is slow and costly, provisioning a new instance can take around seven minutes. To mitigate this delay, teams often reduce CPU thresholds aggressively to trigger autoscaling earlier and avoid request queuing that could degrade the system. However, this approach leads to higher operational costs and inefficient use of computing resources.
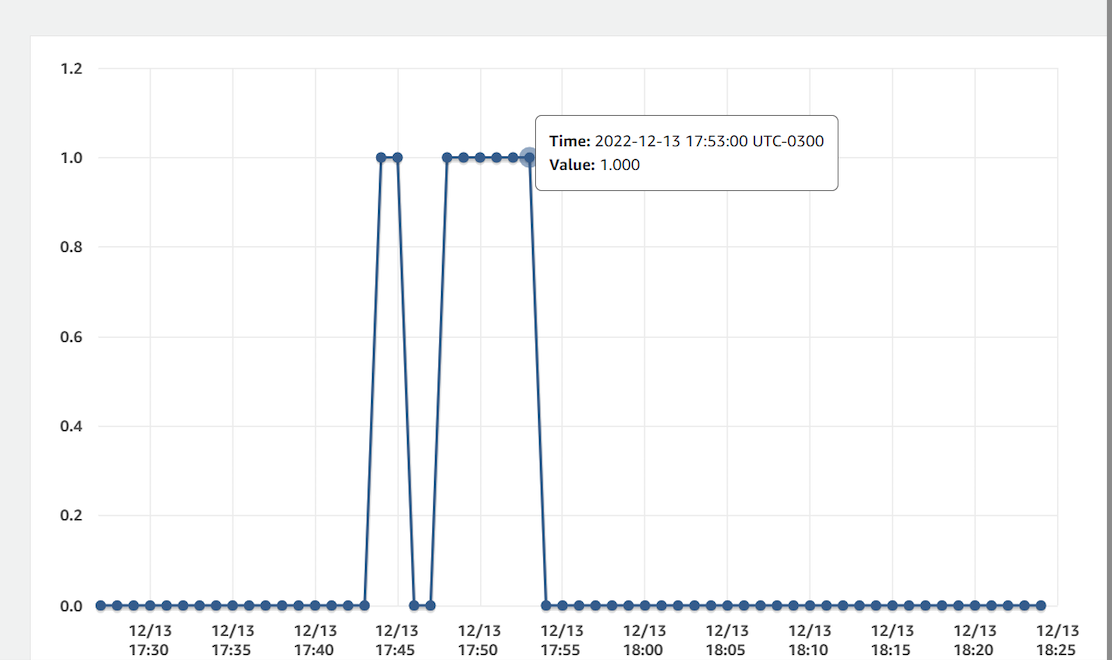
Figure 1 – Windows Unhealthy Host Count Over Time
The (Figure 1) illustrates the number of unhealthy Windows hosts in the AWS Elastic Beanstalk environment during a build operation. Each spike shows a period in which one or more instances were temporarily set as unhealthy while provisioning or initializing new Windows nodes.
In this example, the unhealthy host count rises to 1 at approximately 17:45 UTC-3 and remains elevated for about 8 minutes, returning to zero around 17:53 UTC-3. This behavior aligns with the build log timestamps, where the application build process starts at 17:48:41 and completes at 17:52:40.
The pattern demonstrates the slow initialization time of Windows-based environments, where provisioning a new instance typically takes several minutes. Such delays directly impact deployment and scaling performance, especially under load or frequent release scenarios.
The following logs demonstrate Windows waiting time for building the application in the AWS Elastic Beanstalk environment.
2022-12-13 17:48:41,900 [INFO] -----------------------Starting build-----------------------
2022-12-13 17:52:40,514 [INFO] -----------------------Build complete-----------------------
Beyond the technical challenges, we identified a gap between VTEX’s long-term platform strategy and the way legacy systems were managed. While modern applications were fully integrated into a standardized development workflow, leveraging Backstage, ArgoCD, built-in observability, and automated deployment best practices, legacy stacks remained isolated, operating outside the company’s modern and unified platform model.
Migrating these applications to Amazon EKS became the bridge between legacy and modern architectures. By containerizing .NET Framework workloads and running them on Amazon EKS with Windows support, VTEX unified its platform. This transformation enabled the SRE team to centralize infrastructure management, including scaling, provisioning, and observability, allowing developers to focus entirely on building and evolving their applications without infrastructure overhead.
Today, legacy applications benefit from the same infrastructure, continuous delivery processes, observability, and operational standards as any modern microservice, enabling faster scaling, greater efficiency, and consistent alignment across the platform.
Prerequisites
- To fully understand and replicate the implementation described in this post, you should have:
- Basic knowledge of Amazon EKS, Kubernetes, and AWS Elastic Beanstalk
- Familiarity with containerizing Windows applications using Docker and the .NET Framework
- Experience working with Kubernetes YAML manifests on AWS
- A basic understanding of Site Reliability Engineering (SRE) practices.
Solution Overview
Before migrating to Amazon EKS, VTEX’s Windows-based applications ran in a legacy environment that relied on Elastic Beanstalk for provisioning and lifecycle management.
This setup was functional and stable but limited in scalability, deployment flexibility, and observability compared to containerized solutions.
The following diagram (Figure 2) illustrates this legacy architecture, which served as the foundation before the modernization effort.
Legacy application Architecture
The legacy infrastructure uses Elastic Beanstalk and Elastic Load Balancer (ELB) to connect and communicate with VTEX’s service mesh layers, as illustrated in the following image (Figure 2).
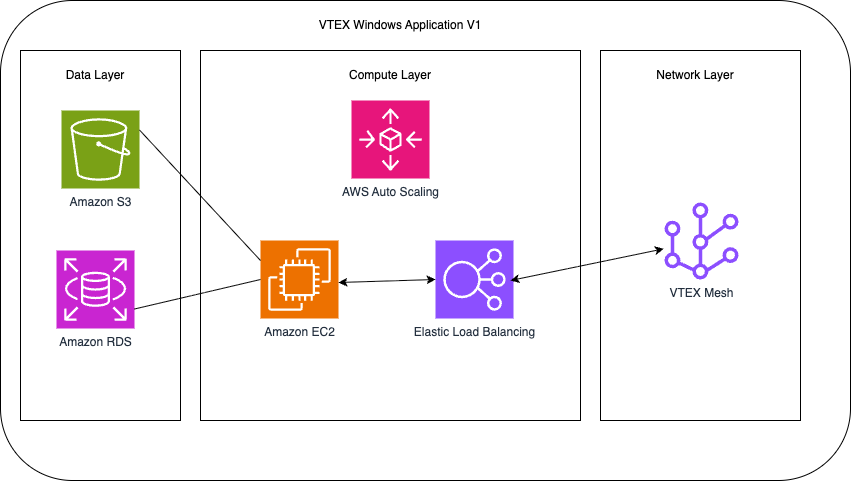
Figure 2 – Legacy Architecture application
Modernized Application Architecture
The following diagram (Figure 3) presents a simplified view of modernized architecture.
It illustrates how VTEX Windows-based applications now run on Amazon EKS, integrating with existing AWS services and VTEX Mesh.
This simplified diagram omits many Kubernetes resources for clarity, but the key point is that most Kubernetes primitives commonly used with Linux also work with Windows.
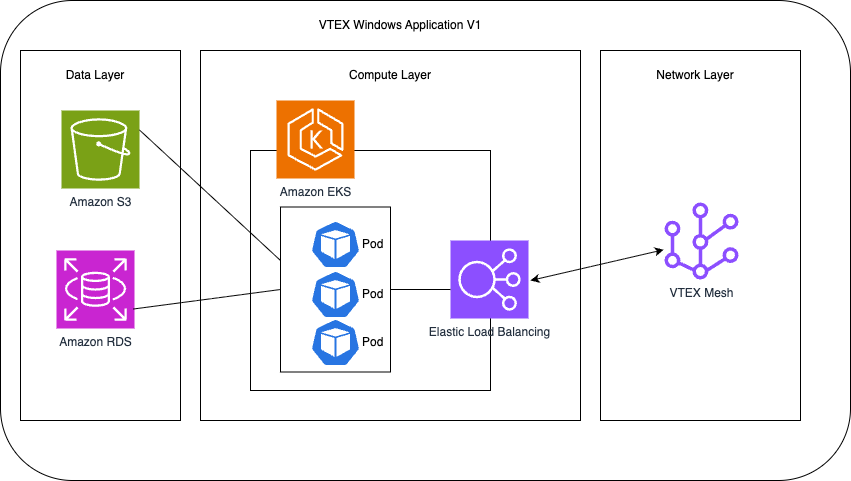
Figure 3 – New Application Architecture
The architecture is divided into three layers:
- Data Layer – Composed of AWS managed services such as Amazon Relational Database Service (Amazon RDS) and Amazon S3, which provide persistence and storage capabilities.
- Compute Layer – Based on Amazon EKS, where Windows pods run within the cluster and connect to backend services through Elastic Load Balancing.
- Network Layer – Handled by VTEX Mesh, responsible for service discovery and internal communication across VTEX systems.
Implementation details
With the migration to Amazon EKS, we aimed to keep the structure as close as possible to the previous architecture, especially regarding integration with the VTEX ecosystem.
For this reason, we decided not to introduce a Layer 7 (L7) Ingress Controller at this stage, maintaining the simplicity and predictability of the already validated model.
This approach allowed the team to modernize the compute layer while minimizing operational risk and preserving compatibility with the existing VTEX platform.
Container runtime configuration
VTEX packaged the applications as containers based on the official Microsoft container image:
mcr.microsoft.com/dotnet/framework/aspnet:4.8-windowsservercore-ltsc2019
This is a container image, which includes the ASP.NET 4.8 runtime over Windows Server Core LTSC 2019. Windows Server Core is headless where the Desktop Experience isn’t installed. This version of Windows Server is small, more secure, and ideal for server-side workloads. It provides the necessary system APIs and services to support legacy .NET applications in a containerized environment including web server technologies such as Internet Information Services (IIS).
This base image enables VTEX to encapsulate legacy apps without rewrite for .NET Core while maintaining compatibility with system-level dependencies such as GDI (graphics device interface), COM (Component object model), or WMI (Windows Management Instrumentation).
Node Infrastructure Setup
VTEX has created a Windows node group in the Amazon EKS cluster to run these containers. Each node in the Windows node group is powered by Amazon Elastic Compute Cloud (Amazon EC2) instance running Windows Server 2019 with a custom Amazon Machine Image (AMI).
We built the AMI on top of the Amazon EKS-optimized Windows AMI and extended to include the container base image preloaded. As a result, the platform avoids downloading the large container image at deployment time, significantly reducing pod startup delays to 73 seconds.
Important distinction:
- The container image defines the application’s runtime environment (Windows Server Core + .NET Framework + IIS).
- The AMI defines the Operating System (OS) and configuration of the EC2 instances that run the containers (in this case, Windows Server 2019 preconfigured for Amazon EKS and preloaded with the container image).
VTEX used AWS EC2 Image Builder to create a custom Windows AMI with the application container image preloaded. The pipeline was configured with a Windows Server Core base image, ensuring compatibility with the target container runtime environment. As a result, when a new pod starts, Kubernetes does not need to pull the entire container image, downloading only the layers that are not already present on the instance. This significantly reduced deployment time.
Integration with ArgoCD
VTEX integrated their legacy Windows applications into a modern GitOps workflow by defining Kubernetes manifests in ArgoCD-managed Git repositories. Their continuous integration pipeline handles container image building and publishing to Amazon Elastic Container Registry (Amazon ECR), while their continuous deployment pipeline automates manifest generation. These manifests are created in a central monorepo, pulling configurations from definition files in individual developer repositories. This streamlined approach eliminated the need for separate deployment processes between legacy and modern applications.”
Through this integration, legacy workloads now follow the same deployment workflow as modern Linux applications, there is no longer a distinction between Windows-based legacy systems and cloud-native services within the platform. ArgoCD continuously monitors the monorepo and synchronizes the desired state with the Amazon EKS cluster, making Windows-based applications first-class citizens in the GitOps pipeline.
As a result, these applications became part of the same continuous delivery flow as modern services. Developers can now interact directly with legacy applications through ArgoCD, using the same interface and practices already adopted for cloud-native workloads. In practice, they can visualize the state of EKS resources, apply changes, perform rollbacks, and monitor synchronization in a practical, centralized, and secure way.
The following image shows the legacy application’s Amazon EKS resources, which are fully managed through ArgoCD.
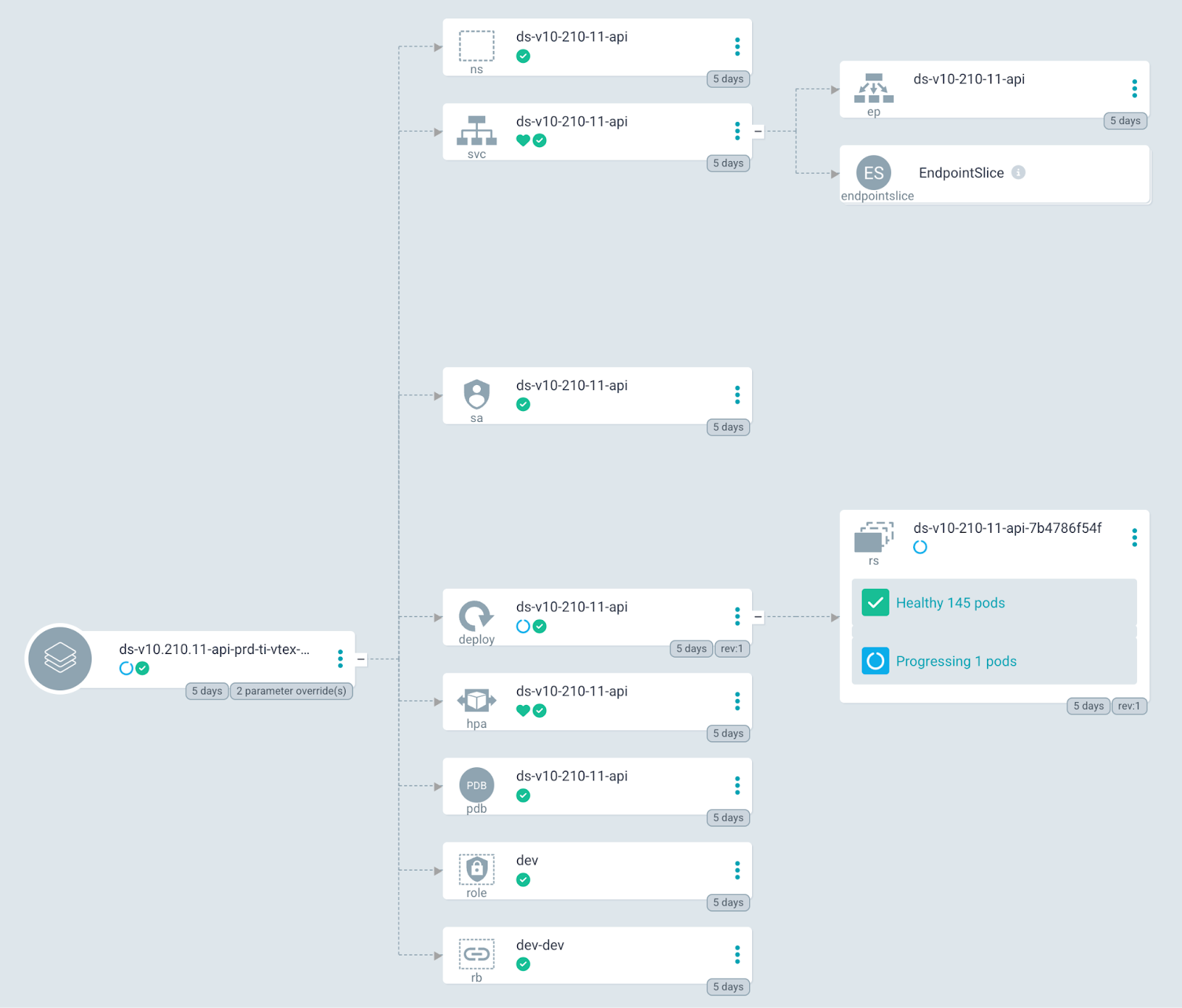
Figure 4 – ArgoCD Configuration
Integration with Backstage
For deployment control, legacy applications integrated with Backstage, which acts as a unified service discovery and management portal.
Backstage connects directly to the ArgoCD API, using each application’s unique identifier (App ID) to retrieve detailed deployment information. Through this integration, Backstage automatically discovers all versions currently running in Amazon EKS and enriches it’s interface with real-time operational data.
Once the list of versions is obtained, Backstage queries about the corresponding paths in the central monorepo, gathering metadata such as the target number of replicas, CPU thresholds for autoscaling, and the current replica count reported by the cluster.
This enables engineers to visualize and adjust scaling parameters directly from the Backstage interface, maintaining consistency between observed and desired states.
When engineers make configuration changes, such as adjusting CPU targets or replica counts, Backstage automatically opens a Pull Request in the source repository with the updated values. This preserves the GitOps model by ensuring all operational adjustments remain versioned, reviewed, and traceable through standard Git workflows.
The following image illustrates how containerized Windows applications appear alongside modern services, all adhering to the same standards for documentation, metrics, alerts, and helpful links.

Figure 5 – Environment Configuration
By running applications on Amazon EKS, these applications gain access to all innovations focused on Developer Experience, including reusable templates, resource auto-discovery, integrated dashboards, and support for the open-source tools used daily by the engineering team.
Performance Results
To validate the migration’s technical impact, we conducted a series of controlled performance tests comparing the legacy Elastic Beanstalk environment with the new Amazon EKS setup.
The goal was to measure whether the modernization effort preserved or improved key performance indicators such as application latency, scalability behavior, and infrastructure efficiency.
The tests were designed to reflect realistic production workloads, ensuring consistent traffic distribution and identical application code across both environments. Metrics were collected over several days to capture steady-state behavior as well as transient conditions such as autoscaling events.
The following sections detail the configuration of each environment and present the comparative results observed during the migration, highlighting differences in performance, resource utilization, and cost efficiency.
Comparison Between Environments
The configuration presented in the next section outlines the technical details of the environments used: Kubernetes on Amazon EKS and Elastic Beanstalk. Although both environments use Windows Server 2019, the Kubernetes environment offers greater flexibility and control over the resources used, such as granular pod deployment, use of custom images, and horizontal scalability based on CPU usage.
Additionally, the Amazon EKS environment supports higher application density per instance (up to 4 pods), optimizing compute resources compared to Elastic Beanstalk, which traditionally runs a single application per instance.
This comparison is a foundation for evaluating the feasibility of migrating workloads from Elastic Beanstalk to Amazon EKS, aiming for greater scalability, efficiency, and operational control.
Amazon EKS Environment Setup
| Configuration Category | Details |
| EKS version | v1.28 |
| Windows version | Windows Server 2019 Datacenter |
| Instance type | c6a.2xlarge,c6a.4xlarge,c6i.2xlarge,c6i.4xlarge,c7i.2xlarge, c7i.4xlarge |
| Application base container image | dotnet/framework/aspnet:4.8-windowsservercore-ltsc2019 |
| AMI | Custom, built upon the base EKS-optimized AMI but including the base ASP.NET Framework container image |
| Deployment resources | 4 vCPU, 8Gib Memory |
| Horizontal Pod Autoscaler (HPA) | 55% |
| Pod density | Until 4 application pods per instance |
Elastic Beanstalk Environment Setup
| Configuration Category | Details |
| Windows version | 64bit Windows Server 2019 v2.10.3 running IIS 10.0 |
| Instance type | c6a.large,c6i.large,c5a.large,c5.large,c4.large |
| Elastic Beanstalk autoscale target | Autoscale targets 55% |
During the migration process, we gradually shifted traffic from the Elastic Beanstalk environment to the Amazon EKS environment, reaching a 50/50 distribution across both platforms. We monitored the application’s behavior over several days, primarily focusing on latency and error rate metrics.
We compared the number of instances used in each environment to identify potential cost differences. However, these are distinct technologies. While Elastic Beanstalk runs the Windows application directly on the nodes, Kubernetes includes additional components beyond the application pods that consume computational resources.
While we cannot make a completely precise comparison, it provides a valuable reference for assessing the migration’s feasibility from a cost-benefit perspective. A comparison of the resources between the two environments is included in the following section.
Response time
The following chart compares latency between the Amazon EKS and Elastic Beanstalk environments, showing that both platforms deliver very similar response times. In this chart:
- Blue lines represent metrics from Amazon EKS.
- Yellow lines correspond to Elastic Beanstalk results.
Across the test period:
- The average latency (p50) remained around 19–20 ms for both platforms.
- The p90 latency was approximately 155–162 ms, with only a ~5% difference between environments.
- The p95 latency reached up to 324 ms on Elastic Beanstalk and 326 ms on Amazon EKS, indicating no significant performance gap.
Overall, the latency behavior across percentiles (p50, p90, p95) demonstrates that migrating to Amazon EKS did not introduce additional network overhead, maintaining the same responsiveness as the legacy platform.

Figure 6 – Latency
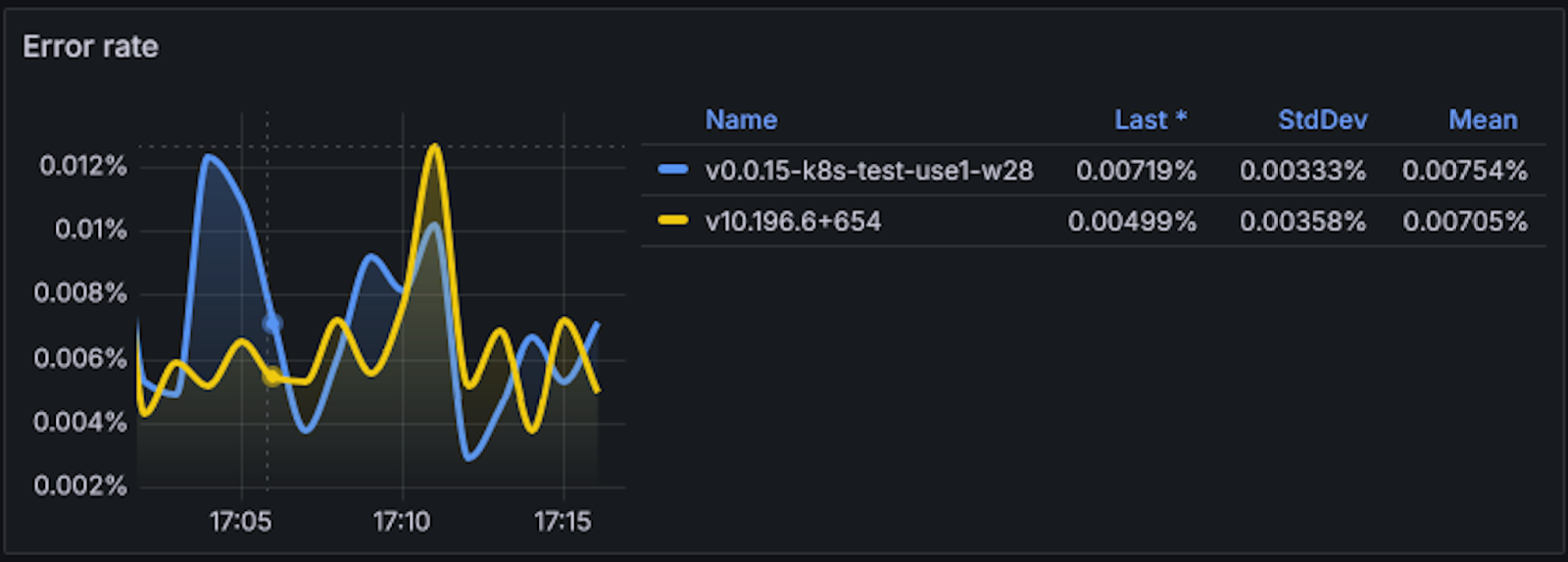
Error rate
The following chart shows the error rate over time for the versions running in the Amazon EKS and Elastic Beanstalk environments. Both display similar behavior, with occasional fluctuations but comparable averages and standard deviations.
Although both environments show variations, the overall error rates remain low and within an acceptable margin. These fluctuations are expected in real-world production scenarios and do not indicate critical or persistent issues. The close alignment in averages and standard deviations reinforces the stability and reliability of both platforms.
Throughput
The following chart compares the average throughput of the Amazon EKS and Elastic Beanstalk environments. It indicates similar behavior regarding requests per second (req/s), with nearly equivalent averages and minor variations.
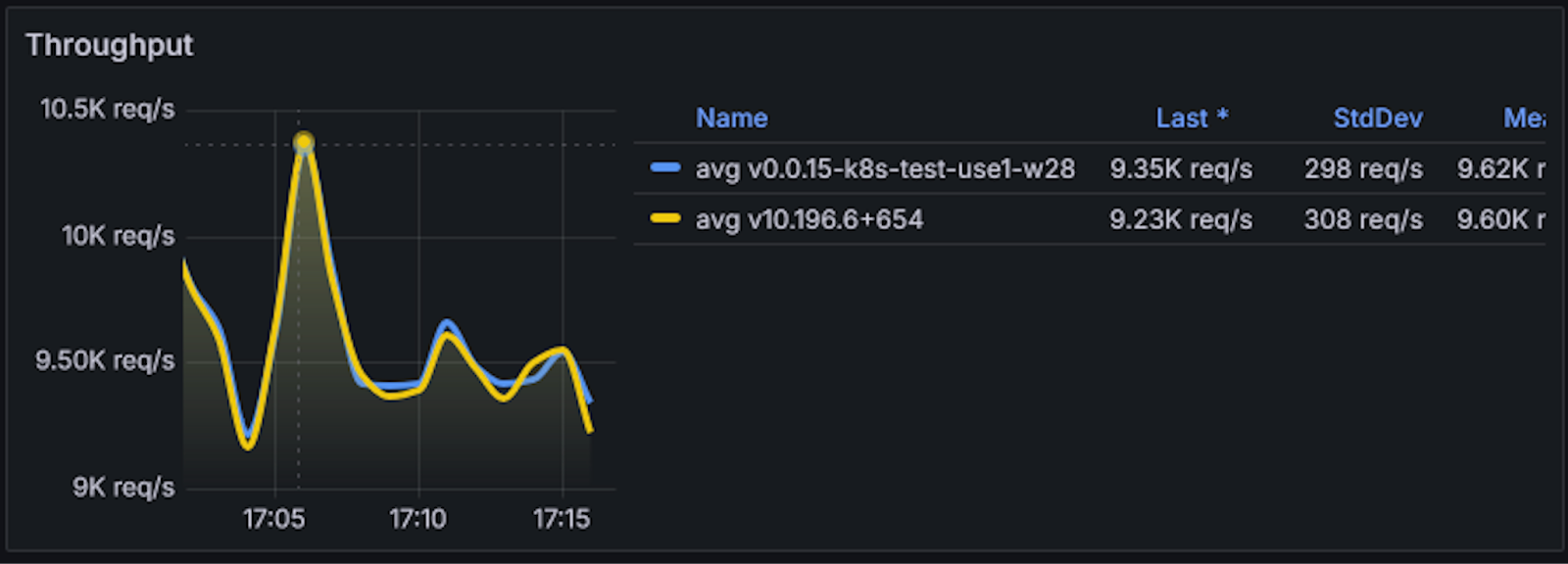
Figure 7 – Error Rate
Number of instances Elastic Beanstalk vs Amazon EKS
The following chart compares instance counts between AWS Elastic Beanstalk (34) and Amazon EKS (37) environments. While these numbers appear similar, Amazon EKS clusters divide node resources between application workloads and core cluster components. Kubernetes services and metric collection stacks actively consume node resources alongside your applications. This overhead requires careful consideration when comparing scalability between the two environments.
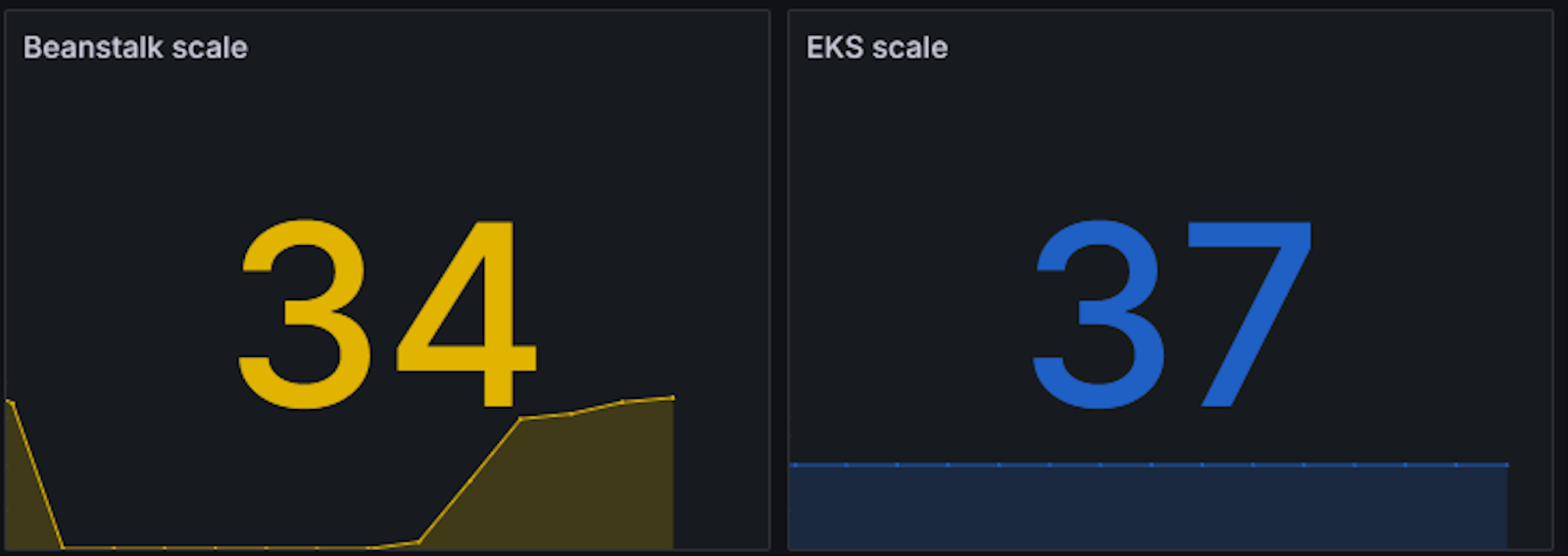
Figure 9 – Instances of Elastic Beanstalk and Amazon EKS
Pod provisioning time in Amazon EKS
The following image shows Amazon EKS pod scale-up time, which averages 73 seconds even when computational resources are already available in the node group. This time can extend to approximately 7 minutes when node scaling is required.
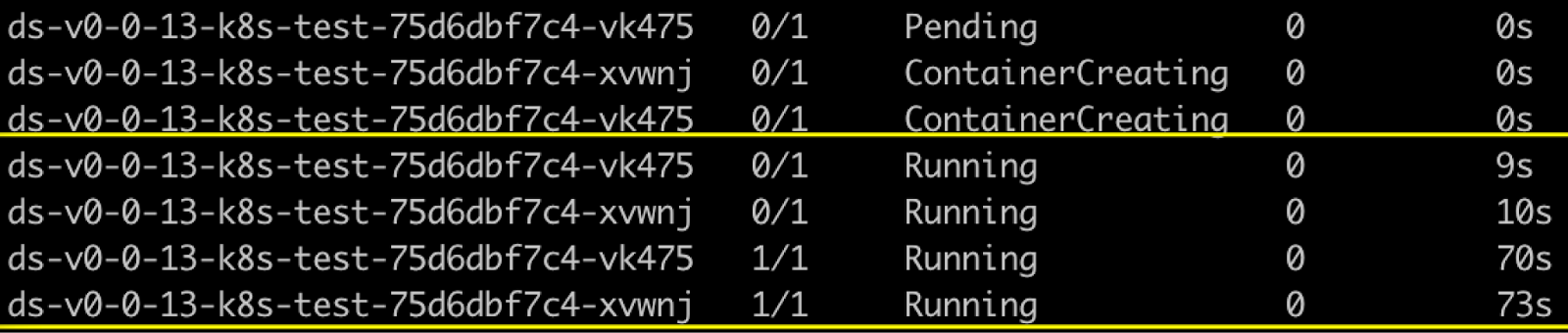
Figure 10 – Pod Provisioning
Requests vs Scaling
The following chart shows the relationship between infrastructure growth and the increase in request volume over 5 days without any minimum limits enforced. It highlights the system’s efficiency in scaling and meeting demand as needed.
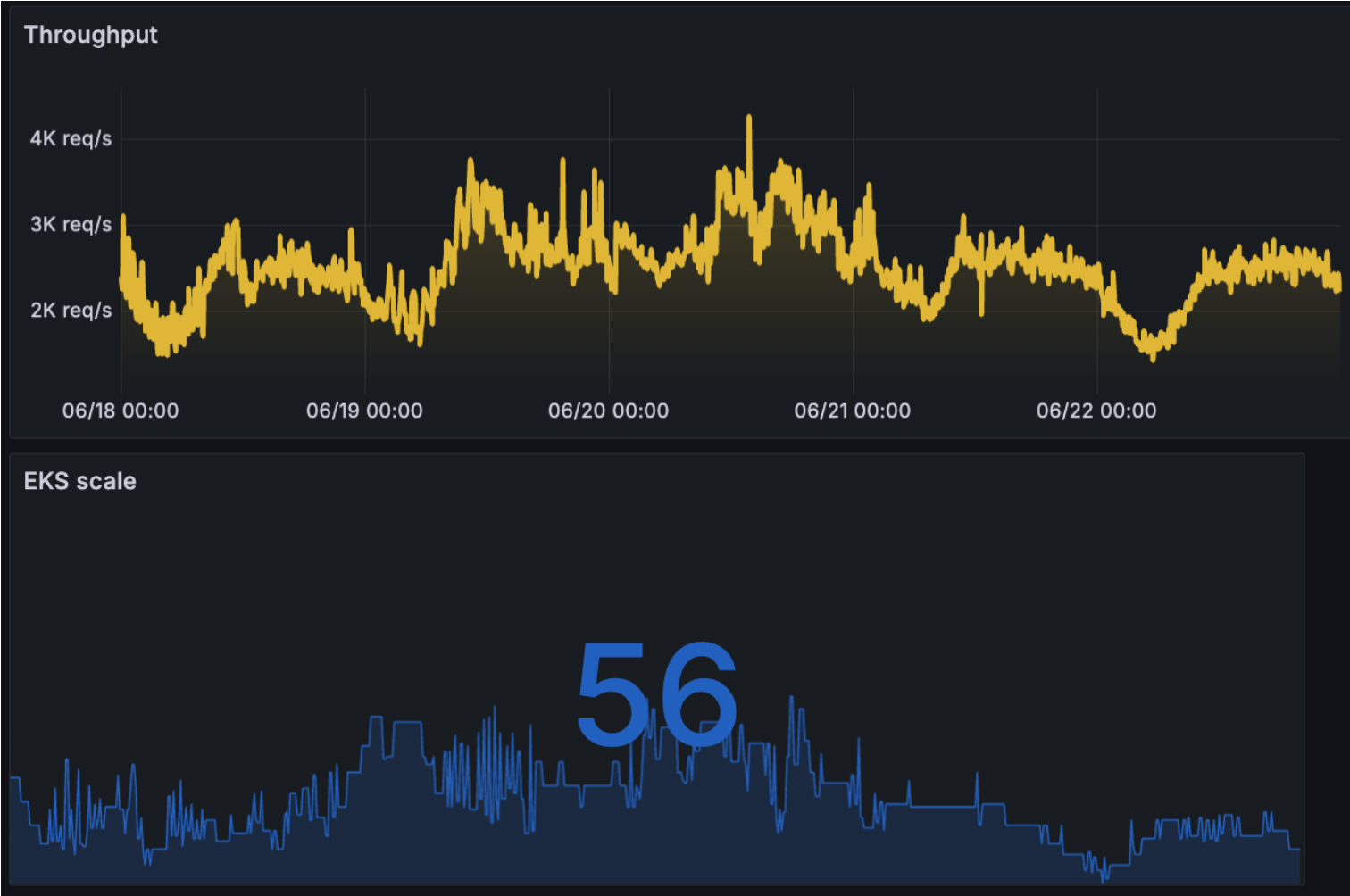
Figure 11 – Request vs Scaling
Platform Engineering Transformation
For Site Reliability Engineering (SRE) teams, migrating to Amazon EKS simplified infrastructure management. The transition to Amazon EKS significantly reduced the number of Elastic Beanstalk workloads. Legacy infrastructure that previously depended on manually managed physical instances is now represented as Amazon EKS resources, defined declaratively through YAML manifests.
This shift enhanced operational efficiency, as resources previously managed manually or through vendor-specific automation are now standardized and managed as code. Infrastructure management became more transparent, predictable, and version-controlled. Moreover, SREs improved visibility, accelerated debugging, and streamlined provisioning by directly tracking, reviewing, and applying operational changes through Kubernetes manifests.
Kubernetes architecture provided a more robust, flexible, and scalable operational model, streamlining administrative tasks and aligning legacy infrastructure seamlessly with modern operational standards.
Benefits Achieved
- The migration to Amazon EKS brought measurable operational and performance improvements.
- Pod startup time was reduced from approximately 7 minutes to just 73 seconds, significantly improving scalability and responsiveness.
- This optimization also led to cost reductions, as workloads no longer required aggressive autoscaling thresholds or over-provisioning during morning traffic ramp-ups.
- Infrastructure management became simpler and more unified, with both legacy and modern applications now operated through the same GitOps workflows and tools such as Backstage and ArgoCD.
- Overall, the modernization allowed VTEX to bring legacy systems in line with its platform’s modern operational standards while maintaining reliability and efficiency.
Conclusion
The comparisons between Elastic Beanstalk and Amazon EKS showed similar results for latency, error rate, and number of instances. However, VTEX perceived the most significant benefit in scale-up time, which added considerable value to operations.
AWS offers mechanisms to include a custom AMI with the preloaded .NET container image, eliminating the need for a full image pull during deployment. This implementation significantly accelerated the application scaling process.
With this optimized scaling, we observed a notable cost reduction. Applications no longer depend on low CPU thresholds to trigger autoscaling, as scale-up time dropped from around 7 minutes to 73 seconds. During morning traffic ramp-up, there was no longer a need to maintain predefined overscale limits previously used to compensate for the inability to scale gradually.
Additionally, we migrated more legacy Windows applications to the Amazon EKS environment, all exhibiting similar behavior, confirming the architecture’s consistency and the benefits achieved.
While our current implementation has significantly improved scale-up times, we’ve identified EC2 Fast Launch as a potential future optimization. This AWS feature can further reduce Windows node provisioning time by up to 65% through the use of pre-provisioned AMI snapshots.
It’s important to note that the current 73-second metric only reflects pod scale-up time, assuming available headroom in the cluster, and does not include the EC2 instance boot time. By leveraging EC2 Fast Launch, we could accelerate not only instance boot times but also the node provisioning phase, further reducing the total scale-up time in scenarios where additional capacity must be created on demand.
Backstage integrations ensured consistent and unified operation of Windows and Linux applications.
Related Resources
Enabling Support Windows node groups
Using AWS Image Builder to use the image cache strategy
Create a node with optimized Windows AMIs