AWS HPC Blog
Accelerating Aerospace Innovation: High Performance Computing (HPC) on Amazon Web Services (AWS)
In today’s rapidly evolving aerospace industry, the ability to innovate quickly and efficiently is not just an advantage – it’s a necessity. As technologies such as autonomous UAVs (Unmanned Aerial Vehicle), satellite constellations, reusable rockets and augmented/virtual reality progress, the ability to innovate quickly gives aerospace organizations an edge on their competition. High Performance Computing (HPC) is crucial to aerospace innovation and has become a cornerstone of aerospace advancement. Regardless of an organization’s size, age or iteration speed, Amazon Web services (AWS) is here to help drive their aerospace missions forward.
In this post, we’ll explore why, how and what aerospace customers are typically doing with HPC in AWS.
The Current State of HPC
Traditional on-premises HPC infrastructure often requires significant capital investment and can take months, or even years, to procure and deploy. Once deployed, clusters often run at or near 100% utilization. This high infrastructure utilization leads to long wait times for new HPC jobs that enter a queue. Research scientists and engineers are waiting (often weeks) for their job to progress through the queue and run, before they can analyze the results and iterate on their innovation. Additionally, the depreciation cycle of on-premises HPC infrastructure is typically 5-8 years. This means that while HPC infrastructure is getting better every year, on-premises clusters are stuck using less efficient infrastructure until it’s time for a hardware refresh, at which point the cycle of legacy infrastructure restarts.
In contrast, AWS provides organizations with instant access to virtually unlimited computational resources, enabling them to accelerate innovation while controlling costs. Deployment happens in a matter of minutes and customers pay only for what they use. Leveraging cloud capabilities, HPC clusters in AWS scale out to accommodate demand, process jobs successfully and scale back in when the queue empties. This elasticity alleviates significant waiting time for engineers and scientists, while only paying for resources while they are running. Additionally, AWS improves our HPC infrastructure at the speed of software. This means that rather than waiting years for a hardware refresh to modernize HPC infrastructure, AWS customers constantly have access to the latest, most price/performant HPC infrastructure from Amazon and our partners (NVIDIA, Intel, AMD, etc.).
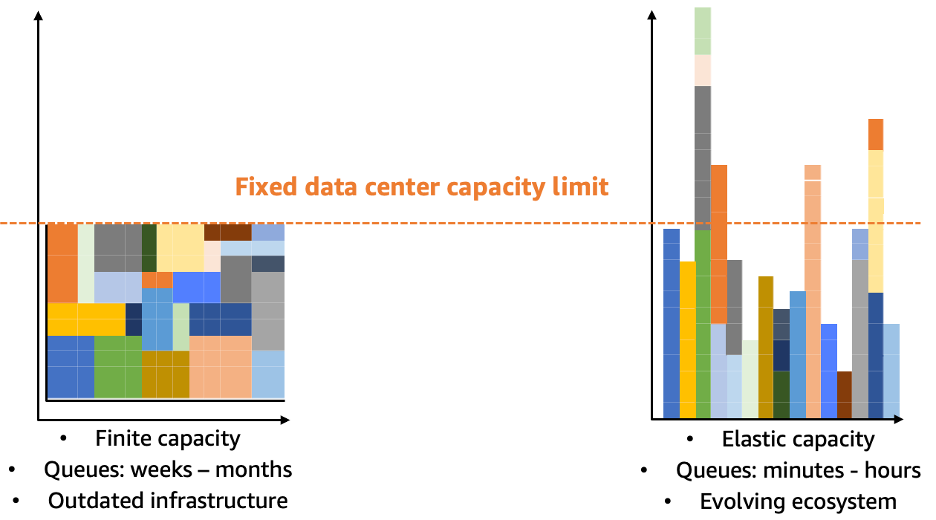
Figure 1: Contrasts running HPC workloads on-premises (left) versus in AWS (right). The left is bound to fixed data center capacity where queue times are long and infrastructure dates quickly. The right has elastic capacity that scales on demand, shortening queue times while running on more modern infrastructure.
Key HPC Workloads in Aerospace
Computational Fluid Dynamics (CFD)
Aerospace organizations are leveraging AWS’s powerful computational resources to perform complex CFD simulations that optimize aircraft design and analyze propulsion systems. Using AWS’s HPC services, organizations can run workloads like Siemens STAR-CCM+, Ansys Fluent or OpenFOAM simulations with thousands of cores, reducing simulation time from weeks to hours.
Structural Analysis
The demands of modern aerospace design require extensive structural analysis for things like product strength, vibration and acoustics. Whether it’s testing new composite materials or performing fatigue analysis on critical components, AWS’s HPC capabilities enable customers to run multiple simultaneous simulations using software like Dassault Systèmes Abaqus or Simcenter Nastran, accelerating the design iteration process.
Mission Planning and Space Operations
As the aerospace industry grows and innovates, organizations are using AWS HPC services to simulate complex orbital mechanics, optimize satellite constellation deployments and manage launch windows efficiently. These simulations require large quantities of next generation compute clusters, networking and storage infrastructure, which can be easily deployed and automatically scaled based on demand.

Figure 2: Example visualizations of HPC workloads for aerospace customers.
Each type of simulation workload has unique requirements for what type of infrastructure it runs on. AWS enables customers to optimize their infrastructure configurations, clusters and queues to efficiently run the modeling or simulation workload at hand.
The AWS HPC Toolkit
High performance computing requires efficient infrastructure at every layer of the stack. This includes compute, storage, networking and orchestration tools that allow aerospace organizations to innovate quickly. In this section, we’ll look at some tooling that aerospace customers use on AWS for HPC workloads.
Amazon Elastic Compute Cloud (Amazon EC2) offers the broadest and deepest compute platform, with over 850 instances. Amazon EC2 has a variety of highly performant instance types optimized for Accelerated Computing and HPC. The AWS Nitro System was introduced in 2017 and is built on a combination of purpose-built hardware, software, and firmware. It provides the underlying virtualization infrastructure for EC2 instances. Traditionally, hypervisors protect the physical hardware and BIOS, virtualize the CPU, storage, networking, and provide a rich set of management capabilities. With the Nitro System, we break apart those functions, offload them to dedicated hardware and software, and reduce costs by delivering practically all the resources of a server to your instances. This mitigates virtualization overhead.
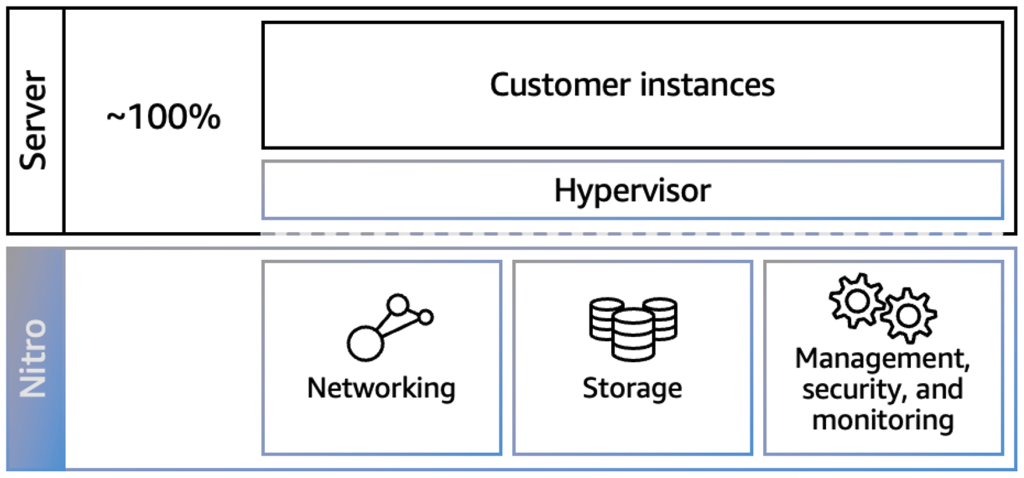
Figure 3: The Nitro System mitigates hypervisor overhead so customer instances can run at ~100% of bare metal capacity. The lighter shade shows technical operations Nitro covers, while the darker shade shows customer instances running on top of Nitro.
Our newest AWS managed service that simplifies HPC on AWS is AWS Parallel Computing Service (AWS PCS). AWS PCS makes it easier for customers to run and scale HPC workloads and build scientific and engineering models on AWS using Slurm as the workload manager. This managed service allows you to build complete HPC clusters that integrate compute, storage, networking, and visualization resources, and seamlessly scale from zero to thousands of instances. Alternatively, customers can use AWS ParallelCluster which is a feature rich, open-source cluster management tool that makes it easy to configure, deploy and manage HPC clusters on AWS. The tool is used via infrastructure as code templates, and has an optional web based graphical interface. AWS ParallelCluster is not a managed service and thus requires the customer to deploy it.
AWS Batch helps you to run batch computing workloads on the AWS Cloud. Batch computing is a common way for developers, scientists, and engineers to access large amounts of compute resources. AWS Batch removes the undifferentiated heavy lifting of configuring and managing the required infrastructure, like traditional batch computing software. This service can efficiently provision resources in response to jobs submitted to eliminate capacity constraints, reduce compute costs, and deliver results quickly.
So far, we’ve discussed compute resources and orchestration tooling that enables HPC workloads to run on AWS. There are other components that are important to HPC infrastructure, such as the network that connects compute nodes and high-performance storage. Let’s first look at networking.
Elastic Fabric Adapter (EFA) is a network interface for Amazon EC2 instances that enables customers to run applications requiring high levels of inter-node communications at scale on AWS. Its custom-built operating system (OS) bypass hardware interface enhances the performance of inter-instance communications, which is critical to scaling low latency HPC workloads.
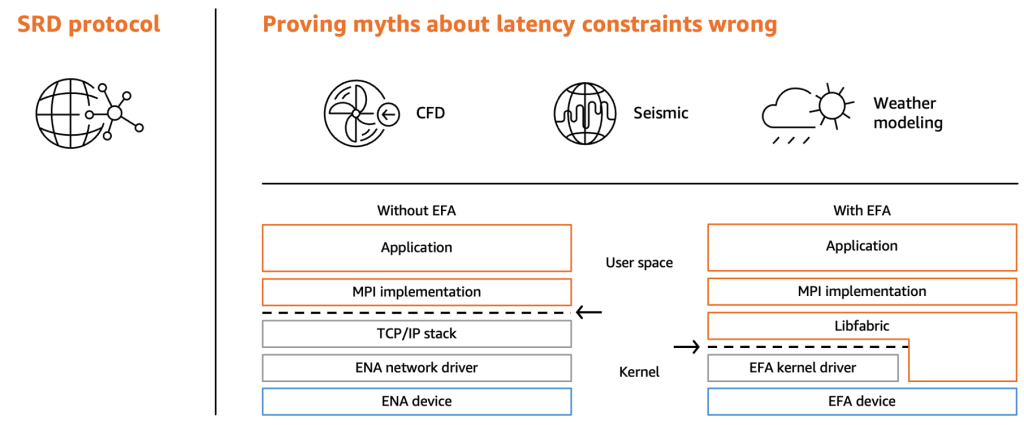
Figure 4: Shows the network infrastructure stack of EFA, visualization how the kernel is bypassed for accelerated performance.
AWS offers many storage services, such as Amazon Simple Storage Service (Amazon S3), Amazon Elastic Block Storage (Amazon EBS), among others. All these storage services can be used when building HPC clusters in AWS. However, many HPC workloads greatly benefit from specialized storage, such as Lustre – an open-source, parallel, distributed file system designed for HPC and large-scale data storage. Amazon addressed this need for HPC and AI/ML workloads by offering Amazon FSx for Lustre.
Amazon FSx for Lustre is fully managed shared storage service, built on the world’s most popular high-performance, parallel file system. It allows customers to accelerate compute workloads with shared storage that provides sub-millisecond latencies, up to hundreds of GBs/s of throughput, and millions of IOPS, all fully managed and deployable in minutes, without the pain of setup and administration.
A Day in the Life of an HPC Job on AWS
Now that we have a better understanding of HPC use cases and services that aerospace customers are leveraging on AWS, let’s bring it all together into a functional workflow. The diagram below exemplifies a customer running HPC workloads in their hybrid cloud environment, between their on-premises datacenter and AWS. End users from within the customer’s network boundary connect to Login Nodes via SSH. From the Login Nodes, HPC jobs are submitted and appended to the job queue. This triggers the allocation of compute nodes, where EC2 instances are scaled to meet the queue demand and run the jobs. These EC2 have connectivity to AWS services, run until the HPC job is complete, and then automatically scale back down.
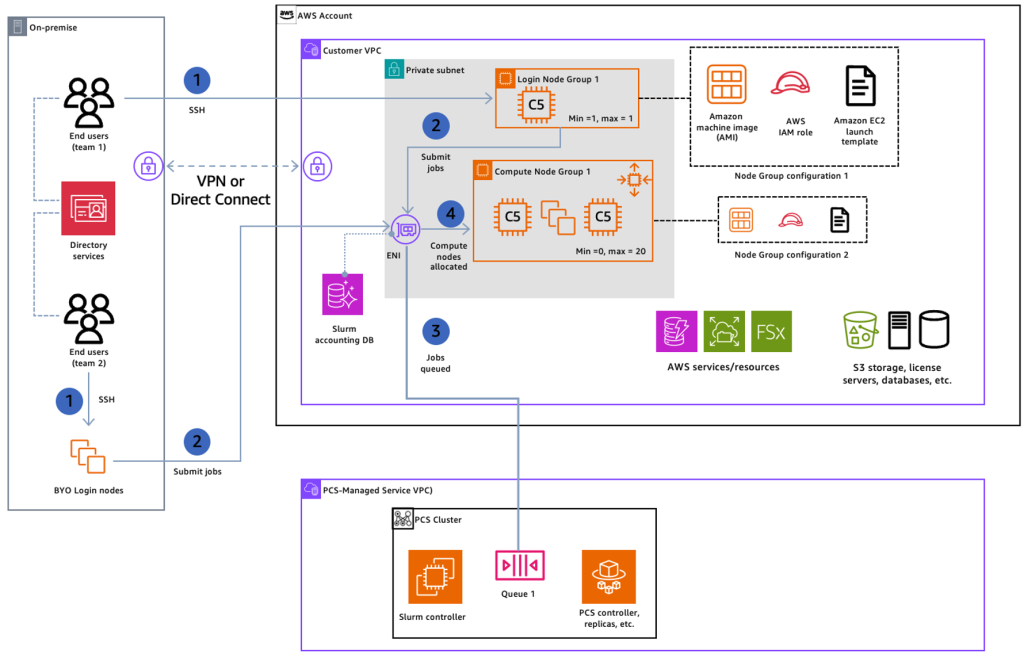
Figure 5: Example workflow of deploying HPC jobs leveraging AWS Parallel Computing Service.
We’ve covered some use cases, services and workflows that aerospace customers leverage on AWS. The logical next step would be to hear from customers themselves!
Aerospace Success Stories from the Field
Hypersonix Launch Systems reduced their CFD simulation pipeline time by 92%, from 3 months to 1 week, by migrating to AWS. They ran STAR-CCM+ workloads on-premises, in an over-utilized and outdated HPC cluster. Long queue times meant that their researchers and engineers were often sitting idle. AWS gave these technical teams their time back, so they could innovate and get their products to market faster. “I believe that we can stand out from larger companies because we have the cloud capability and resources that we need on AWS.”, said Dr. Stephen Hall, Head of Advanced CFD Thermal Structural Simulation at Hypersonix Launch systems.
Boom Supersonic uses AWS to accelerate the design and construction of their supersonic aircrafts. They can run thousands of advanced simulations concurrently on AWS, resulting in an estimated 6x increase in productivity versus their on-prem environment. Boom used more than 53 million compute hours on AWS to complete their Overture airliner. “AWS, the world’s leading cloud provider, will help us continuously refine our designs.”, said Blake Scholl, Founder and CEO of Boom Supersonic.
For more information on customer success stories, please visit: https://aws.amazon.com/solutions/case-studies/
Conclusion
Cloud-based HPC is revolutionizing how aerospace organizations innovate. AWS provides the scalability, performance, and security required for the most demanding aerospace HPC workloads. As the industry continues to evolve, our commitment to supporting aerospace innovation remains stronger than ever.
Ready to accelerate your aerospace innovation with HPC on AWS? Contact your AWS account team to learn more about how we can support your organization’s HPC journey.