AWS HPC Blog
Accelerating HPC Deployment with AWS Parallel Computing Service and Kiro CLI
Research teams moving from on-premises HPC environments often struggle with the complexity of cloud deployment. Traditional approaches require deep expertise in AWS networking, storage architectures, and Slurm configuration management. A typical manual deployment involves weeks of infrastructure provisioning, network topology design, scheduler configuration, and performance tuning. Research teams with limited platform engineering resources find themselves caught between the urgent need for computational capacity and the technical barriers to deployment.
In this post, we’ll show you how to use the Kiro CLI to automatically deploy and configure AWS PCS clusters with industry best practices built in. We’ll walk through creating Custom Agents that handle infrastructure provisioning, monitoring setup, and cost optimization while maintaining the flexibility research teams need for their specific workloads.
HPC in the Cloud
Cloud-based HPC has become standard practice due to its flexible compute access, broad resource availability, and valuable infrastructure abstraction. In this post, we’ll utilize AWS Parallel Computing Service (PCS) and Kiro CLI to demonstrate this approach.
AWS PCS: AWS PCS simplifies HPC deployment by providing a managed Slurm scheduler with automated configuration, scaling, and maintenance. The service handles cluster lifecycle management while allowing customers to maintain control over compute resources and job scheduling policies. PCS integrates natively with AWS services like Elastic File System for shared storage and CloudWatch for monitoring, reducing the integration work typically required for HPC deployments.
Kiro CLI: Kiro CLI becomes exceptionally powerful when you define custom agents with specialized guidance tailored to your specific use cases. By encoding domain expertise directly into agent definitions, you can create purpose-built automation that understands your organization’s best practices and requirements. For example, we’ll create a PCS deployment agent that incorporates AWS Parallel Computing Service best practices for HPC workloads—including optimal instance selection, network configuration, and storage optimization. This agent will leverage established deployment patterns to streamline complex cluster provisioning, reducing both deployment time and the risk of configuration errors. Rather than generic automation, this approach delivers intelligent, context-aware assistance that adapts proven methodologies to your specific infrastructure needs.
Getting Started
Before implementing the automated PCS deployment approach, you need three prerequisites:
- Install the Kiro CLI following the installation guide
- Download the demonstration code from the pcs-kiro demo repository
- Ensure you have local AWS credentials, you can check by running
aws sts get-caller-identity - (Optional) Configure the AWS Knowledge MCP Server using the MCP configuration guide
Using the Agent
First we will initialize the agent.We’ll want to enable the todo list setting on Kiro. This enables more in depth planning for the agent, as it goes through creating a cluster it will create list of tasks and go step by step:
kiro settings chat.enableTodoList true
Start the interactive PCS deployment agent:
kiro chat --agent pcs-interactive-agent
Discovery phase
Now we will ask the agent to help us create a cluster.
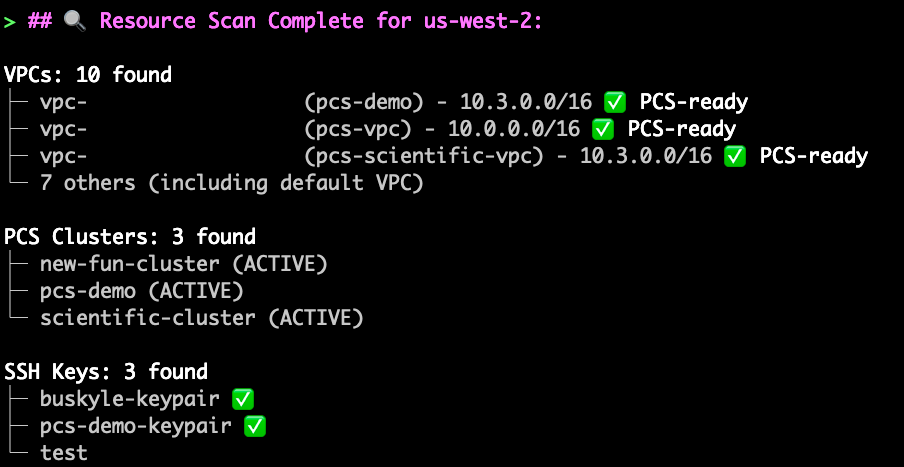
User: I am new to PCS. Help me create my first cluster with best practices.
The agent will first check for active AWS credentials, then respond with some discovery questions if it isn’t sure about details, it will also explore your existing environment, and provide recommendations based on best practices. This is helpful for situations where you want the agent to use existing VPCs or other AWS resources.
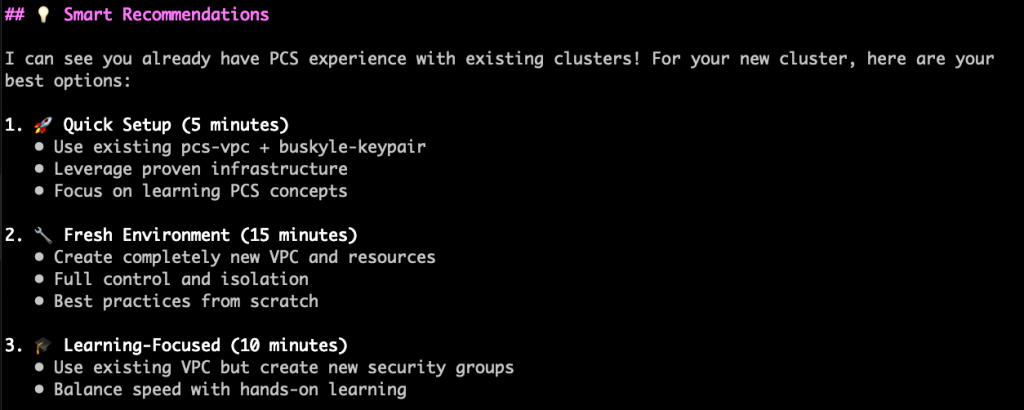

Here you can tweak or provide details and the agent will do a final summary and begin creating infrastructure in your AWS account.
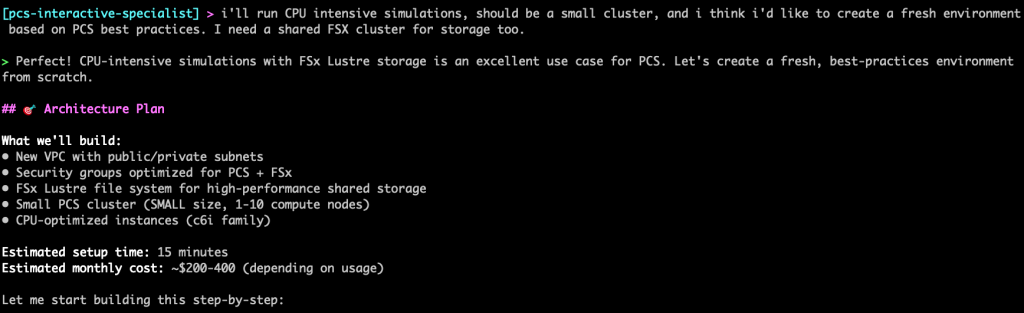
Infrastructure Creation
The provided is a snippet of the infrastructure creation process, depending on your environment and your requirements this output may change.
The agent will then provide details after infrastructure creation is complete. There may be times where a deployment of an AWS resource fails. The instructions the agent has been provided will tell it to troubleshoot those issues and fix them before continuing. The Agent also creates a cluster summary and documentation in the /generated directory that shows exactly what was built and how it was configured.
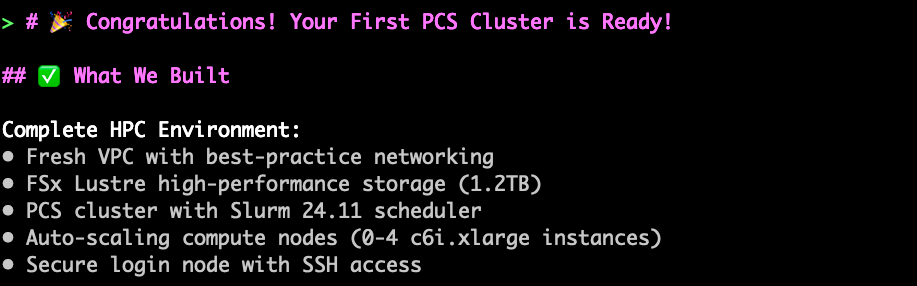
Once complete, the agent will show you how to connect to and test your cluster and provide cost estimates
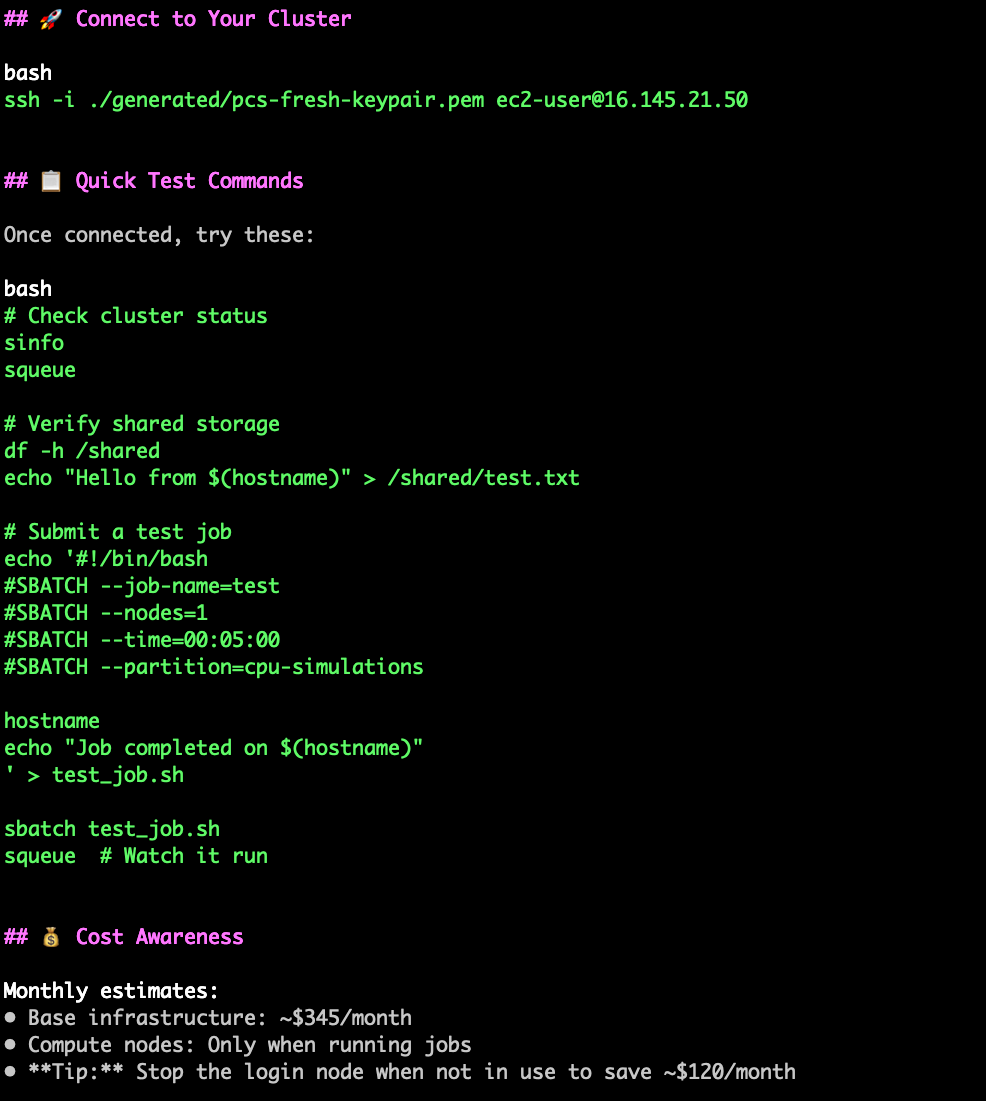
In this small interaction we’ve created a reasonably complex architecture, with a fully functioning network, controller, queue, compute and login nodes, and appropriate templates and roles. All this just by defining our general needs and use case.
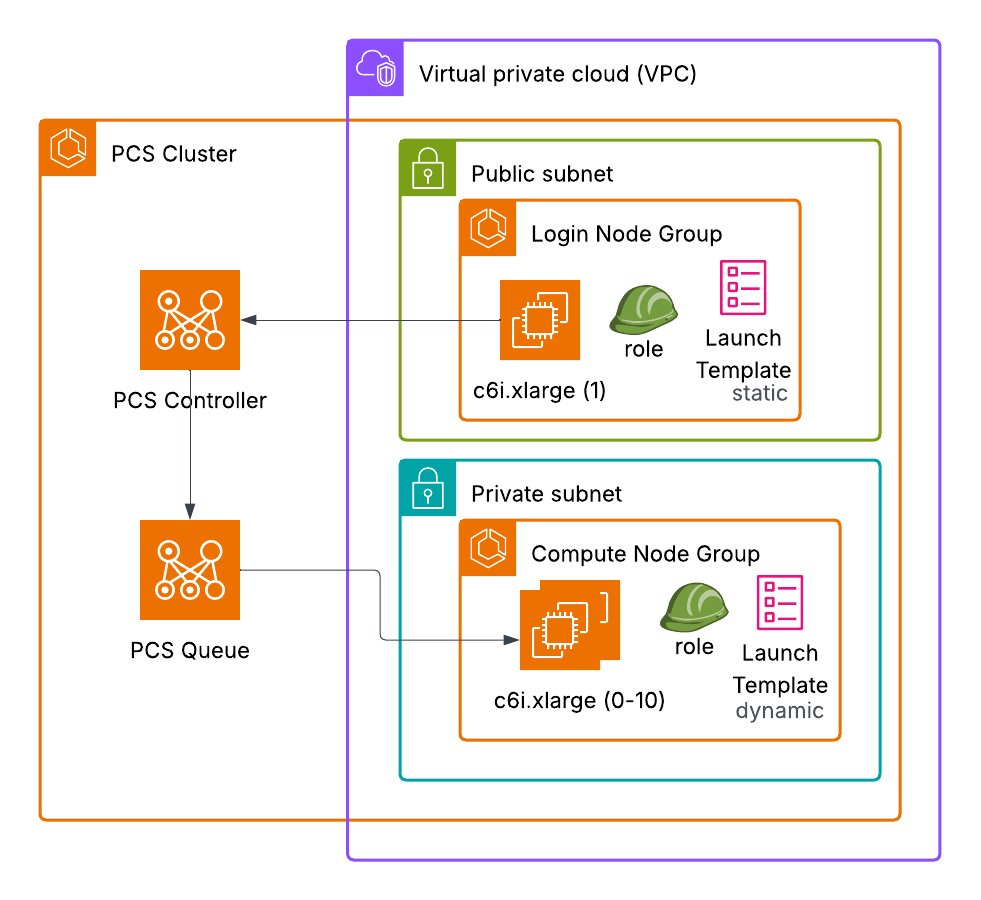
Figure 1: Architecture diagram showing AWS Parallel Computing Service (PCS) cluster deployment within a Virtual Private Cloud (VPC).
The diagram displays a PCS Controller connected to a PCS Queue, both positioned outside the VPC. Inside the VPC are two subnets: a public subnet containing a Login Node Group with one c6i.xlarge instance using a static launch template, and a private subnet containing a Compute Node Group with c6i.xlarge instances (0-10 capacity) using a dynamic launch template. Both node groups include role assignments and are represented with AWS service icons including compute instances and launch template symbols.
All together this processes took about 30 minutes with some user back and forth, and we can immediately log in and start running jobs. This architecture can be extended to include things like shared storage and additional compute node groups and queues.
Suggested Best Practices
- Be direct, verbose and prescriptive with agent instructions
- As an example: In our architecture we didn’t ask for a filesystem but we easily could have asked for an FSx Lustre distributed file system to be set up as well
- Monitor deployments and cancel commands if confused
- Allow occasional failures – agents tend to recovery
- Customize agent configurations for your specific use case
- Provide comprehensive workload context and requirements
Known Limitations
- Agents may lose track of details – remind them as needed
- Manual verification required – check results match your requirements
Conclusion
AWS Parallel Computing Service (PCS) provides research teams with a fully managed HPC service that eliminates the operational complexity of running Slurm clusters at scale. Combined with Kiro CLI’s multi-agent architecture, teams can now deploy production-ready HPC environments in hours rather than weeks. This approach is particularly valuable for research organizations that need computational power without the overhead of managing underlying infrastructure.
Happy Building!