AWS HPC Blog

Author: Austin Cherian
Austin is a Senior Product Manager-Technical for High Performance Computing at AWS. Previously, he was a Snr Developer Advocate for HPC & Batch, based in Singapore. He's responsible for ensuring AWS ParallelCluster grows to ensure a smooth journey for customers deploying their HPC workloads on AWS. Prior to AWS, Austin was the Head of Intel’s HPC & AI business for India where he led the team that helped customers with a path to High Performance Computing on Intel architectures.

Discontinuation of NICE EnginFrame effective September 25th, 2025
After careful consideration, we have made the decision to discontinue NICE EnginFrame including NICE EnginFrame views, effective September 25, 2025. If you want to continue using NICE EnginFrame beyond the end-of-support date, we recommend contacting NI-SP, an AWS partner with decades of experience implementing and supporting NICE EnginFrame for enterprises.

Enhancing ML workflows with AWS ParallelCluster and Amazon EC2 Capacity Blocks for ML
No more guessing if GPU capacity will be available when you launch ML jobs! EC2 Capacity Blocks for ML let you lock in GPU reservations so you can start tasks on time. Learn how to integrate Caacity Blocks into AWS ParallelCluster to optimize your workflow in our latest technical blog post.

Introducing login nodes in AWS ParallelCluster
AWS ParallelCluster 3.7 now supports adding login nodes to your cluster, out of the box. Here, we’ll show you how to set this up, and highlight some important tunable options for tweaking the experience.

Easing your migration from SGE to Slurm in AWS ParallelCluster 3
This post will help you understand the tools available to ease the stress of migrating your cluster (and your users) from SGE to Slurm, which is necessary since the HPC community is no longer supporting SGE’s open-source codebase.

Migrating to AWS ParallelCluster v3 – Updated CLI interactions
The AWS ParallelCluster version 3 CLI differs significantly from ParallelCluster version 2. This post provides some guidance on mapping between versions to help you with migrating to ParallelCluster 3. We also summarize new CLI features in ParallelCluster 3 to expose the things you just couldn’t do previously.
GROMACS performance on Amazon EC2 with Intel Ice Lake processors
We recently launched two new Amazon EC2 instance families based on Intel’s Ice Lake – the C6i and M6i. These instances provide higher core counts and take advantage of generational performance improvements on Intel’s Xeon scalable processor family architectures. In this post we show how GROMACS performs on these new instance families. We use similar methodologies as for previous posts where we characterized price-performance for CPU-only and GPU instances (Part 1, Part 2, Part 3), providing instance recommendations for different workload sizes.

Introducing AWS ParallelCluster multiuser support via Active Directory
Today we’re announcing the release of AWS ParallelCluster 3.1 which now supports multiuser authentication based on Active Directory (AD). Starting with v3.1.1 clusters can be configured to use an AD domain managed via one of the AWS Directory Service options like Simple AD or AWS Managed Microsoft AD (MSAD). This blog post describes the new feature, and gives an example of a configuration block for ParallelCluster 3 configuration files.

Using the ParallelCluster 3 Configuration Converter
ParallelCluster 3 was a major release with several changes and a lot of new features. To help get you started migrating your clusters, we describe the config file converter tool which is part of the ParallelCluster (>= v3.0.1) command line interface (CLI).
Deep dive into the AWS ParallelCluster 3 configuration file
In September, we announced the release of AWS ParallelCluster 3, a major release with lots of changes and new features. To help get you started migrating your clusters, we provided the Moving from AWS ParallelCluster 2.x to 3.x guide. We know moving versions can be a quite an undertaking, so we’re augmenting that official documentation with additional color and context on a few key areas. With this blog post, we’ll focus on the configuration file format changes for ParallelCluster 3, and how they map back to the same configuration sections for ParallelCluster 2.
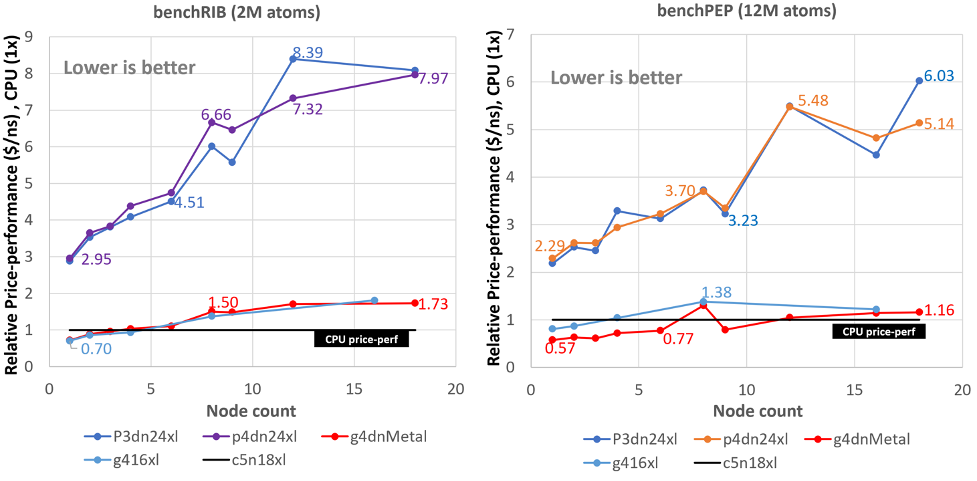
Running GROMACS on GPU instances: multi-node price-performance
This three-part series of posts cover the price performance characteristics of running GROMACS on Amazon Elastic Compute Cloud (Amazon EC2) GPU instances. Part 1 covered some background no GROMACS and how it utilizes GPUs for acceleration. Part 2 covered the price performance of GROMACS on a particular GPU instance family running on a single instance. […]