AWS HPC Blog
Running GROMACS on GPU instances: multi-node price-performance
This three-part series of posts cover the price performance characteristics of running GROMACS on Amazon Elastic Compute Cloud (Amazon EC2) GPU instances. Part 1 covered some background no GROMACS and how it utilizes GPUs for acceleration. Part 2 covered the price performance of GROMACS on a particular GPU instance family running on a single instance. Part 3 (this post) will cover the price performance of GROMACS running across a set of GPU instances, with and without the high speed networking capabilities of Elastic Fabric Adapter (EFA).
Multi-node performance
We will now investigate performance increase by scaling across multiple nodes. Price-performance comparisons across the three workloads will give you some guidance on selecting the right instance to scale your GROMACS workloads on AWS GPU instances.
We start with comparing the small and medium sized workloads to check on performance and price-performance.

Figure 1: Multi-node performance comparison of benchMEM, comparing GPU and CPU instances.
From the previous post on results analyzing single-node instance performance, both the small- and the medium-size workloads show performance gains by scaling up the instance in terms of both CPU core counts and number of GPUs. However, for the small-sized workload, we saw that the scale-up efficiency on larger, more powerful, GPU instances is significantly lower due to the workload not being able to utilize the full performance of the larger GPU instances. We will hence only consider performance analyses on g4dn.16xlarge instances (largest CPU-to-GPU ratio for the g4dn family) for the scaling study of the small- workload but include other larger GPU instances in our experiments for the medium- and large- workloads. We will also include comparisons to results on CPU instances to make some suggestions on instance selection.
As can be seen on Figure 1, for the small- workload case the performance drops when we tried to scale across 2 nodes and beyond. However, CPU only instances equipped with Elastic Fabric Adapter (EFA) Performance networking, showed significant performance scaling up to 4 nodes and started to taper off around 8 nodes.
For the medium-sized workload, as indicated in Figure 2, we see a gain in performance by increasing the number of instances and again we see the effect of communication overhead becoming more dominant as the node count increases.

Figure 2: Graph on the left compares multi-node performance for CPU and GPU instances. Graph on the right shows multi-node price-to-performance scaled across multiple GPU instances, and comparison with CPU instances.
Taken all together, the benchmark data shows that for small-to-medium size workloads you are better off using CPU instances to increase performance using multi-node scaling beyond a few nodes, and GPU instances for single-node performance.
Next, let’s look at the medium- and large-sized workloads when scaling them across more powerful multiple-GPU instances. We include comparisons with CPU scaling to have a complete picture when looking at instance selection. Figure 3, show the performance comparison across multiple GPU instances and a CPU only instance equipped with EFA performance networking.

Figure 3: Performance (ns/day) comparison while scaling the simulation across single-GPU, multi-GPU and CPU instances enabled with EFA.
In the case of both the medium- and large-sized workloads, larger GPU instances like p3dn.24xl, g4dn.metal and p4dn.24xl exhibit significant scaling until around 8 instances. After that, the parallel efficiency starts to flatten off. You can see that g4dn.metal still beats all the others. Using CPU instance performance for a quick comparison shows that for the medium-size workload, the performance differential between the CPU and GPU starts to reduce beyond 18 nodes. However, for the larger-sized workload, there’s significant performance differential (GPU is higher performance) compared to CPU scaling for 18 nodes and beyond.
The conclusion? When pure performance is your goal, GPU instances will give you the fastest time to result for workloads in the medium-to-large range.
Also worth mentioning is that we have included scaling data for p4dn.24xlarge instances with EFA turned off. All the other instances included in the scaling study except the g4.16xlarge are equipped with the EFA. This is essential to achieve the scaling results here – without the use of EFA, performance plateaus beyond 4 nodes.
The somewhat unexpected dip in simulation performance at 8 nodes results from an unlucky combination of constraints on the total number of MPI processes. GROMACS needs to automatically offload the non-bonded interactions to GPUs, and the number of domain decomposition (DD) domains must either be equal to the total number of available GPUs or a factor of that. Since the P3dn, P4dn, and G4dn instances have 8 GPUs each, it means the number of MPI ranks must be 64 or 128, or 192, etc. Since a domain has a certain minimum size in GROMACS (depending on the cutoff radius among other things), the maximum number of allowed domains in the RIB benchmark is 7 x 7 x 6 (in terms of x, y, and z), which excludes having 128 or 192 or more MPI ranks on 8 nodes. Only 64 MPI ranks are possible, leading to somewhat sub-par performance in contrast to 6 or 9 nodes, where 48, 96, and 144 MPI ranks all can be chosen alternatively.
If you think that’s subtle: you’re right. But this is how the cards often fall in HPC.
Finally, let’s look at price-performance considerations for both the medium and large workloads.
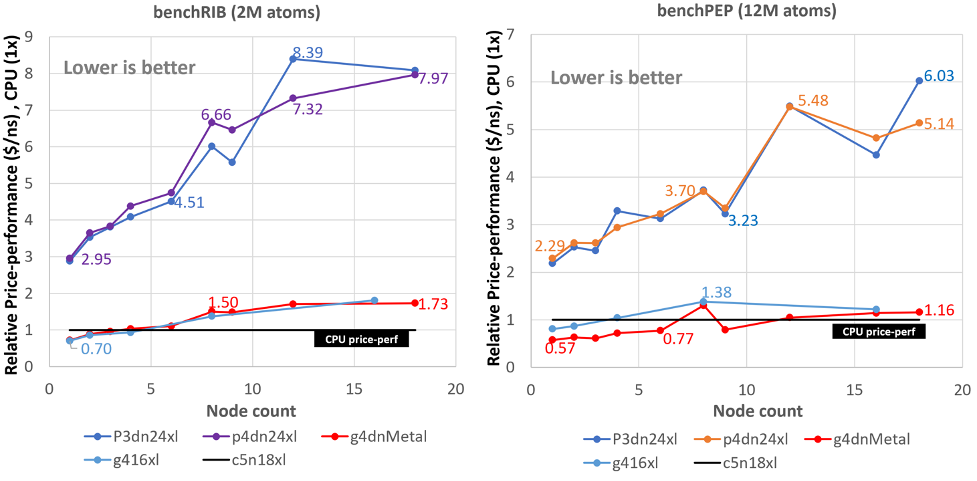
Figure 4: Relative price-to-performance ratio ($USD/ns) while scaling the simulation across single and multi-GPU instances and comparing to CPU (EFA enabled) price-to-performance (baseline CPU performance).
Taking CPU price-performance as a baseline, for the medium size workload at higher node counts (16 nodes) the price-performance differential is large (up to 8X) between GPU and CPU instance for the larger more powerful GPU instances (p3dn.24xlarge and p4dn.24xlarge) with the exception of G4dn.metal. Whereas for the large workload the efficiency is better where the performance differential is around 6X indicating that a larger workload when scaled exhibits better price performance over the smaller or medium sized workloads. Overall, Figures 3 and 4 show that the g4dn.metal instance is the best across the board (including comparing with CPU instances) when it comes to price performance, as well as pure performance.
Conclusion
As we saw in the previous post on single-node performance, GROMACS is able to make effective use of all the hardware (CPUs, GPUs) available on a compute node to maximize the simulation performance, it is equipped with a Dynamic Load Balancing algorithm which coupled with optimal decomposition and MPI ranks vs threads for single-node GPU instances provides good performance.
We saw for single-node performance that the G4dn instance family gave the best results for both raw single-node performance and best price-performance than any other GPU instance. We also note that the G4dn family gives much better (3X to 4X) performance-to-price ratio than the best CPU instance (c5n.24xlarge).
In this post, we showed that if you plan to scale your simulation (i.e., multi-node runs) using GPU instances, the g4dn.metal instance is still the best across the board when it comes to both pure performance as well as price-performance. However, scaling your simulation on GPU instances to high node counts (depending on the workload) will start to show significant loss in parallel efficiency for GPU instances. In general CPU Instances equipped with EFA high performance networking are more suited for extreme scale-out simulations when price-performance is the key consideration.
To get started running GROMACS on AWS, we recommend you check out our GROMACS on AWS ParallelCluster workshop that will show you how to quickly build a traditional Beowulf cluster with GROMACS installed. You can also try our workshop on AWS Batch to run GROMACS as a containerized workload. To learn more about HPC on AWS, visit https://aws.amazon.com/hpc/.