AWS HPC Blog
Bursting your HPC applications to AWS is now easier with Amazon File Cache and AWS ParallelCluster

This post was contributed by Shun Utsui, Senior HPC Solutions Architect, Austin Cherian, Senior Product Manager
Combining on-premises and cloud computing resources has emerged as a powerful solution for organizations seeking to meet their computing needs. While you can target compute to be on-premises or in the cloud, your workloads’ accessibility to data in a fast and secure manner is critical to its performance.
Customers have asked for more flexibility to send their workloads to AWS while keeping some data primarily on-premises, so today we’re announcing support for Amazon File Cache in ParallelCluster 3.7.
Amazon File Cache offers a high-speed cache on AWS to facilitate efficient file data processing, regardless of its storage location. File Cache serves as temporary, high-performance cache layer in the cloud, for data stored on-premises. Once configured, workload data moves from on-premises storage to AWS as the workload accesses it via File Cache, which appears to the compute client as a Lustre file system.
In this post, we’ll walk you through the features of File Cache that are important for HPC environments, and show you, step-by-step, how you can quickly deploy this and try it out for yourself.
Introducing Amazon File Cache
Previous versions of ParallelCluster already supported mounting multiple FSx file systems. A File Cache can be attached to a cluster using the same familiar mechanisms. These configurations are useful for building “cloud bursting” scenarios: you can attach a File Cache to your ParallelCluster and submit jobs to the cluster either through a federated cluster on-premises like a stretch cluster in Slurm, or by logging into the ParallelCluster directly.
But beyond just data accessibility, there are other considerations that make Amazon File Cache an effective choice for your hybrid HPC use cases.
Scalability & Performance: Amazon File Cache is built on Lustre, the popular, high-performance file system, and provides scale-out performance that increases linearly with the cache storage capacity. File Cache is designed to accelerate cloud bursting workloads using cache storage designed to deliver sub-millisecond latencies, up to hundreds of GB/s of throughput, and millions of IOPS.
Data Management & Security: Data encryption, access controls, and backup mechanisms ensure data integrity and confidentiality with robust storage solutions. File Cache provides data protection by encrypting data at rest and in-transit between the cache and Amazon Elastic Compute Cloud (Amazon EC2) instances. You can use AWS Key Management Service (KMS) to manage the encryption keys that are used to encrypt your data. File Cache also supports the use of AWS PrivateLink to access your cache resources without going over the internet. You can use Amazon Virtual Private Cloud (VPC) to control access to your cache resources by configuring the VPC Network ACLs to control access to your cache resources. Network ACLs enable you to create a firewall that controls inbound and outbound traffic at the subnet level.
Cost optimization: File Cache offers a flexible pricing model so you only pay for the resources you use and there are no minimum fees or setup charges. While pricing is quoted on a monthly basis, billing is per-second.
Reference Architecture
Amazon File Cache can be associated with Amazon S3 buckets or Network File System (NFS) file systems that support NFS v3. Figure 1 shows a typical architecture for a hybrid HPC environment.
Customers with large-scale HPC resources in their own data centers often already have a parallel file system for storage, like Lustre which can be exported using NFS.
To deploy a hybrid infrastructure pattern like this, you’ll need to connect your corporate data center to your VPC using either an AWS Site-to-Site VPN, or an AWS Direct Connect.
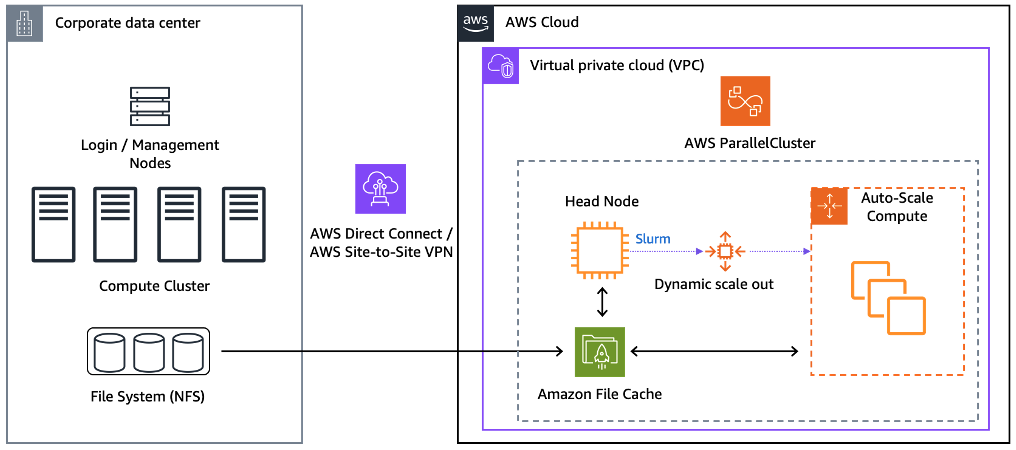
Figure 1 – High-level architecture of Amazon File Cache in AWS ParallelCluster with a data repository association (DRA) to an on-premises HPC storage system. To link an on-premises parallel file system to File Cache you can export the file system over NFS v3.
Deployment details
Attaching an Amazon File Cache to a ParallelCluster is straightforward. Let’s walk through a typical work flow so you get the idea. We’ll assume you already have an operational ParallelCluster.
Step 1. Create a Security Group for Amazon File Cache following the “Cache access control with Amazon VPC” section of the File Cache user guide.
Step 2. Create a cache following the “Create your cache” section of the File Cache User Guide. Copy the File Cache ID to the clipboard.
Step 3. Now we’ll modify the ParallelCluster configuration file. If you have an existing cluster deployed through ParallelCluster, you should have a YAML file that you specified during the deployment.
The ParallelCluster configuration file is written in YAML and it defines the resources for your HPC cluster. You can refer to the ParallelCluster User Guide to find out more about the details the file format.
Under the SharedStorage section of the configuration file, add StorageType: FileCache with the name of the file system, the mount directory, and the File Cache ID that you copied onto your clipboard in the previous step.
In this example, we’re configuring the cache to be mounted under the /cache directory.
SharedStorage:
- Name: FileCache0
MountDir: /cache
StorageType: FileCache
FileCacheSettings:
FileCacheId: <your_file_cache_ID>
You also need to specify the security group associated with the File Cache. Under the HeadNode section and the Scheduling section, enter the security group ID you just created in Step 1 (note that this entry has to be defined under both the HeadNode and the Scheduling section, otherwise the cache won’t be mounted on the entire cluster).
If you’re configuring multiple queues, you’ll need to specify the AdditionalSecurityGroups string under the Networking section of all your queue definitions.
Networking:
SubnetId: <your_subnet_ID>
AdditionalSecurityGroups:
- <file_cache_security_group>
Step 4. Update your running cluster.
First, you’ll need to stop the compute fleet so you can update the cluster.
pcluster update-compute-fleet --status STOP_REQUESTED -n <cluster name>Once the compute fleet is stopped, update your cluster with the update-cluster sub-command.
pcluster update-cluster -c <configuration file name> -n <cluster name> This will take about 10 minutes for the cluster update to complete. Once the update is complete, start the compute fleet again:
pcluster update-compute-fleet --status START_REQUESTED -n <cluster name>Confirm that your compute fleet’s status is “RUNNING” with the describe-compute-fleet sub-command.
pcluster describe-compute-fleet -n <cluster name>You can now login to the head node and check that the cache is mounted under the directory you specified. In our example, we mounted the cache under the directory /cache, which we’ve shown in Figure 2. You should now be able to access your cache like any other file system on a Linux machine.
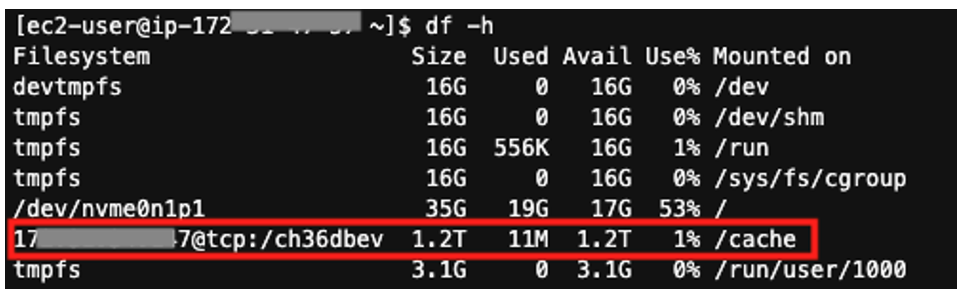
Figure 2 – Amazon File Cache mounted on /cache in AWS ParallelCluster
Step 5. Now run your HPC workload on the cluster, using your new cache, and then export results to the data repository. You should be able to list files that you have already uploaded into your data repository.
When a file is uploaded onto the data repository, Amazon File Cache will only fetch the metadata. At this point, the data itself is kept in the origin repository, and is only retrieved to the cache when accessed from an Amazon EC2 instance. This means the file access latency will be slightly higher for the first access, but will drop to a sub-millisecond levels once the content has cached. This is called lazy loading, and saves a lot of bandwidth between sites when you’re mounting a cache connected to a large remote file system.
Similarly, you can also release a file from the cache without removing the metadata on it. Once your job is completed and the cache is no longer needed, we recommend you export the data onto the data repository and clear the cache. To force exporting of the data from the cache, you can run a command like this:
nohup find <target directory on cache> -type f -print0 | xargs -0 -n 1 sudo lfs hsm_archive &Once the data export task is finished, you can evict the cache to free up capacity. To do that, run the following command on the files you want released:
lfs hsm_release <file>Find out more about exporting changes to the data repository and cache eviction in the official Amazon File Cache user guide.
Step 6. (optional) Remove the cache from the cluster and delete it. Once files are exported onto the data repository and the cache is cleared, you can remove the cache. To do that, open your ParallelCluster configuration file and remove the parts that you added in Step 3. Then, execute the exact same commands as in Step 4 to update the cluster. When the cluster is updated and the cache is not mounted anymore, you can safely delete it (follow these steps for more detail) to save cost.
Verifying the effects of Amazon File Cache and lazy loading
To highlight the effect of Amazon File Cache and its lazy loading feature, we ran the IOR parallel I/O benchmarks. We created a multi-Availability Zone (AZ) environment to mimic a hybrid HPC set up. AZs are physically separated by a meaningful distance from other AZs in the same AWS Region, but they are all within 60 miles (~ 100 kilometers) of each other.
First, we created a ParallelCluster in an AZ that we randomly selected in the North Virginia Region (us-east-1c). Then, we created an EC2 instance with an Amazon EBS volume attached to it in the same region, but in another AZ (us-east-1b).
Next, we configured that EC2 instance to become an NFS server that exports the EBS volume we attached.
Back in us-east-1c, we created a cache in the same AZ as our ParallelCluster. Then, we linked the cache to the NFS serving EC2 instance in us-east-1c as its data repository.
Figure 3 illustrates this configuration.
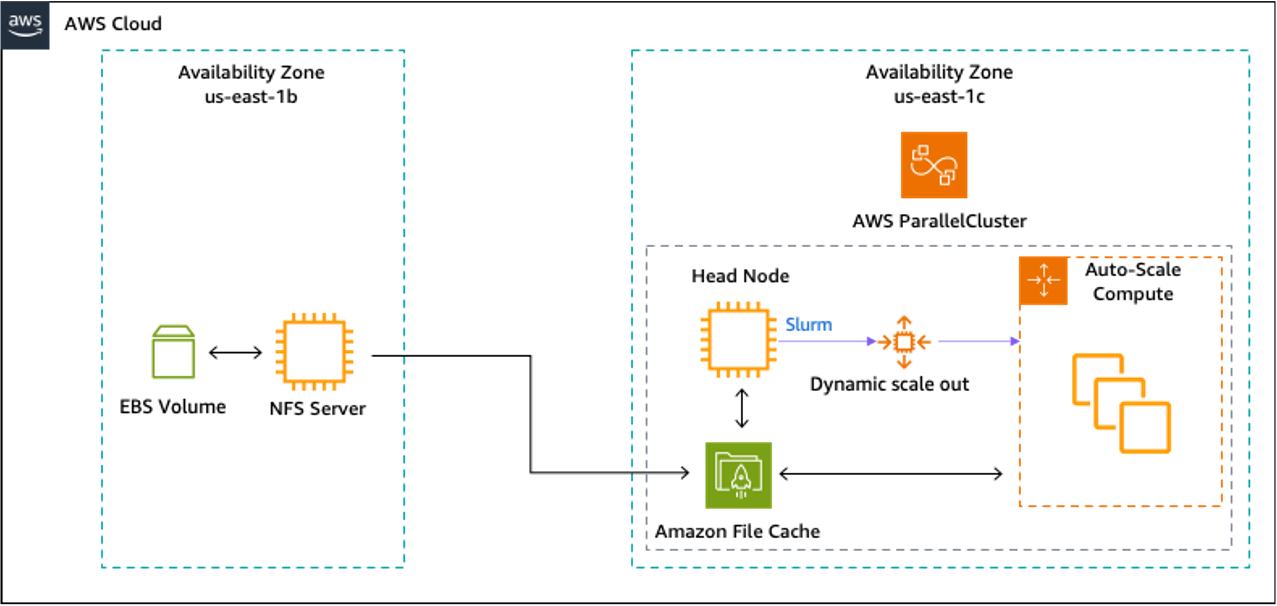
Figure 3 – High-level architecture for IOR Parallel I/O benchmarks. The EC2 instance in us-east-1b is an NFS server that exports the EBS volume over NFS v3, which is then linked to Amazon File Cache in us-east-1c as a data repository.
We submitted our first IOR job onto the cluster to see the write performance to the cache. For this job we used 8x hpc7g.16xlarge instances (which have 64 physical cores per instance), and using all 512 cores in parallel. Each core runs a process which writes a 3.2 GiB file onto the cache, 1.56 TiB of data in aggregate. We instructed the job to run 5 times, so we could see a consistent trend.
On a cache that we sized at 4.8 TiB (corresponding to a baseline performance of 4.8 GiB/s) we saw consistent write performance at around 4.48 GiB/s in all 5 iterations of the job. Results of the write performance test are shown in the graph in Figure 4.
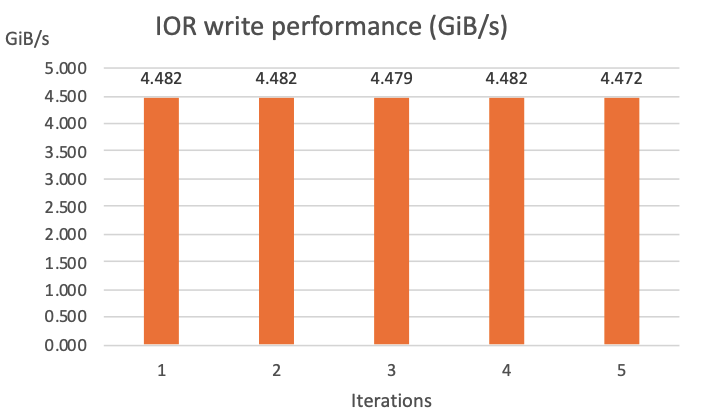
Figure 4 – A bar graph of IOR write performance tests. Performance is consistent across all 5 iterations.
We wanted to see the difference in read performance for the first and subsequent reads, so next we ran a read-performance test on the data set that we generated during our write-performance test.
To avoid reading the data from the cache for the first iteration, we cleared the cache following the instructions in Step 5.
We also used the same compute resources to perform the write test that we used for the read test. Like before, we instructed the job to run 5 iterations so that during the first iteration, the files are ingested from the data repository into the cache. For the subsequent iterations, the job will read the files from the cache. Results of the read-performance tests are shown in the graph in Figure 5.
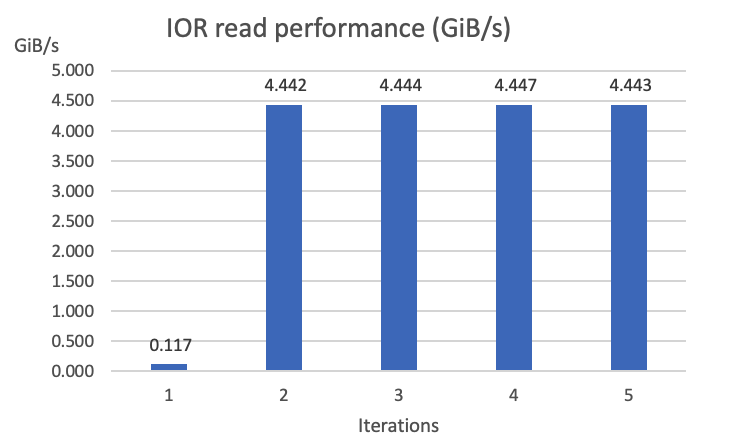
Figure 5 – A bar graph of IOR read performance tests. The first iteration is slower because the data is retrieved from the data repository through the lazy loading mechanism. The subsequent iterations are consistently fast because data is read from cache.
The results show that the first iteration achieved around 0.12 GiB/s throughput, and in all the subsequent iterations it was consistently around 4.44 GiB/s (around 37 times better!).
During the first read, the workload loaded the entire data set of 1.56 TiB onto the cache from the data repository, which resides in another AZ, a physically distant location. Hence the performance was slower. From the second read onwards, the workload read the data only from the cache.
Of course, the performance gap between the first and subsequent iterations is dependent on a lot of factors including aggregate size of the data being transferred, some features of the data set (e.g. many small files vs one big file), the network bandwidth, and the NFS server specification. Your mileage will vary, but you can test it quite quickly yourself, using the steps we’ve outlined in this post.
Conclusion
In this post we introduced you to the new Amazon File Cache integration feature with AWS ParallelCluster 3.7 to create a hybrid HPC environment with low latency to access your data.
We walked you through the details of how to set up File Cache with ParallelCluster and showed you some benchmarks to highlight how lazy-loading can drastically improve IO performance in a hybrid scenario.
When you consider Amazon File Cache as a solution for your hybrid workloads, you should consider the trade-offs between cost, performance, and (of course) business value. As we’ve seen with the IOR benchmarks, for data intensive workloads that read large data sets from the repository for the first time, it’ll take more time for a job to finish due to file access latency.
Customers who require predictability in performance for every single job, might want to consider other AWS services. AWS DataSync, for example, can sync data between your site and AWS to maintain a constantly up to date mirror. This will ensure the workload you run on AWS will access its input data with low latency.
Amazon File Cache is a powerful tool that enables customers to access their data on a cache with sub-millisecond latency. Support for Amazon File Cache is a great addition to AWS ParallelCluster for hybrid HPC workloads, making it easy for customers to deploy an HPC environment on AWS in a matter of minutes with a cache linked to data in their own data centers.