AWS for Industries
How to Architect Data Quality on the AWS Cloud
Financial institutions such as FINRA, Nasdaq, and National Australia Bank have built data lakes on AWS to collect, store, and analyze increasing amounts of data at speed and scale. A data lake allows organizations to break down data silos and store all of their data – structured, semi-structured, and unstructured – in a centralized repository at any scale.
As an example, in order to comply with Anti Money Laundering (AML) compliance requirement, a financial institution needs to detect and report suspicious activities, such as security fraud and market manipulation. Criminals use money laundering techniques to conceal their activities. In order to properly track, trace, and uncover such activities, a financial institution should collect and centralize transactions from all lines of business and their respective applications, create a 360-degree view of the customer, product, and transactions, and apply AML detective analytical scenarios.
One of the key components to creating and maintaining an effective data lake is data governance. Data governance refers to a framework that includes people, processes, and technology that enables business users to work collaboratively with technologists to drive clean, certified, and trusted data. Without governance, a data lake becomes a data swamp where data continues to be consumed in a siloed manner without consistency and accuracy. As a result, the original issue is not fixed, it just resurfaces on a new platform.
A data governance framework consists of multiple components, including data quality, data ownership, data catalog, data lineage, operation, and compliance. In this blog we will be focused on data quality.
There are two types of data quality issues that can arise in a data lake.
The first is operational where information such as a customer’s birth date or address is entered incorrectly by a person or a system. This type of data quality issue should be assigned to the source application owner and be remediated at the source system. One example of remediation would be scrubbing, which includes reaching out to the customers to confirm certain information or referencing the original onboarding documents. Another form of remediation would be to leverage data quality metrics to enhance business processes. For example, if the majority of customer birth dates are null, the source system’s application can be updated so that it requires a valid date of birth before allowing a customer to be onboarded. Additionally, machine learning capabilities such as computer vision and optical character recognition (OCR) could be used to automatically extract a customer’s name, address, and birth date from their driver license, and therefore, minimizing errors resulting from manual data entry.
The second type of data quality issue is introduced when data siloes are being integrated into the data lake. During this integration process, data from various source systems are fed into a centralized data lake, often resulting in the same attributes having different values and formats. These attributes are maintained on siloed databases at the source system as their usage is directly linked to the operation of the source system. Therefore, it is natural for the various data siloes to have inconsistent values for the same attributes. While this scenario is considered a data quality issue for the data lake, it cannot be considered the same for the source system. This type of data quality issue requires the integration job to include additional logic to conform critical data elements to standardized, consistent values if a change in source system is not feasible. For example, if the customer’s birth date is not populated for their loan application, the bank can leverage another data source and populate this field from the customer’s deposit record.
To address both types of data quality issues discussed earlier, it is imperative for customers that are leveraging data lake architectures to have a well-defined data quality framework. This framework should include:
- An end-to-end data quality lifecycle
- Responsibility model
- The technology to enable the objective
Data Quality Lifecycle
The Data Quality Lifecycle is a sequence of processes that data quality projects go through from initiation to its closure, and includes the following (see figure 1):
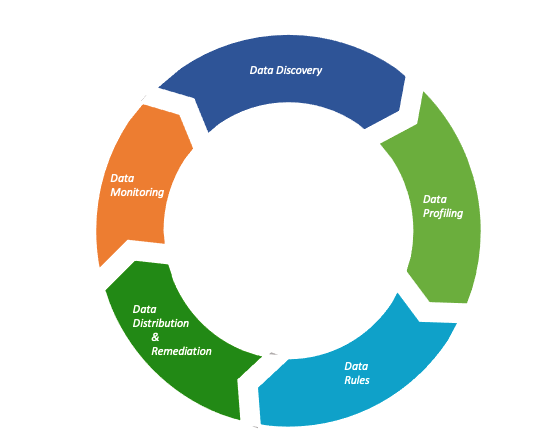 Figure 1
Figure 1
Data Discovery: Requirement gathering, source application identification, data collection, organization, and data quality report classification
Data Profiling: Initial examination, sample data quality check, rule suggestion, and approval of final data quality rule
Data Rules: Execution of final business rule to examine accuracy of the data, and its fit for purpose
Data Distribution and Remediation: Process of distributing the data quality reports to the responsible parties and start of remediation process
Data Monitoring: Ongoing monitoring of remediation process, and creation of data quality dashboards and score cards
Responsibility Model
The responsibility model of the data quality framework is focused on identifying roles and responsibilities.
Establish ownership: An effective data quality framework requires executive sponsorship. This includes identifying source application executive owners such as LoanOps, TrustOps, etc. Any extract created by source system applications should be owned by the same application owner. This ensures that the file extracts are part of the source application architecture, and not the destination platform. Files should be maintained, cataloged, and supported by the same resources who support the application and included as part of all application-level upgrades and changes. In addition to the source system files, all data domains within data lake, and downstream applications receiving data from the data lake should have identified owners.
This practice influences data owners to follow best practice of consolidating file extracts and leveraging central data repositories like data lakes to decrease their scope. As a result, duplicated extracts, number of production jobs, and quality reports will drastically decrease.
Data stewardship: Identify data stewards across all source applications, target applications, and data lake domains. Data stewards are individuals who understand data production, usage, quality, and consumption of their respective areas.
Scrubbing/Remediation owner: Identify individuals that are directly assigned to improving the quality of the data. This can include any task from scrubbing to process change.
Data office: Identify end-to-end oversight, control, and quality reporting resources. They are the custodians of the data quality progress dashboard, score cards, and enterprise-wide quality insight.
A sample data lake architecture is illustrated in figure 2. In this example, a risk data domain is being produced by integrating siloed customer and product data feeds from loan and credit card services. Operational data quality reports are owned and remediated by loan, and credit card data stewards. Integration data quality reports are owned by the risk officer, and remediated by risk, loan, and credit card data stewards. The data office provides end-to-end governance, coordination, and an executive-level progress dashboard.
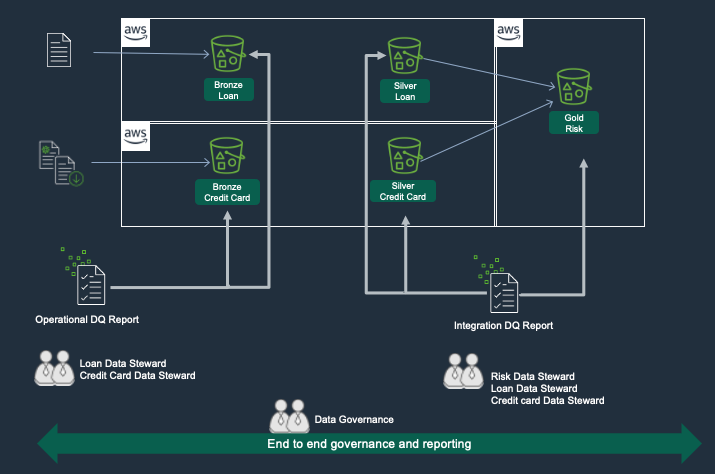 Figure 2
Figure 2
Putting everything together, a data quality development request cannot be submitted to the data lake engineering team without:
- Classification (Source system data quality vs integration data quality)
- Ownership (overall business owner, data steward, scrubbing owner)
- Remediation plan
- Ongoing data quality monitoring
Once an overall data quality framework has been defined, the lifecycle established, and owners identified, it is time for the technology team to decide on technology tooling and implementation.
Technology
The design and architecture of your organization’s data quality process should take into consideration rapidly changing business requirements, and therefore be designed to self-adjust so that it does not impact the development and implementation of the data pipeline. It should decouple the data quality programs from the extract, transform, load (ETL) jobs, and should adopt an event-driven architecture, where the handshaking between data quality and ETL is developed and accomplished on an asynchronous basis.
With traditional data engineering platforms such as relational databases or data warehouses, data quality is checked upfront, which results in the ETL logic taking longer to be coded and released. With a data lake architecture, organizations can move the file through the data pipeline and generate decoupled data quality processes to capture and report on the data quality independently. This allows the end data consumers to decide if the data is of acceptable quality or not. For example, a data scientist might be willing to use data where 10% of the data has data quality issues, but a financial reporting analyst may require data that has no data quality issues.
We will illustrate the third component of the data quality framework – the technology required for implementation – by walking through an example use case, following the data quality lifecycle process and responsibility model described previously:
Data discovery -> Data profiling -> Data rules -> Data distribution and remediation -> Data monitoring
Which services are we leveraging?
- Amazon Simple Storage Service (Amazon S3) – an object storage service to stores your documents and allows for central management with fine-tuned access controls.
- AWS Lambda – a serverless compute service that runs code in response to triggers such as changes in data, shifts in system state, or user actions. Because S3 can directly trigger a Lambda function, you can build a variety of real-time serverless data-processing systems.
- Amazon DynamoDB – a key-value and document database that delivers single-digit millisecond performance at any scale.
- Amazon QuickSight – a scalable, serverless, machine learning powered business intelligent (BI) service built for the cloud.
- Amazon Athena – an interactive query service that makes it easy to analyze the data on Amazon S3 using standard SQL.
- Amazon SNS – Amazon Simple Notification Service (SNS) is a fully managed messaging service for both application-to-application (A2A) and application-to-person (A2P) communication.
Data Discovery
Let’s assume that we have a global customer loan file in CSV format with the following columns that we are looking to ingest into the data lake. File includes loan level information to support call report – schedule RI – interest and fee income on loan:
- Customer’s full name
- Customer type with two possible values: “individual” or “commercial”
- Customer’s last four digits of their social security number
- Customer’s loan outstanding balance
- Customer’s loan interest income
- Customer’s loan fee income
- Customer’s loan secured by real estate type
- Customer’s country of residence
Data Profiling
Once the dataset and data source has been identified, the data steward and data governance office will conduct data profiling, which includes an initial examination of the data, a sample data quality check, rule suggestion, and approval of final data quality rules. See figure 3.
- The data steward and the data governance office will select an initial set of data quality metrics to run against all new incoming files. In this example, we will take a subset of the global customer file and profile the data using the following set of metrics:
-
- Completeness of data (i.e., are there any fields with missing data)
- Distinct count on customer type
- Distinct count on country of residency
- Distinct count on loan secured by real estate type
- Data type on the last four digits of the SSN
- Data type on outstanding balance, interest income, and fee income
- The profiling instructions are registered in a metadata table in Amazon DynamoDB via “Metadata Registerer API.”
- The sample file is provided and the discovery API call is invoked. The discovery API references the metadata table and runs the profiling rules against the sample file.
- Two files are generated and saved into an Amazon S3 bucket: profiling exception report and suggestion report.
The data profiling process will provide an output similar to the following:
- There are four entries with missing values for the field “Country of Residence”
- The “Customer type” field has two distinct values: “Individual” and “Commercial”
- The “Country of Residence” has distinct value of UK, US, and Null
- Loan secured by real estate has distinct values of “secured by 1-4 family residential property” and “other”
- SSN is an integer data type
- Outstanding balance, interest income, and fee income are decimal data type
Once the profiling step is completed, the results are passed to the suggestion module. This module provides recommendations based on results of the profiling module. Suggestions can range from data type checks to acceptable values.
- Business users can access the files via Amazon Athena and finalize the data quality rule. Suggestions can be accepted, rejected, or enhanced by business users.
- The results of the final rules are registered in Amazon DynamoDB metadata services
This is an example of a baseline quality report that can be used by LOB data stewards, technologists, and the data office to finalize the data quality scope of this file.
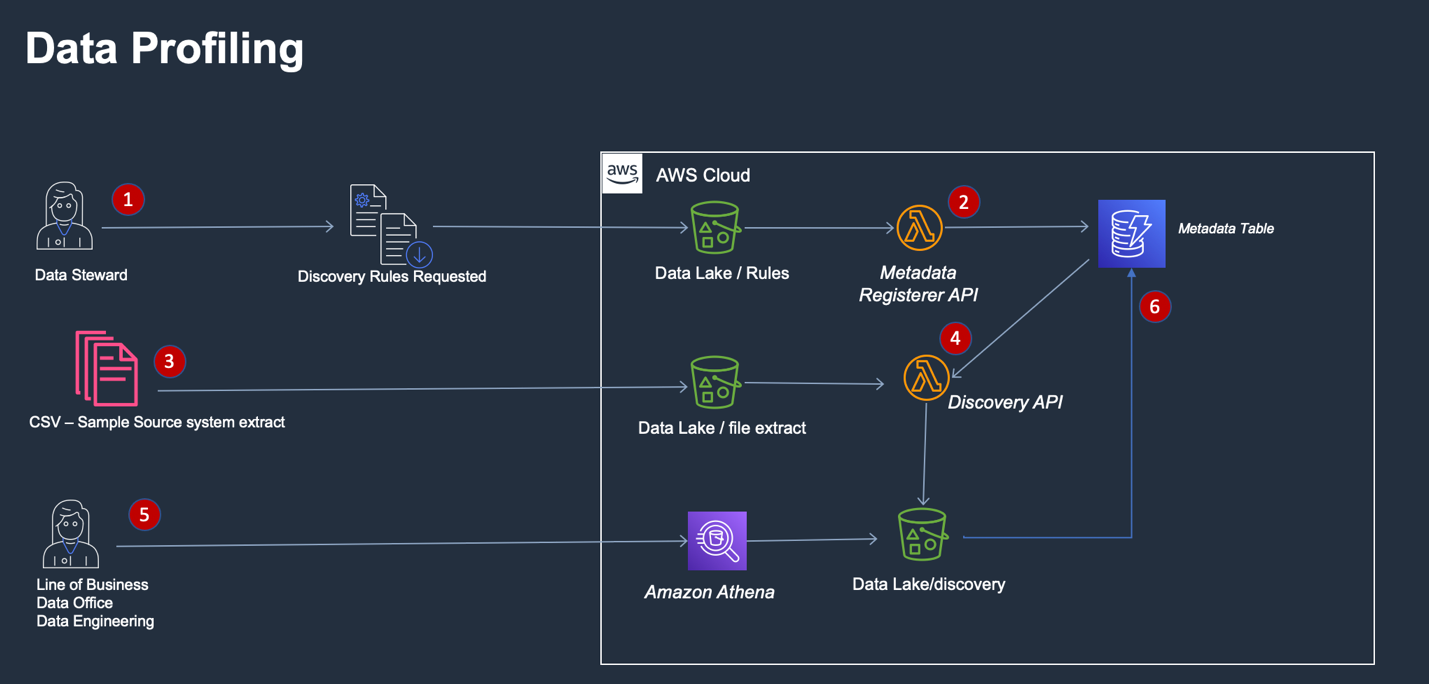 Figure 3
Figure 3
Data Rules
Once the data quality profiling rules are finalized, it will be fed to the verification phase where actual data quality verification is performed on incoming files to examine the accuracy of the data and whether the data is fit for purpose. The data quality results are saved to Amazon S3. See figure 4.
- From the source system, the full global customer CSV file is uploaded to the S3 bucket.
- The data quality verification AWS Lambda function is invoked to perform the quality checks. This AWS Lambda function extracts the rules from the metadata services repository.
- Data quality exception report is generated and saved in an S3 bucket.
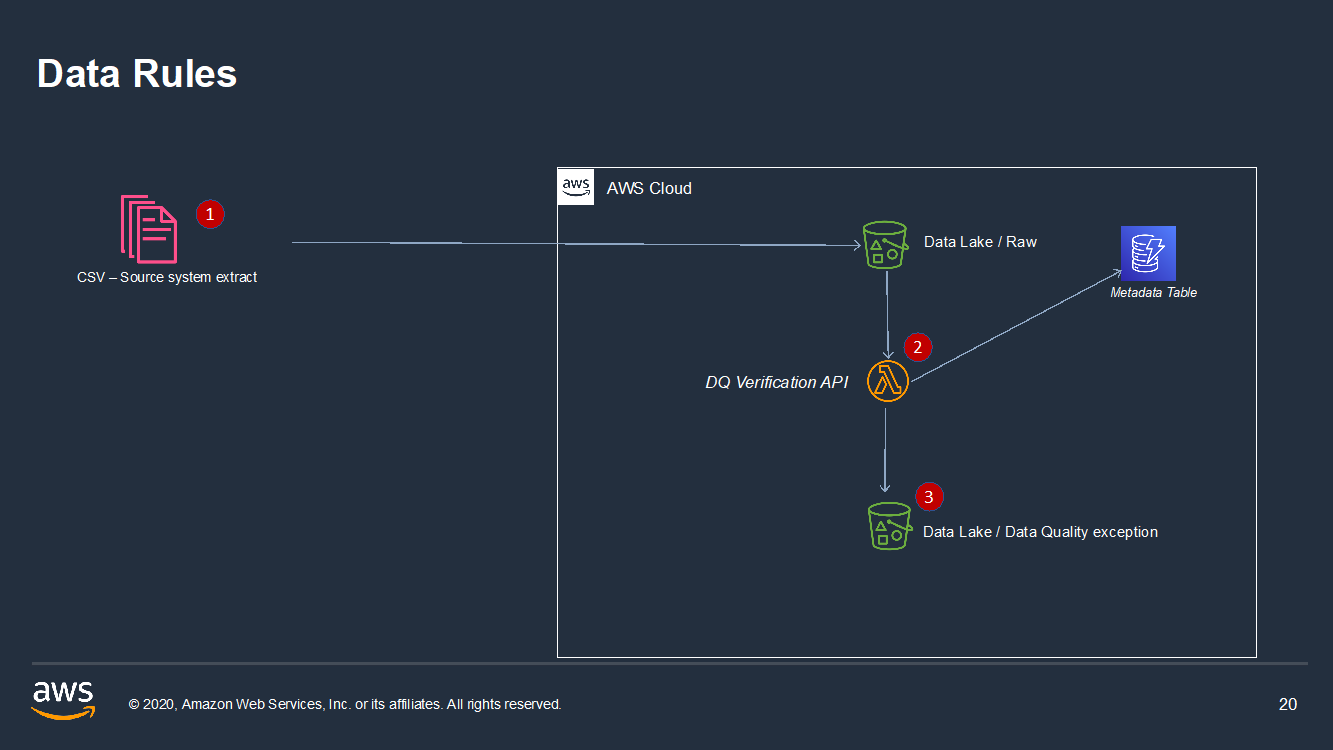 Figure 4
Figure 4
Data Distribution and Remediation
- The result of the data quality exception report is deposited to an S3 bucket.
- The “DQ distribution and Remediation” AWS Lambda function is invoked and references the metadata table to extract contact information on the quality report.
- Additional metadata is added and “in progress” report is placed on an S3 bucket.
- Amazon SNS is used to send notification to data office, the data owner, and the data steward. In addition, this step can include a call to the external tracking system. For example, Jira REST APIs can be used to interact with Jira server to register the data quality ticket.
- The data steward can use Amazon Athena to access and query the quality report. Data steward can slice and dice the data based on preference or priority.

Data Monitoring
- Historical information is kept on this S3 bucket
- Remediation information such as data owner, data steward, and time of report generation and assignment is captured in DynamoDB
- In progress report is kept on this S3 bucket
- Using the information outlined previously, progress can be visualized by creation of a dashboard using Amazon QuickSight
- Progress dashboard can contain information such as month over month data quality progress, assignment by line of business, or scoring information

In addition to business-oriented quality checks stated in the example, technology-oriented architectural components can be introduced to identify anomalies on the data engineering side.
File level verification is an important part of data lake quality control. It can prevent inaccurate or duplicated files from being fed and consumed.
We often have an understanding of how much change we expect in certain metrics of our file. A simple anomaly detection component can regularly store file level metrics in the DynamoDB database. Once historical data is captured, we can run anomaly checks that compare the current value of the metric to its values in the past and allow us to detect anomalous changes.
For example, the data engineering team can compute the size of a dataset every day to ensure that it does not change drastically: the number of rows on a given day should not be more than double of what we have seen on the day before.
Conclusion
In this post, we defined a data quality framework to encompass three components: data (end-to-end data quality lifecycle), people (responsibility model), and technology. All three components need to work together to drive better quality data. When designing a data quality framework on AWS, take into consideration a design that supports full transparency and self-service architecture. Data will never get to a final state of accuracy. That is not a practical goal, or an achievable one. However, data quality can be rearchitected on the cloud to provide transparent quality metrics to its consumers, and bring harmony and order to a subject that can easily get chaotic and time consuming.