AWS for Industries
How TripleLift optimized real-time bidding with custom load balancing, Spot, and Graviton
TripleLift is a digital advertising company reinventing ad placements at the intersection of creative, media, and data. Its marketplace serves the world’s leading brands, publishers, streaming companies, and demand-side platforms, propelling TripleLift to execute over 7 trillion ad transactions monthly through their real-time bidding (RTB) service. Customers choose TripleLift because of its addressable offerings—from native to online video to connected television—and supportive experts dedicated to maximizing partner performance.
This journey started more than 4 years ago and, like many optimizations, is more akin to a marathon than a sprint. Working backward from a set of goals and issues, TripleLift has improved its efficiency and reduced the costs of its Ad Exchange using a combination of TripleLift engineering, AWS best practices, open-source software, and service improvements.
The Ad Exchange service was built on the AWS Cloud and has evolved over the last 10 years. The digital advertising market is highly competitive, so the cost of running the service is constantly under scrutiny. Maintaining margins by reducing waste provides high leverage, particularly by focusing on two of the largest non-differentiated expenses: Data transfer out (DTO) and compute (using Amazon Elastic Computer Cloud (Amazon EC2)). This blog post will focus on the latter.
Initial optimizations
The original service was built using Amazon EC2 on-demand compute and the Application Load Balancer (ALB). It had a CPU scaling target, predictive scaling, and used a single instance type (c5.9xlarge). The following diagram depicts this initial setup at the AWS infrastructure level distributing traffic across Availability Zones.
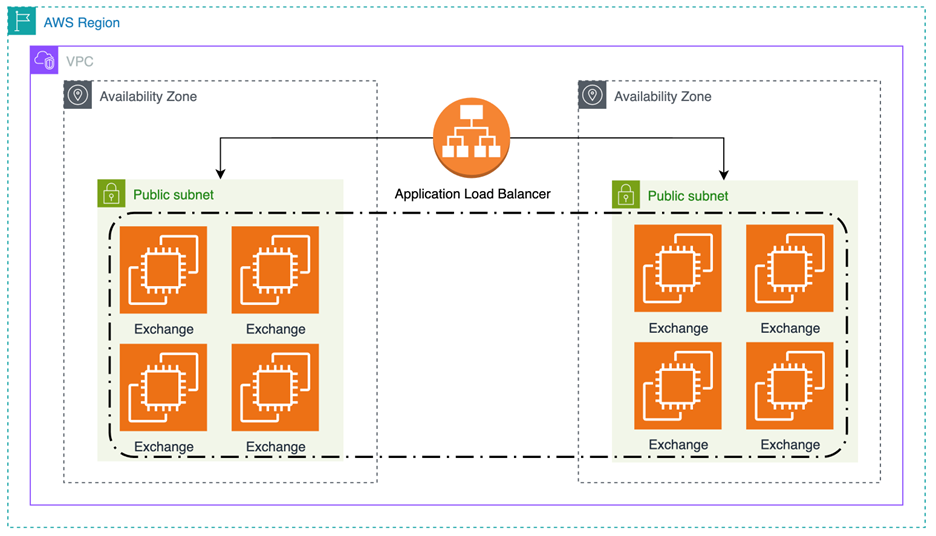
Figure 1: Exchange architecture using Application Load Balancer
This first iteration also utilized an equal traffic split across exchange instances. The following simplified traffic flow diagram illustrates how this worked in practice and recaps the main characteristics of the solution.
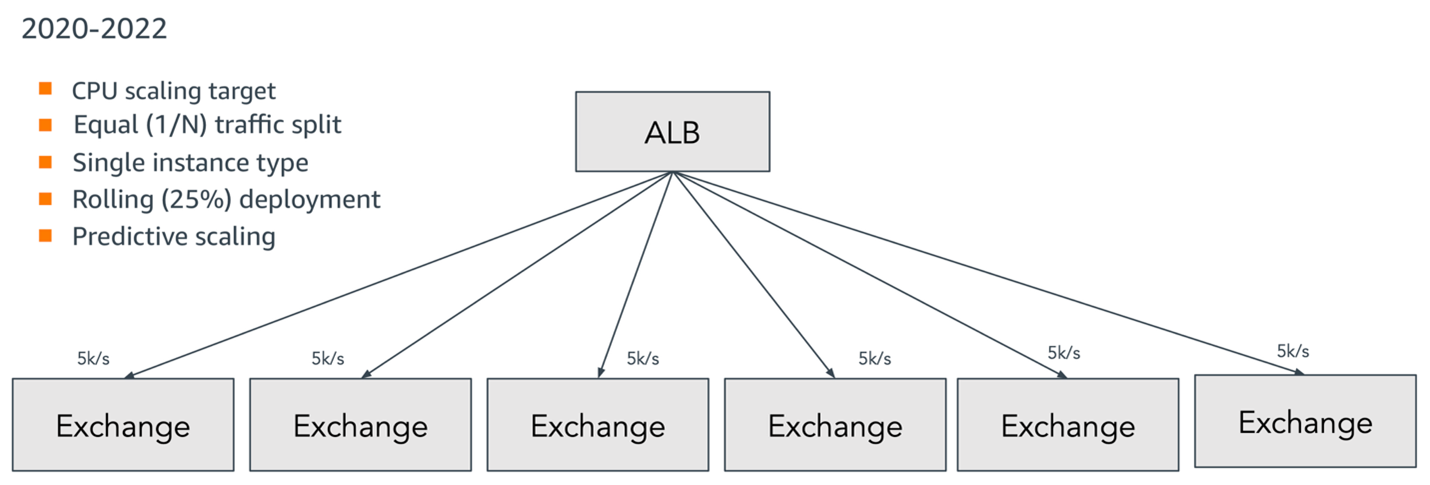
Figure 2: Original architecture using Application Load Balancer
The first and most straightforward optimization was to move from on-demand pricing to savings plans and reserved instances. This change greatly reduced costs for the steady-state workload but couldn’t be used for the spikey parts of the workload.
The next optimization was adopting Amazon EC2 Spot instances. The Exchange servers were modified to be stateless to accommodate the interruptible nature of Spot. You can run fault-tolerant workloads for up to 90% less than on-demand pricing. This optimization worked well with the spikey parts of the workload. Apart from using identical Spot instances, the architecture was largely the same as depicted in the following diagram.
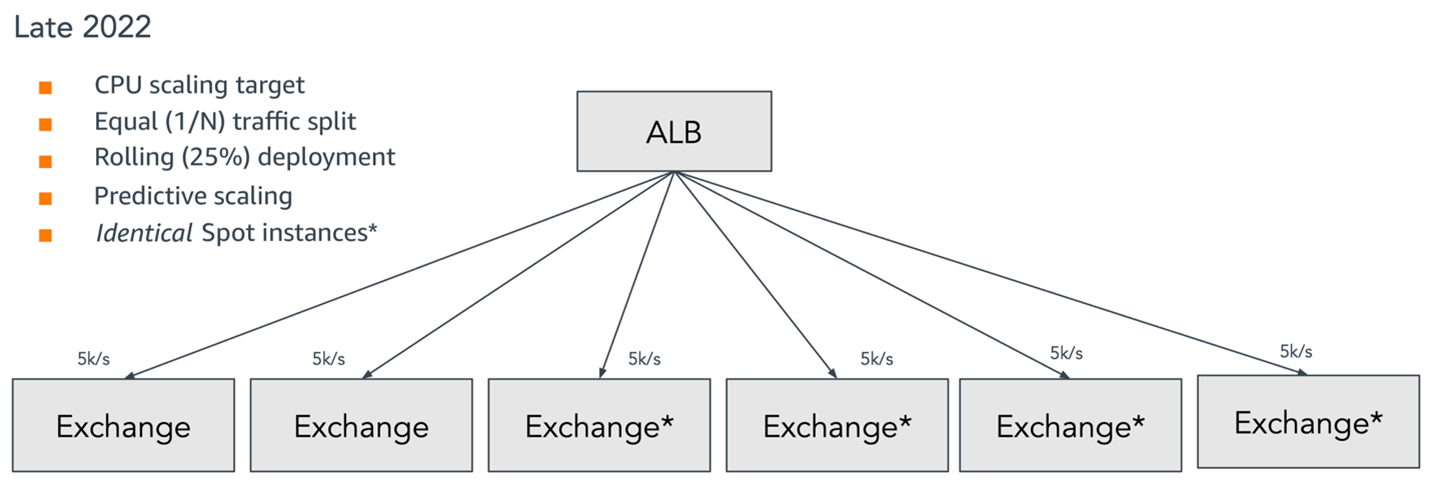
Figure 3: Architecture using Application Load Balancer with Spot
While Spot provided a significant cost savings, Spot availability is based on unused EC2 capacity in the AWS Cloud. In addition, the application design favored the latest generation of compute-optimized instances (C type), which weren’t always available as Spot. Therefore, we manually maintained a list of acceptable instance types based on empirical testing. This was acceptable, but cumbersome.
We then incorporated attribute-based instance type selection for auto-scaling groups. It allowed for the creation of a server profile that includes attributes such as vCPU, memory, storage, burstable, IncludeTypes, ExcludeTypes, and many more. This instance selection method has the benefit of automatically including new instance types as they’re released, giving the system more flexibility. This is coupled with the price capacity optimized allocation strategy of Spot, which makes Spot instance allocation decisions based on both the price and the capacity availability of Spot instances.
As part of the addition of Spot, TripleLift was able to adapt its Java code to also work on Graviton with minimal changes. Specifically, any components using native Java code (Java Native Interface) needed to be checked for compatibility with the ARM architecture. Flame chart analysis was also conducted to ensure no architecture-specific performance regressions.
The Exchange architecture had evolved to use Amazon EC2 on-demand and Spot with the Application Load Balancer (ALB). The scaling target was now queries per second (QPS) with an equal traffic split, such that the smallest instances would run at a desired CPU utilization. Predictive scaling, multiple instance types, and multiple architectures were also enabled.
Challenges with Spot pools and HAProxy agent iteration
This seemed like it might be the end—financial and architectural optimizations had been applied and best practices had been followed. The system ran well, but now a new issue arose.
To allocate as many Spot instances as possible, the instance attributes targeted a minimum number of vCPUs and memory footprint. This meant that the eventual pool could contain instances of the minimum size and instances that could be twice as large or larger. TripleLift began to notice that as the instance pool became more heterogeneous, the utilization of the larger servers was going down, resulting in unused CPU cycles. The following diagram highlights this underutilization in greater detail and its impacts on the architecture.
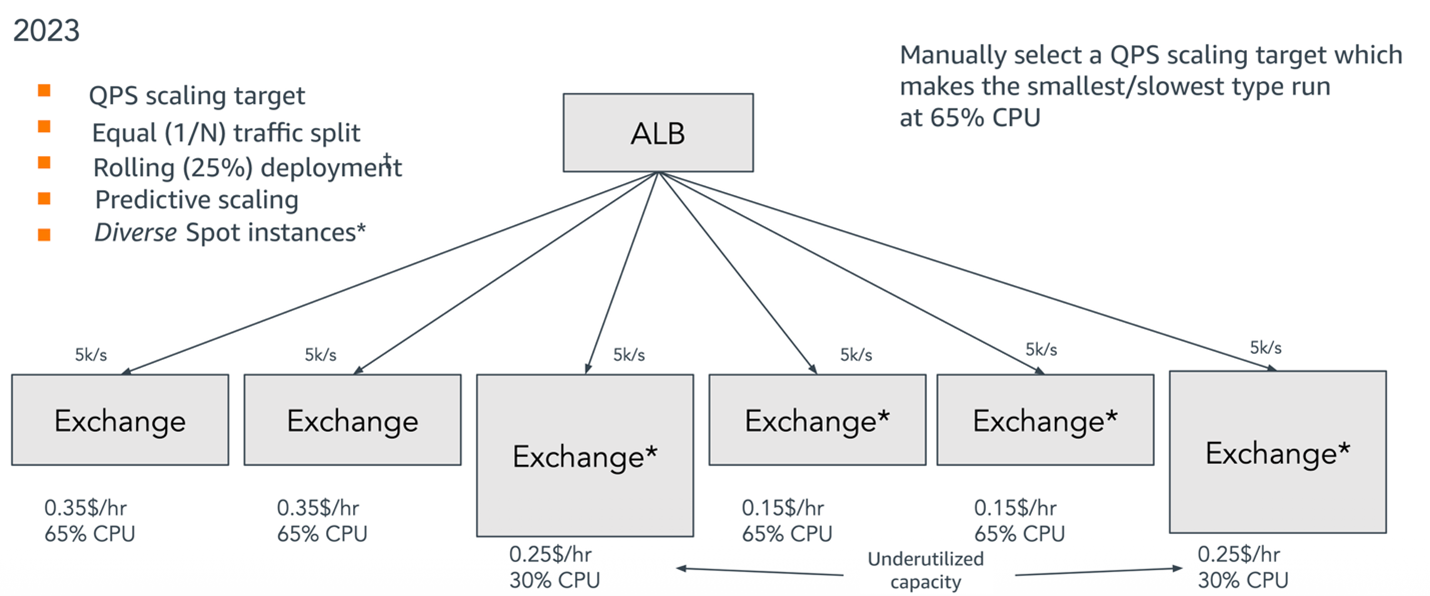
Figure 4: Architecture using Application Load Balancer with a Spot pool
This led to another round of optimization by improving compute utilization, cost optimization, and reducing our carbon footprint. Why was this happening? The auto scaling groups were using target tracking scaling, but that number is based on an average CPU utilization. The smaller servers were hitting the CPU targets, while larger servers were underutilized.
A success metric and optimization target was the spread (or max-min) of CPU across different-sized instances in the cluster. If that could be minimized by sending more traffic to larger instances and less traffic to smaller instances, the CPU utilization across the cluster would theoretically be fully and ideally saturated.
The next effort was to create a capacity-aware load balancer using HAProxy and to add a HAProxy agent (originally written in Golang) to each server. The agent reports utilization, and HAProxy, acting as the load balancer, can direct different amounts of traffic to each server based on its utilization. Consul serves as the service discovery layer of this system by automatically registering and deregistering Exchange servers as they spin up or terminate. The ensemble of HAProxy instances was fronted by a Network Load Balancer (NLB) to provide Layer 4 load balancing and SSL termination. The following architecture diagram illustrates how these components work together at an infrastructure level.
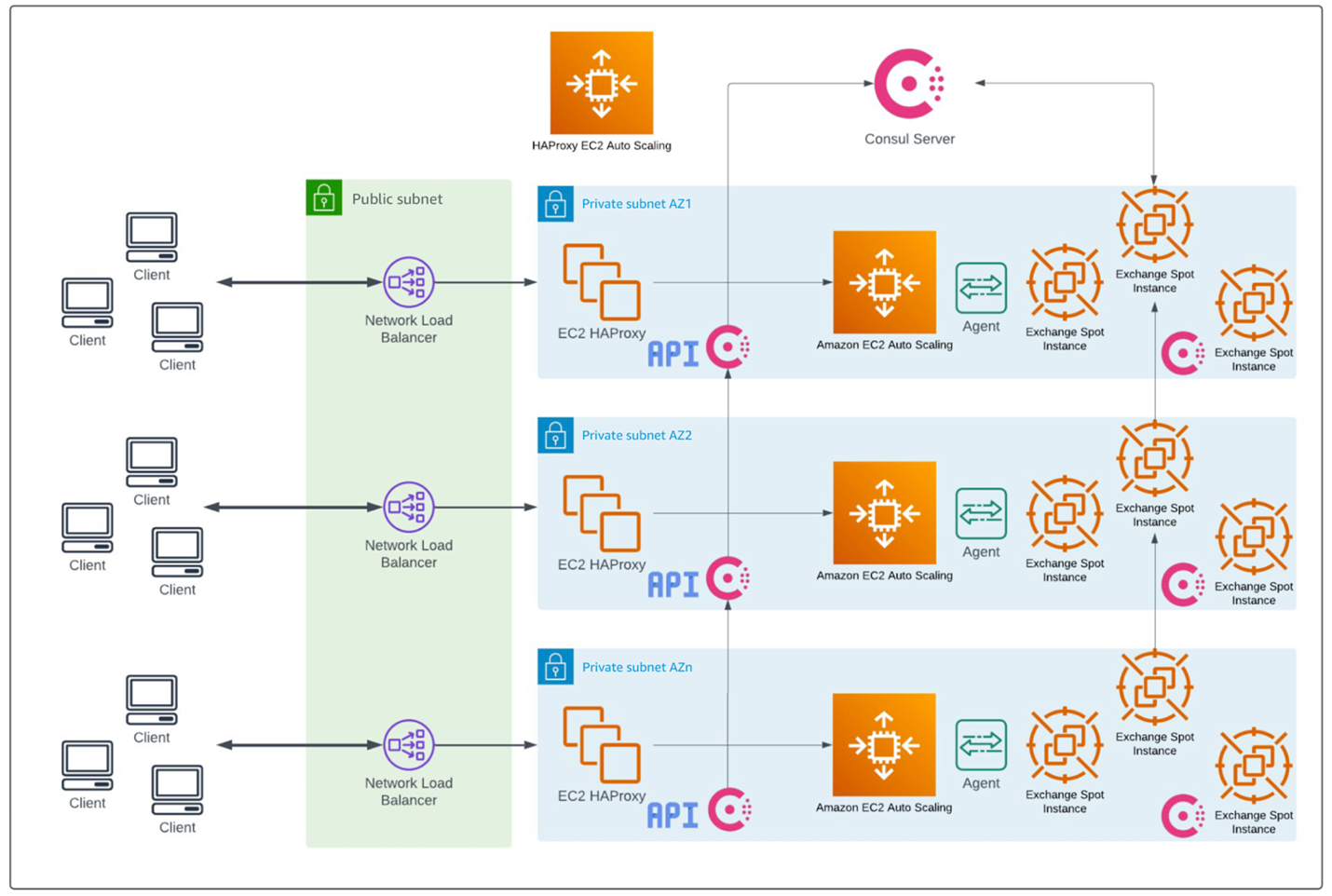
Figure 5: Architecture using Network Load Balancer with HAProxy agents
The original traffic allocation methodology used a weighted system, based on the CPU architecture, the manufacturer, and the speed of the backend servers. The fastest architecture was designated as the benchmark and the others were a relative percentage from it. While this made some improvement, it caused unwanted side work trying to perfect the relative calculations; for example, having to layer in the differences in clock speed and constantly updating for new EC2 instance types. Additionally, there were still wasted CPU cycles because the model didn’t prove effective in converging on the desired utilization target at scale.
A second version of the HAProxy agent was developed with a different working model, the proportional controller. This is a system where you set a goal, measure current state, and apply a proportional correction to achieve that goal. HAProxy Agent v2 was launched with a CPU goal (setpoint) of 65%. Unfortunately, there were a few issues:
- There were some race conditions in the CPU measurement process because of a naive Golang implementation.
- There was a failure scenario when the cluster’s average CPU exceeded the setpoint, and all nodes would continuously shed load until all instances reached their minimum traffic allocation. This would cause the cluster to be wholly unbalanced and give inaccurate average utilization values to the autoscaling group controller, which would then fail to scale up the cluster.
- The agents on each instance had no insight into the state of the cluster or other instances’ CPU utilization.
- The Network Load Balancer had inconsistent traffic allocation across availability zones, likely because of round-robin DNS caching of IP addresses and long-lived connections.
Finally, a third version of the HAProxy agent was developed. Sharding by Availability Zones was also added to reduce inter-AZ costs and allow for independent scaling of each Availability Zone based on the observed traffic patterns. The agent was rewritten in Java to be fully thread-safe. It still used proportional control, but a mathematical breakthrough was to use the average CPU of the observed Availability Zone as the setpoint. Each agent now published a custom Amazon CloudWatch metric and consumed the average CPU value across all of the instances in its own Availability Zone.
This resulted in a convergence because all instances were now pulling towards the same dynamic (and shared) setpoint. An over-saturated cluster would no longer continue shedding load like before; instead, all instances would try to get to the average CPU, even if that exceeded the autoscaling group’s target CPU. The autoscaling group’s job would be solely to add more instances to reach its own CPU target, but the convergence around the average CPU (or minimizing the CPU spread by modulating the traffic to each instance) was the collective job of the agents. A spreadsheet simulation was run and then a real deployment to show that the min-max CPU range was less than 5% and had basically converged. The following graph illustrates how this convergence manifested at a metric level.
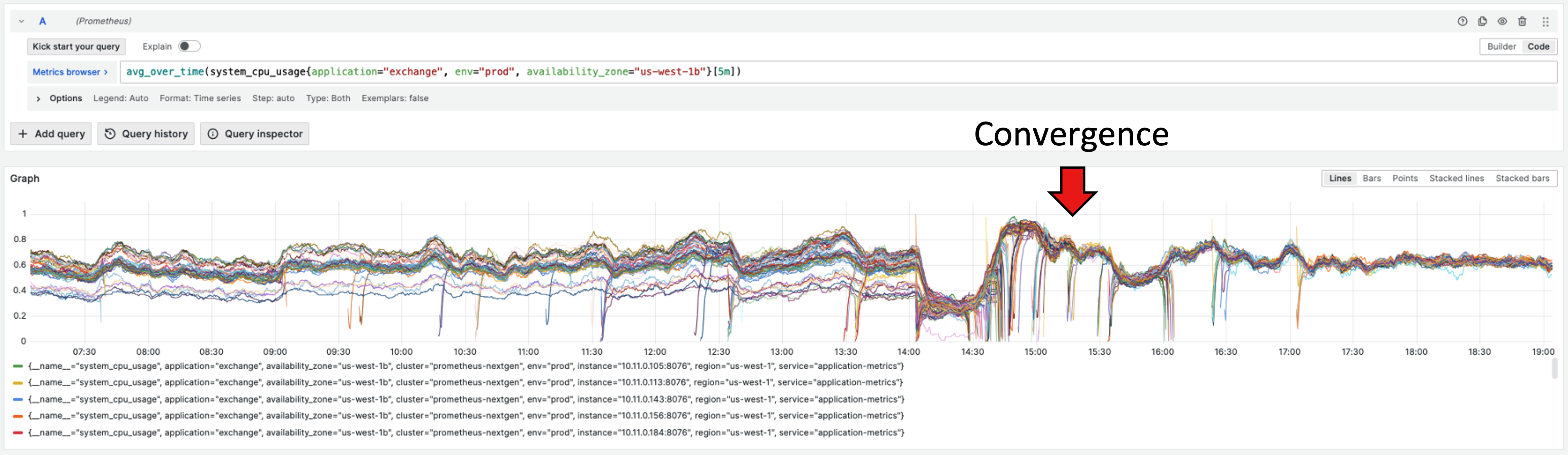
Figure 6: CPU utilization convergence
Observing the rate of requests presented an opposite pattern. The even traffic split gave way to dynamic behavior in which slower instances got less requests per second, while faster instances got more. The following graph illustrates this behavior at the monitoring level.
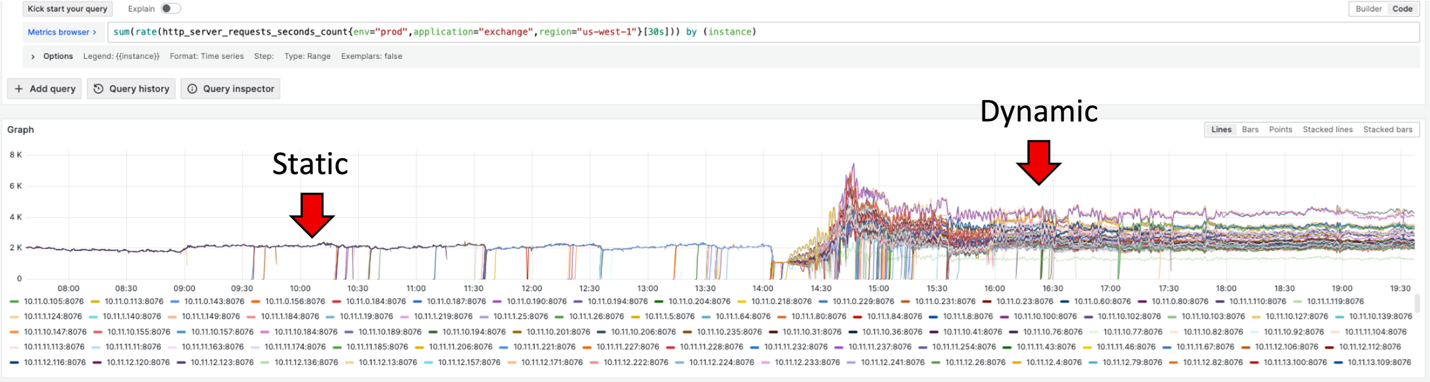
Figure 7: Requests per second – static to dynamic
The final architecture
With this final architecture, cost savings are approximately 23–40% monthly. In APAC, 30% fewer instances were being used; in the EU, 40% fewer instances; and in the US, 10% fewer instances. At a conservative dollar value, these numbers equate to more than $2M in yearly savings both from improved Amazon EC2 compute usage and lower load balancer capacity units (LCU) pricing for NLBs (25% less than ALBs). The following diagram shows how these optimizations come together in the final architecture.
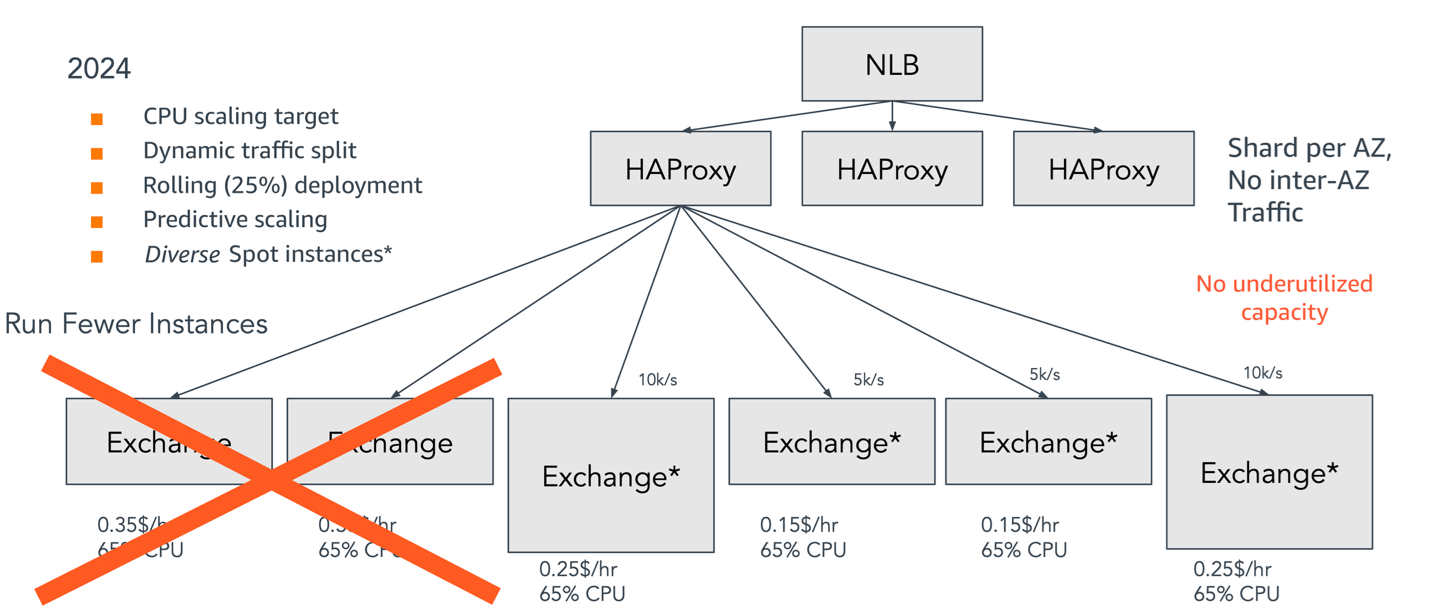
Figure 8: Architecture using Network Load Balancer and HAProxy
The journey isn’t over. There are more ideas for optimization, such as lowering maximum Spot pricing, scaling CPU core count, and implementing upgrades to support HTTP/2 on the backend servers. Other items include supporting better performance through connection multiplexing and header compression (binary format) and HTTP/3 on the frontend, in addition to overall CPU and memory tuning of the Ad Exchange process. Additionally, with this new architecture, TripleLift can onboard new partners by connecting them directly to HAProxy nodes through the AWS RTB Fabric service or through an AWS PrivateLink connection to the Ad Exchange NLB. By bypassing the public internet in favor of the AWS private network, these integration paths reduce latency and overhead, providing a faster, more cost-effective experience for the entire ecosystem.
Conclusion
Through a 4-year optimization journey, TripleLift transformed its Ad Exchange service by using Spot instances, Graviton processors, and a custom HAProxy agent to implement proportional control that dynamically balances traffic based average CPU utilization in each Availability Zone. This architectural evolution delivered remarkable results, exceeding cost savings projections and achieving more efficient CPU utilization than in previous iterations. With this new approach, TripleLift is well positioned to support future growth and better interoperability with partners on the AWS Cloud.