AWS for Industries
Implement Zero-Training Visual Defect Detection in Manufacturing with Amazon Nova Pro
For most manufacturers today, quality control of manufactured products often relies on workers manually visually inspecting the product(s), introducing inconsistency and increasing labor costs. Automated machine learning (ML) and computer vision (CV) solutions require extensive training data as well as continuous fine-tuning, which creates adoption barriers especially for small and medium-sized manufacturers.
This blog post shows how manufacturers use Amazon Nova Pro, a multimodal large language model (LLM) to analyze product images to identify manufacturing defects instantly, making advanced AI inspection accessible to manufacturers of all sizes.
Zero-Training Visual Defect Detection
The key advantage of using an LLM such as Amazon Nova Pro over a traditional ML model is that it does not require building training datasets, labelling, and training machine learning models to detect defects. Additionally, this approach is flexible: CV approaches either require vast data sets or retraining when there are small variations of the product or the surrounding setup, such as different camera models or lighting variances. The LLM-based approach copes with such changes without any modifications or requires a simple adaptation of the input prompt to the LLM. This makes the use of LLMs more viable for production uses, including products that have significant variations or frequent changes in the production set-up.
The integration of this solution into different environments is simple and flexible. It does not matter whether the capturing of images occurs in a browser application or on an industrial camera, all images are forwarded to an API using Amazon API Gateway. An AWS Lambda function then forwards the images to Amazon Nova Pro on Amazon Bedrock.
The LLM identifies missing components, surface defects, misalignments, scratches, and cracks without specialized training – a capability previously unattainable with a traditional ML model. As we demonstrate, it is even possible to classify different types of defects without any training data.
Architecture Overview
The architecture of the visual defect detection system prioritizes simplicity, performance, and zero-training operation. As shown in Figure 1, we follow a serverless approach that allows rapid deployment in a manufacturing environment without specialized ML expertise. The left-hand side of the diagram is the Image Capture Layer and as this depends on the production setup, we have illustrated two different variants below to showcase the flexibility of the approach. Our GitHub repository contains a browser application which is usable on any computer with a browser and a camera. In manufacturing environments, this part is easily replaced with any other image capture process or hardware cameras that do not require manual intervention for image capturing. For instance, AWS IoT Greengrass is used to capture images and then send them to Amazon Bedrock.
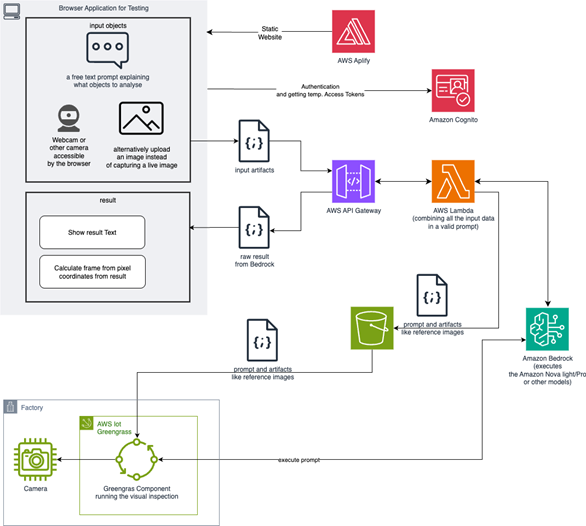
Figure 1: Architecture illustration with image-capture layer in a browser application
In the following section we outline each component with step-by-step explanation of the architecture.
Image Capture Layer
The process begins when a motion detection camera mounted above the production line detects movement. This trigger-based approach conserves processing resources by capturing images only when products are present. The camera captures high-resolution images and sends them over the local network for processing.
The motion detection parameters are adjustable based on your production line speed and product characteristics. For faster production lines, the parameters are optimizable for rapid capture while maintaining image quality sufficient for defect detection.
Serverless Processing Layer
Once an image is captured, it’s sent to the AWS serverless processing pipeline:
- An AWS Lambda function receives the image and performs initial preprocessing, including resizing, normalization, and metadata extraction. This function runs on-demand, eliminating the need for continuously running servers.
- The preprocessing step optimizes the image for analysis while preserving essential visual information required for defect detection. It also extracts metadata such as timestamp, production batch number, and product ID when available.
- Amazon API Gateway securely manages the API requests between system components, handling authentication, throttling, and ensuring communication integrity throughout the pipeline.
AI Analysis Layer
The preprocessed image is then passed via Amazon Bedrock to Amazon Nova Pro, the core intelligence behind the system:
- Amazon Nova Pro analyzes the image without requiring any product-specific training. It understands visual context through its pre-trained capabilities.
- The model examines the image for multiple defect types simultaneously, including missing components, misalignments, surface defects, scratches, and cracks.
- For each detected anomaly, Amazon Nova Pro generates a confidence score and precise location information within the image.
- The model’s output includes both a structured analysis (defect type, location, confidence) and natural language description of identified issues. This makes the results both machine-actionable and human-interpretable.
Prompt engineering is key for using an LLM for quality detection. Therefore, the remainder of this post will focus on this AI Analysis Layer and how to properly prompt the LLM for defect detection for various products.
Prompt Engineering for Defect Detection
The LLM-based defect detection approach uses structured natural language prompts to instruct the model on defect detection criteria. The system prompt defines what constitutes a defect, and the instruction/user prompt defines how the model will respond including formatting instructions. An example of a system prompt is as follows:
“Compare the current image with the reference image(s) and highlight any visual differences. Mark as qc=NOK if differences exist; otherwise, mark as qc=OK. Be very strict with the differences, give me all the differences. Check for any missing or visual differences. Scratches and dents are also important. Search for any aesthetical problem, any barcode missing, if the objects have some missing labels, or anything aesthetically different, blurry text or logos. Any material differences, scratches on surface, color difference between reference and current image constitute a defect.”
As we demonstrate later, this definition of a defect is easily adapted to different scenarios so that varying definitions of what determines a defect is accommodated without any retraining or data labeling. The instruction/user prompt focuses on the output format – in this case JSON – so that it is possible to automate the processing of these results. An example of this instruction prompt is as follows:
“Provide the JSON with the written description in ‘text’ and the list of objects in ‘objects’. This list must include: name, color, qc, reason, bounding_box of the defect (x_min, y_min, x_max, y_max). Clean JSON only — no markdown, no extra characters. If you describe a defect, include its bounding box. Do not group bounding boxes or include any from the reference image. Be strict on the JSON based on the example, keep the same names for the objects because I am parsing those later. Make bounding boxes for all defects.”
Note that we have deliberately excluded more advanced prompting techniques, such as chain of thought or multi-shot prompting, or more advanced generative AI techniques, such as agents or retrieval-augmented generation (RAG), to keep this approach as lightweight and easy-to-deploy as possible.
Building and Sending the Request to Amazon Bedrock
The system constructs a request to Amazon Bedrock that includes both the reference and quality control (QC) images, along with the structured system and instruction prompts. This request is executed as a Lambda function for every incoming image from the API gateway. The function uses the reference image, incoming QC images, and the prompts by constructing it into a message that conforms to the format defined in Amazon Bedrock.

Figure 2: Example of a reference image of a blue board with a scratch in the middle.
The result from Amazon Bedrock is provided in JSON, though other formats are possible as well if required by systems that process these results automatically. In our case, the responses are parsed using standard JSON libraries and are directly forwarded to other systems in the quality control chain to automate the handling of defects. Using the prompt outlined in the previous section, we receive this response as JSON from the LLM:
{
'text': 'The object is a blue cutting board. There is a scratch on the surface of the board.',
'objects': [{
'name': 'scratch',
'color': 'white',
'qc': 'NOK',
'reason': 'scratch on surface',
'bounding_box': {
'x_min': 280,
'y_min': 400,
'x_max': 530,
'y_max': 450
}
}]
}
Benchmarking
Traditional CV systems regularly achieve more than 90% accuracy in corresponding benchmarks or tests after training specialized models with extensive amounts of labelled data. A benchmark that is often used in this context is MVTec AD: An anomaly detection (AD) benchmark of approximately 5000 high-resolution images of different products or objects ranging from nuts to pills and toothbrushes. We use the toothbrush dataset: this set contains 42 QC images – 30 defective and 12 good toothbrushes. Defects range from malformed or missing bristles to production errors such as metal objects in the toothbrush.
Using the above prompts, the results for these benchmark images are as follows:
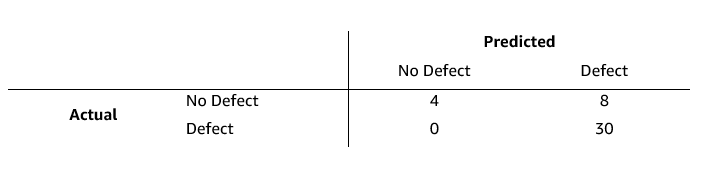
Figure 3: Results table for benchmark images for toothbrush example 1
Metrics:
-
Accuracy: 81%
-
Precision: 78.9%
-
Recall: 100%
-
Specificity: 33%
-
F1 Score: 0.882
-
Balanced Accuracy: 0.667
This is clearly below the performance that CV systems achieve after being trained on labelled images in this benchmark. Particularly the specificity of the approach is an issue. A deeper inspection of the results shows that the model detects many toothbrushes as “defective” because they have colors or handles in different colors. In such cases, the text contained in the Amazon Bedrock response JSON said:
The verification image shows a toothbrush with red bristles instead of the blue bristles seen in the reference images.
We demonstrate in the next section how to address this and improve the accuracy of the results.
Optimizing Accuracy
As noted above, most of the errors made by the approach above show that differences in color were detected as defects. Reviewing the prompt shows that it does not mention the color of the product and it also is not specifically tailored to toothbrushes. This section shows how flexible the approach is and how easy it is to improve accuracy by adapting the prompt. To implement this, we simply change the system prompt to the following:
“You are a quality control inspector analyzing toothbrush images. Compare the verification image against the reference image(s) to identify any defects or quality issues.
IMPORTANT: Color variations in toothbrush components (such as bristle color, handle color, or any decorative elements) are NOT considered defects. Different colored bristles (e.g., red vs blue) are acceptable variations and should be ignored.
Focus on actual defects such as:
- Missing or damaged bristles
- Structural damage to the handle
- Contamination or foreign objects
- Manufacturing defects (excluding color)
- Deformation or misshaping
- Missing components (excluding color differences)
Provide detailed analysis in JSON format.”
This prompt has a few notable differences to the original system prompt used. It is specifically tailored to toothbrushes and lists potential defects but also mentions that color differences are not defects. The results with this prompt are as follows:
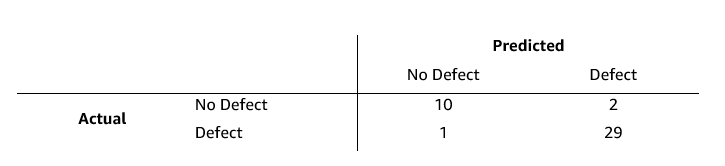
Figure 4: Results table for benchmark images for toothbrush example 2
Metrics:
-
Accuracy: 93%
-
Precision: 94%
-
Recall: 97%
-
Specificity: 83%
-
F1 Score: 0.951
-
Balanced Accuracy: 0.900
In summary, by changing a few lines in the prompt – in plain English – we were able to get a significant improvement in all accuracy related metrics. The results are in line with specialized CV models. While this result is better than before, there are opportunities for further improvement ranging from the use of advanced prompting approaches to providing more reference pictures for each comparison. Nevertheless, this demonstrates the versatility of the solution. In a traditional, training-based image recognition approach, this change in requirements requires training another model and potentially a new data labeling process. Such an implementation of a new model easily takes weeks, while the above change in the prompt does not require specialized knowledge or data and therefore is implemented in minutes.
Processing Speed
While executing the above benchmark, we measured the time it took to complete each request to Amazon Bedrock and return the result as described above. The average “round-trip” time per image is approximately 3.3 seconds.
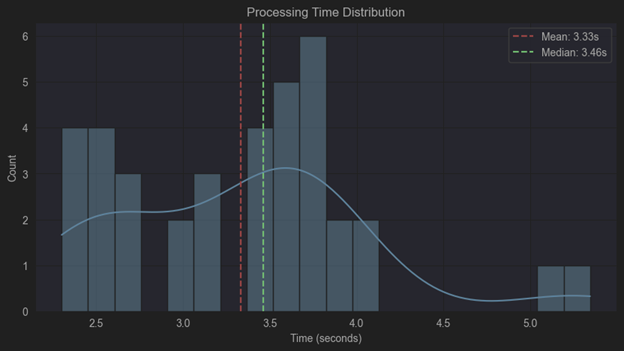
Figure 5: Processing Time Distribution per Image Analysis
The solution illustrated in this blog post handles simple quality inspection applications that have lower throughput rates and are not time sensitive. If your application is higher scale, this solution is adaptable using a variety of measures that go beyond the scope of this blog post such as:
- Parallelization: Since Amazon Bedrock manages the underlying infrastructure needed to run the Amazon Nova Pro LLM, we can set up a process where multiple requests are sent to Bedrock simultaneously to improve processing speed. This allows a quality control system to handle multiple product images in parallel, even when cameras capture images faster than the 3.3-second average processing time per image.
- Model Distillation: Model Distillation: For high-volume production lines processing hundreds or thousands of products per hour, Amazon Bedrock offers model distillation which allows the use of a significantly smaller, faster model for this task with almost no reduction in accuracy, enabling faster response times critical for real-time quality control.
- Prompt caching: In manufacturing environments where the same reference images and system prompts are used repeatedly across thousands of quality checks, prompt caching in Amazon Bedrock reduces processing times and costs by storing common prompt elements, eliminating the need to reprocess identical reference data for each inspection.
Conclusion
Zero-training visual defect detection with Amazon Nova Pro represents a shift in manufacturing quality control. By eliminating the need for labeled datasets and custom model training, this solution makes advanced AI inspection accessible to manufacturers of all sizes. The implementation we demonstrate requires minimal technical setup while delivering enterprise-grade inspection capabilities.
The companion Jupyter notebook offers a starting point for your own implementation. Adapt the prompts, adjust the visualization, and integrate the solution with your existing quality control workflow.
Contact an AWS Representative to learn more about how AWS can help accelerate your manufacturing digital transformation.