AWS for Industries
Measuring the accuracy of rule or ML-based matching in AWS Entity Resolution
How do you know that an entity matching ruleset or model is actually accurate enough? Whether evaluating multiple identity providers or building your own matching rules, companies need to establish clear, accuracy level criteria they want to achieve, as well as the framework to measure and compare different approaches objectively. Companies who do not measure their identity processes objectively can stretch out implementation periods by weeks or even months—repeat steps or instituting costly changes in methodology for measuring accuracy.
We will explain and demonstrate an approach for testing the accuracy of a model using our own machine learning (ML)-algorithm, which is an existing feature of Amazon Web Services (AWS) Entity Resolution. AWS Entity Resolution helps you match, link, and enhance related customer, product, business, or healthcare records stored across multiple applications, channels, and data stores. We will also provide everything needed to reproduce our results using your own data or a synthetic open-sourced data set.
Using this framework will provide a way for you to quickly evaluate the accuracy of your matching. This process will work for any entity matching process that you are attempting to benchmark.
Why is accuracy important?
First, what do we mean by accuracy? Accuracy, for our discussion, refers to how often a service can correctly identify records that belong to the same person without matching records that do not. This means that a perfectly accurate solution would match every duplicate record belonging to the same person without missing any fragments or matching any extra data to a record that belongs to someone else.
This is an intuitive concept, but it is difficult to measure consistently. Many companies embark on projects to deduplicate and unify customer data without a consistent methodology and metric for measuring true negatives and true positives accurately. Many companies also lack trustworthy data sets of personal information that capture the complex edge cases which come up in customer data.
It is possible to reach an accuracy metric of 100% clean data, or with a small enough sample set. However, real world data and larger data volumes are not feasible to match with 100% accuracy because there are countless edge cases with genuine ambiguity. Therefore, companies must set a measurable threshold for accuracy so that they do not end up in an endless cycle implementation chasing an impossible goal.
Today, enterprises receive more data fragments than ever before. Every mobile app tap, online click, and authenticated session generates data that helps businesses understand consumer behavior, personalize experiences, and optimize operations. Companies that are able to bring together this data into a unified view of the customer can use those insights to offer better personalized experiences. They can also make more informed product, marketing, and sales decisions.
Companies focused on pulling more value from their data have a wide range of entity matching tools and services to choose from. However, companies often get stalled for months, or even years, evaluating and implementing a solution.
One of the first roadblocks is that they lack a robust and consistent framework to evaluate identity matching frameworks and approaches. How does a company know which identity matching methodology will drive the most value for their data? The stakes concerning accuracy are only getting higher. Customers expect more personalized experiences with the brands and enterprises they frequent. The benchmark for accuracy is also going to be different for companies based on their vertical and their use case.
In order for companies to trust that their identity resolution process addresses their specific needs, they must create a trusted benchmark of data that contains the edge cases they actually see in their production data, and they must define accuracy based on types of records they receive from any system that collects customer data.
Ground truth sets
The most widely accept method of evaluating the accuracy of a matching process is to compare the results of the process to a manually annotated ground truth set (also commonly referred to as a truth set). Ground truth data in AI refers to data that is known to be factual, representing the expected use case outcome for the system being modeled.
In this use case, a ground truth set is a small subset of pairs of records that a human being has manually reviewed and annotated if they should match or not. The ground truth set does not have to be large, but should be large enough to contain a representative set of use cases that occur frequently in the data.
However, since a ground truth set requires personally identifiable data (PII), companies should be sensitive about sharing or using them for proofs of concept. They should make certain that all needed security protocols are in place. Ground truth data can have better, reproducible results compared to other benchmarked data sets.
Challenges of measuring identity resolution accuracy
The value of a single view of the customer depends almost entirely on how closely that data reflects the real world it is trying to represent. Accuracy, however, can be a moving target if you look only at individual records. Companies must have a clear threshold for accuracy as they build rules or use an algorithm for identity matching or they will have an endless process of revisions and changes. These thresholds will vary from customer to customer.
For example, we can see how two companies in the same vertical can have to set different thresholds for accuracy based on the context of where they collect data. We will consider two different retailers, Companies A and B.
Company A is a brick-and-mortar grocery retailer that collects customer data from transaction events and loyalty programs. These transactions will have no data if cash is used, or will use credit card tokens that could be shared within a household or used by a business. Additionally, if they collect loyalty data through a card-based loyalty program, they may have cards with blank, incomplete data, or with lots of shared addresses and landline phone data associated to several different people. There is no incentive for customers to share accurate data since they can receive their loyalty benefits by presenting a physical card that might be new or shared.
Company A would need to test their matching on pairs of records which include incomplete name matching data, credit card tokens and a high proportion of shared data. Additionally, they will only be interested in household-level matching for grouping, since that is the most accurate resolution level possible for Company A based on how their customers share data.
Now contrast this to Company B, who is an online retailer that performs all of its transactions on its website. Nearly all of their customers authenticate with an email address, where they have a profile associated to their browsing behavior. Their customer will need to share accurate postal address, name, and email values in order to actually receive the goods they purchase. Individuals within the same household are more likely to make purchases under their own name and email address, even within the same household. This is because it is quicker for them to receive receipts and initiate returns through their personal account or email address.
Unlike Company A, the brick-and-mortar retailer, Company B can match users on an individual-level. They could insist on a higher portion of shared attributes before matching, since delivery addresses and phones may be shared. However, lots of other trustworthy data can distinguish between members of households or users with overlapping data.
Both retailers would receive the best results if they created their own ground truth set which reflected the scenarios present in their data and their own threshold for an acceptable match. This set should include test cases both for fragments of records that should be brought together (a true positive), as well as records that share many characteristics but need to be kept apart (a true negative). In order to be used for matching, these test cases should be annotated as a ground truth set to indicate the desired behavior—whether the records should match or not.
In the data science community, the most standard way to measure accuracy is a metric called the F1 Score. The F1 score is a metric that averages precision and recall, which are the two key aspects of model performance, against the ground truth.
In the context of an entity matching model, precision refers to how often a model can prevent a false positive match that would mistakenly bring together two records that are not matched in the ground truth. Recall in this context refers to how often a model can correctly bring together records that are grouped together in the ground truth. Therefore, a ground truth data set should have pairs of records that should be brought together, as well as those that do not belong together, but share some similarity (See Figure 1).
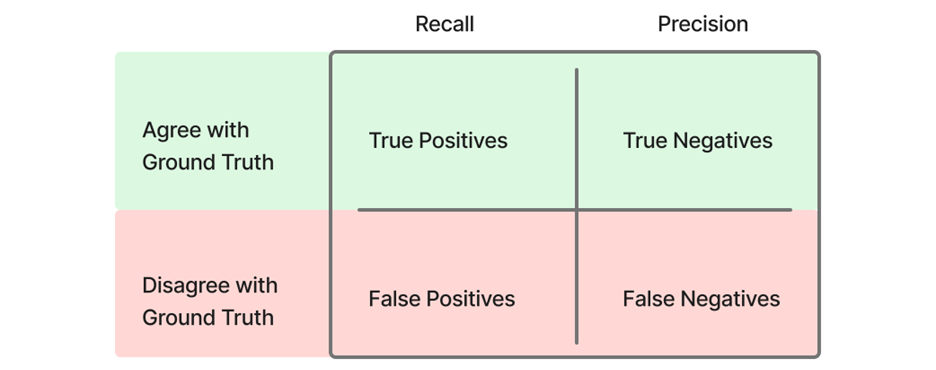 Figure 1 – Table defining recall and precision
Figure 1 – Table defining recall and precision
The F1 score is defined as the harmonic mean of precision and recall, calculated as:
F1 score = 2 × [(Precision × Recall) / (Precision + Recall)]
Precision is the ratio of true positives (correct matches) to the sum of true positives and false positives (incorrect matches). Recall is the ratio of true positives to the sum of true positives and false negatives (missed matches). The F1 score ranges from zero to one, with higher values indicating a better balance between precision and recall. This balance is crucial since different industries prioritize precision or recall differently. For instance, healthcare often aims to minimize false positives (favoring precision), while advertising focuses on maximizing true positives (favoring recall).
Data evaluation walkthrough
There are not many publicly available data sets customers can use to test accuracy. One frequently used dataset for these analyses is the Ohio Voter file. The Ohio Voter File is a well-known, publicly available, dataset for people matching. It is 105,000 records containing name, address, and birthdate from Ohio state voter information.
The Ohio Voter File is the most commonly used ground truth set for many entity matching solutions by developers because it contains real data. However, it has some shortcomings that limit its usefulness as a proxy for real customer data. It lacks phone number and email fields, it is free from frequent data hygiene issues such as unnormalized postal addresses and types, and records tend to be very complete.
In order to account for some of these more complex, lower data quality examples, the AWS Entity Resolution Data Science team developed and open-sourced a new panel of synthetic data. It more closely resembles these more challenging entity resolution scenarios and is called the BPID: A Benchmark for Personal Identity Deduplication. BPID is a significantly more challenging dataset that includes 20 thousand synthetic records with complex patterns across name, email, phone, address, and birthdate fields. BPID was published at Empirical Methods in Natural Language Processing (EMNLP) 2024, which is one of the leading Natural Language Processing conferences in the world.
The following example will demonstrate the steps to measure the accuracy of the ML-matching model that is a feature of AWS Entity Resolution. We will be using the open-sourced ground truth set from BPID.
Prerequisites
- An AWS account
- Basic understanding of data matching concepts
- Jupyter Notebook or similar environment for running analysis
- Familiarity with Python and data processing libraries
1. Download data
First, you will need to download the data to be used in your test. Download the BPID data set and unzip. We will use matching_dataset.jsonl for accuracy evaluation. Following is an example pair from the BPID dataset:
2. Preprocess test and ground truth data
Prepare two data sets from the test data—one for the input, and another as the ground truth set to measure accuracy after matching. You will need to transform matching_dataset.jsonl to the schema needed for the processor. In order to prepare this data for use in AWS Entity Resolution you must first read the data onto your local or virtual environment.
Next you will need to flatten and transform the input records so they can be loaded into the AWS Entity Resolution. The labels will be stored in a separate file as outlined in the following:
Now, you can run the following script to separate and prepare the labels in order to calculate the accuracy score:
Next, save the processed profiles and labels as json files using the following:
After running this pre-process, the profile data (BPID_matching_profiles_processed.jsonl) should look like the following:
The accompanying label file (BPID_matching_label.jsonl) should look like the following:
3. Run a matching workflow
Once the test data is transformed, run a matching workflow for the workflow you plan to evaluate.
The goal is to obtain matched results, from which you can positively or negatively match any two records in the input dataset belongs to the same person or not. This step will vary from service to service.
Finally, run an AWS Entity Resolution matching workflow. Following is an example of an output from AWS Entity Resolution:
InputSourceARN,ConfidenceLevel,addr1,addr2,addr3,addr4,addr5,dob,email1,email2,email3,fullname,phone1,phone2,phone3,profileid,RecordId,MatchID
arn:aws:glue:us-west-2: ***********:table/yefan-bpid-benchmark/input,0.75296247,cookson tx 75110,,,,,2003 7,,,,,26806124715,3236000026,,pair1622_1,pair1622_1,6d08ce607181460584e2436e66660b2300003566935683247
arn:aws:glue:us-west-2:***********:table/yefan-bpid-benchmark/input,0.75296247,cookson tx 75110,,,,,2003 07 10,yong123@business-domain.co.uk,,,yong stearns,6807159172,6806124715,,pair1622_0,pair1622_0,6d08ce607181460584e2436e66660b2300003566935683247
4. Calculate the F1 score
After obtaining the matched results, you can use the label information in the raw data and the matched results to calculate the F1 score metrics. Each pair in the dataset matching_dataset.jsonl has a label of match or no-match. For each pair, you will check in the matched result whether it aligns with the label. You then assign this pair to one of four categories:
- True Positive (TP): both label and matched result suggest a match
- False Positive (FP): label is “no-match” but matched result is match
- True Negative (TN): both label and matched result suggest a no-match
- False Negative (FN): label is “match” but matched result is no-match
After obtaining the count of these four types, you can calculate the following:
Precision = TP / (TP + FP)
Recall = TP / (TP + FN)
F1 score =2 × [(Precision × Recall) / (Precision + Recall)]
Run your own benchmarking test
You can reproduce these results by running the benchmarking process. The following outlines the steps and notebooks needed to run this process in AWS Entity Resolution for ML-based matching. The steps and data can also be repurposed to evaluate the accuracy of a rule-based matching workflow or a matching process from another provider. The BPID data does not contain real customer PII and therefore can be used to evaluate providers that use an underlying reference graph.
For teams looking to improve their identity resolution processes, we recommend:
- Downloading the BPID dataset for your own evaluations
- Exploring the AWS Entity Resolution ML-based matching capabilities
- Considering the F1 score as a key metric in your vendor assessment
Conclusion
It can be very challenging to measure the accuracy of rules or algorithms that a company uses to unify customer data. Most companies do not have an annotated ground truth set to benchmark against and may lack a consistent methodology for measurement.
We demonstrated how to conduct a comprehensive accuracy evaluation for identity resolution services using AWS Entity Resolution. We shared our benchmarking methodology, open-source datasets, and a step-by-step guide for readers to reproduce our accuracy assessment.
Contact an AWS Representative to know how we can help accelerate your business.