AWS for Industries
Multi-Agent Systems for Financial Services on Amazon EKS and AgentCore
When a client asks, “is my portfolio balanced?”, a financial advisor needs current valuations, a stress test against the client’s risk tolerance, and live market data to create a recommendation they can defend. Financial advisory teams solved this long ago by dividing the work: a portfolio manager values the book, a risk analyst stress-tests it, a market researcher brings the outside view, and an advisor writes the final answer. Multi-agent systems follow the same approach, with each agent responsible for one domain and an orchestrator coordinating the specialists into a final response. In this post, we show how to build that system on Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Bedrock, and Amazon Bedrock AgentCore, with authentication, tracing, cost control, and sandboxed code execution at every layer.
A similar pattern applies across the financial services industry (FSI). Retail banks want agents that reason over a customer’s ledger, fraud signals, and product catalog in parallel. Insurers want agents that coordinate underwriting, claims, and actuarial models. Capital markets want agents that combine positions, risk, and live quotes. Different domains, same structural requirement. Several narrow specialists, one orchestrator, and a lot of enterprise infrastructure around every hop.
That last part is the gap between an agent framework and a production agentic AI platform. Open-source frameworks handle orchestration, tool calling, and multi-turn reasoning well. The gap is everything beyond the core workflow: authentication between agents, authorization on tools, traces a compliance reviewer can follow, a single place to rate limit model spend, and a safe way to run code the model just wrote. Although these considerations may not apply for a proof-of-concept, they are a requirement for a production deployment.
What a production FSI multi-agent platform must do:
- Each agent must own a narrow domain with its own prompt, tools, and scoped permissions, so governance reviews happen per agent and not across one giant prompt.
- The architecture must authenticate every inter-agent call and every tool call and trace the entire request. When audit asks who asked which agent to do what, on whose behalf – that answer is already in the trace.
- LLM calls must route through a central gateway that handles rate limiting, response caching, model fallback (for example, Claude Sonnet falling back to Claude Haiku), and per-agent spend tracking.
- Foundation model inference must run inside your AWS account on Amazon Bedrock so that inference data does not leave the AWS account boundary.
- Any code the model generates (valuation math, simulations, transformations) must run in an isolated, ephemeral sandbox with no access to pod secrets, production data, or the cluster network.
- Agent lifecycle must be managed declaratively through version-controlled manifests, so that new specialist agents go through the same review, approval, and rollout process as any other workload on the cluster.
Architecture
In this post, we architected a layered platform that separates agent identity, tool access, LLM routing, and secure code execution into independent components. Each layer is deployable, observable, and governable on its own. The platform runs on Amazon EKS Auto Mode, which manages compute autoscaling, networking, storage, and security of the Amazon EKS data plane. That leaves cluster provisioning to Terraform and the rest to GitOps.
This post focuses on how Amazon EKS, Amazon Bedrock, and Amazon Bedrock AgentCore fit together to support a multi-agent system for financial services. The reference implementation has four agents written with the Strands Agents SDK, a Model Context Protocol (MCP) tools server, an OpenAI-compatible LLM gateway (LiteLLM), and a policy-aware agent gateway that fronts the whole system.
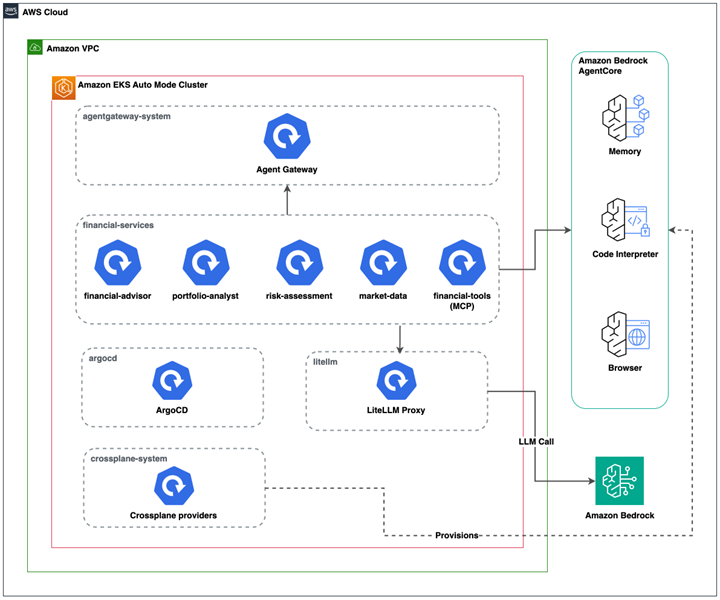
Figure 1. Multi-agent platform on Amazon EKS Auto Mode with Amazon Bedrock and Amazon Bedrock AgentCore.
Key components
Amazon EKS Auto Mode
Runs every workload in the platform (agents, tools, gateways, tracing) as plain Kubernetes Deployments. We get namespaces, Role Based Access Control (RBAC), Horizontal Pod Autoscaler (HPA), GitOps, and Pod Identity without managing a node group or a Container Network Interface (CNI) addon. AWS handles compute autoscaling, security patching, and infrastructure operations, so you focus on agent logic.
Amazon Bedrock
Handles all foundation model inference. Claude Sonnet 4.6 is the primary model; Claude Haiku 4.5 is the fallback. Requests do not leave the AWS account boundary, and Amazon Bedrock handles the undifferentiated heavy lifting of managing model infrastructure.
Amazon Bedrock AgentCore
Provides three managed capabilities that agents can use:
- AgentCore Memory: keeps cross-session client profile for the orchestrator (risk tolerance, goals, prior recommendations).
- AgentCore Code Interpreter: runs model-generated Python code inside an isolated, ephemeral sandbox, providing the execution boundary security reviewers require.
- AgentCore Browser: gives the market data agent a managed headless browser for live quotes so we do not have to ship Chromium into every pod.
Agent Gateway (agentgateway.dev)
A policy-aware proxy that sits in front of every agent and the MCP tools server. It terminates Kubernetes ServiceAccount JWTs against the EKS OIDC issuer, enforces CEL authorization on the jwt.sub claim per route, and exports OTLP traces to Jaeger. That one component is how we give Agent-to-Agent (A2A) and Model Context Protocol (MCP) the same authentication, authorization, and tracing story.
Model Context Protocol (MCP)
Standardizes how agents talk to tools. Our financial tools (get_stock_price, calculate_portfolio_value, score_risk, get_market_trends) live in a single FastAPI JSON-RPC server exposed through MCP streamable HTTP. Adding a new tool requires only a new function and a gateway route, with no agent code changes.
Agent-to-Agent Protocol (A2A)
A protocol that defines how agents discover, delegate, and respond to each other. The financial advisor orchestrator uses A2A to delegate tasks to portfolio-analyst, risk-assessment, and market-data agents. Because every A2A call flows through the gateway, the authentication and authorization rules are enforced at the network layer, not inside each agent.
LiteLLM
An OpenAI-compatible gateway that routes LLM requests to Amazon Bedrock. It enforces RPM and TPM limits per virtual key, caches responses in Redis, falls back from Sonnet to Haiku on throttling or errors, and persists per-request spend to PostgreSQL. This is where multi-agent cost control lives.
Crossplane plus ArgoCD (GitOps)
Crossplane managed resources declare each agent’s AgentCore Memory, Browser, Code Interpreter, IAM role, and Pod Identity association. ArgoCD’s app-of-apps with sync waves brings the platform up deterministically. Adding a new specialist agent is a single entry in a Helm values file.
Consider a typical advisory question: “Is this client’s portfolio balanced, given their risk tolerance and today’s market?” The application calls /agents/financial-advisor with a short-lived Kubernetes ServiceAccount JWT. The Agent Gateway validates the token against the EKS OIDC issuer, enforces CEL authorization policies on the jwt.sub claim. The request is then forwarded to the orchestrator agent. The orchestrator reads the client’s profile (risk tolerance, goals, prior recommendations) from AgentCore Memory. It then issues three parallel A2A calls through the gateway to its specialist agents.
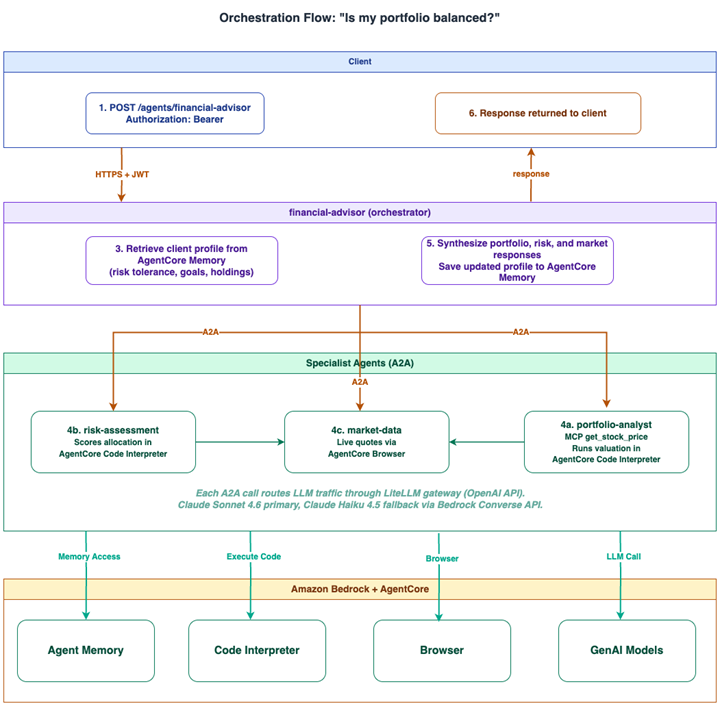
Figure 2. Orchestration flow for a single advisory request across four agents.
The portfolio-analyst agent values the client’s positions by calling MCP tools (get_stock_price, calculate_portfolio_value) and runs the valuation math inside AgentCore Code Interpreter. The risk-assessment agent scores the allocation against the client’s stated risk tolerance in its own Code Interpreter session. The market-data agent pulls a live quote snapshot through AgentCore Browser. The orchestrator composes the three specialist responses into a unified recommendation.
From a security perspective, east-west traffic between agents and the MCP tools server stays inside the cluster network and does not traverse the public internet. Agents authenticate to AWS services using EKS Pod Identity to assume IAM roles. This provides least-privilege access without embedding static credentials in container images or Kubernetes Secrets. The LiteLLM pod assumes an IAM role scoped exclusively to bedrock:Invoke* on the specific models we allow, enforcing model-level access control at the infrastructure layer. Every AgentCore resource (Memory, Code Interpreter, Browser) is bound to exactly one agent’s ServiceAccount. Each specialist agent can only access its own Memory store, its own Code Interpreter sandbox, and its own browser session. This isolation model scopes every agent to its own resources and permissions.
Implementation Highlights
We’ve published a reference implementation at the AWS Samples GitHub repository. It includes the Terraform for the EKS cluster, the ArgoCD app-of-apps chart, Crossplane compositions for AgentCore, four Strands agents, and the MCP tools server. Running scripts/bootstrap.sh takes a clean AWS account to a working platform in about 30 minutes. The README covers prerequisites and step-by-step instructions.
This section examines the key configuration decisions and explains the rationale behind each one.
Strands agents with scoped capabilities
Each agent is a small Python service written on the open source Strands Agents SDK. Three things define the agent’s behavior: a scoped system prompt, a list of MCP tools it is allowed to call, and the AgentCore capabilities it is bound to. A specialist agent cannot reach another specialist directly. The gateway will reject any JWT subject other than the orchestrator’s on a specialist route.
# financial-advisor/agent.py (excerpt)
@tool
def ask_portfolio_analyst(task: str) -> dict:
return a2a_client.call_agent("portfolio-analyst", task)
@tool
def ask_risk_assessment(task: str) -> dict:
return a2a_client.call_agent("risk-assessment", task)
@tool
def ask_market_data(task: str) -> dict:
return a2a_client.call_agent("market-data", task)
Tools as an MCP server
The financial tools live in a single FastAPI JSON-RPC service that implements MCP streamable HTTP. Every tool has a typed schema and unit tests. When we need a new tool later (tax-lot selection, for example), we add it to the MCP server and route it through the gateway. No agent code changes.
A2A and MCP through one policy-aware gateway
The Agent Gateway is the single place where authn, authz happen for both A2A and MCP. Authentication is Strict JWT against the EKS OIDC issuer. Authorization is a CEL expression on JWT claims. For a specialist route we match on jwt.sub being the orchestrator’s ServiceAccount; for the MCP route we match on the caller being one of the agents that declares the tool in its manifest.
# AgentgatewayPolicy (excerpt)
spec:
match:
route: portfolio-analyst
authz:
- expression: |
jwt.sub == "system:serviceaccount:financial-services:financial-advisor-sa"
Central LLM routing with LiteLLM
Every LLM call from every agent goes to LiteLLM’s OpenAI-compatible endpoint. LiteLLM checks the virtual key’s RPM and TPM budget, checks the Redis cache for a matching prompt, and only then hits Amazon Bedrock. If the primary model is throttled or errors, LiteLLM falls back from Claude Sonnet 4.6 to Claude Haiku 4.5 transparently.
LiteLLM records per-request cost to a PostgreSQL database and provides a /spend API endpoint for querying spend by agent, model, or time range. Running a multi-agent platform without a centralized LLM routing layer makes cost attribution challenging.
Safe code execution with AgentCore Code Interpreter
Both portfolio-analyst and risk-assessment agents generate Python code at runtime for valuation math, allocation checks, and correlation calculations. Running that code in the agent pod is not an option for FSI workloads: a bad completion could read a Secret, call a cluster API, or egress data. Instead, each specialist is bound through Crossplane to its own AgentCore Code Interpreter. The agent sends code, Code Interpreter returns stdout, and the agent parses a structured result. The pod does not execute the generated code. The security boundary is managed by AWS AgentCore.
# portfolio-analyst/agent.py (excerpt)
llm_result = inner("write Python that values a portfolio ... return ONLY code")
code = extract_python(llm_result.message["content"][0]["text"])
output = CodeInterpreter(AWS_REGION).invoke(code_interpreter_id=CI_ID, code=code)
return json.loads(output.stdout)
Cross-session memory with AgentCore Memory
The orchestrator agent uses AgentCore Memory to hold client context that an advisor would normally keep in a CRM: risk tolerance, stated goals, prior recommendations, and constraints. The orchestrator retrieves this context on every turn and updates it when the client confirms new guidance. AgentCore Memory is provisioned per agent and keyed on actor_id and session_id, so that a specialist cannot read the orchestrator’s context, and client sessions are isolated from each other.
Live market data with AgentCore Browser
The market-data agent uses AgentCore Browser to fetch live market quotes from a financial data provider. Browser runs outside the pod, which means we do not ship Playwright or Chromium inside the agent image. The image stays small, starts fast, and is easy to attest.
GitOps bring-up with ArgoCD and Crossplane
Two short Terraform stacks create the cluster and install ArgoCD. Everything else is GitOps. Sync waves order the rollout: CRDs first, then Crossplane core, then providers, then the agent gateway, then LiteLLM, then the financial-services chart. Inside that chart, each entry in .Values.agents renders a Crossplane Memory, Browser, Code Interpreter, IAM Role, RolePolicy, PodIdentityAssociation, a Deployment, a ServiceAccount, an AgentgatewayBackend plus HTTPRoute, and an AgentgatewayPolicy. Adding another compliance-check agent requires a single entry, as shown in the following example:
agents:
- name: compliance-check
role: specialist
image: { repository: financial-services-agents, tag: compliance-v1 }
agentcore:
memory: false
browser: false
codeInterpreter: true
tools: []
Observability and FinOps
This solution can be extended to configure Jaeger to receive OpenTelemetry Protocol (OTLP) from the agent gateway, so every user request produces a trace that spans the orchestrator, its specialists, their MCP tool calls, and their AgentCore interactions. LiteLLM exposes Prometheus metrics for request count, tokens, latency, and spend per model, and persists per-request spend to PostgreSQL. For production monitoring setup, use Amazon Managed Service for Prometheus plus Amazon Managed Grafana, and point LiteLLM’s DATABASE_URL at Amazon Relational Database Service (Amazon RDS).
Design Considerations
- This architecture extends naturally to support additional specialist agents and diverse financial workloads. Adding a new specialist agent is a single entry in the Helm values file. Crossplane renders the per-agent AgentCore, IAM, and Pod Identity resources, and the gateway chart renders the route and policy. The scope of a new agent is exactly one pull request reviewed through the standard GitOps pipeline.
- For domains that require deterministic math (valuation, risk scoring, tax optimization), let the agent generate code and run it in AgentCore Code Interpreter rather than embedding the math in the prompt. The LLM handles reasoning and decision logic. Python handles numerics. This separation supports reproducible and auditable calculations.
- Scope every agent to specific MCP tools and a specific AgentCore resource. Enforce the scoping at the gateway layer, not inside the agent code. This is designed to prevent prompt injection attacks from reaching routes the gateway does not allow, providing defense in depth that does not depend on the model behaving correctly.
- Run the LLM gateway in active-fallback mode, not round-robin. Keep Claude Sonnet for orchestrator reasoning where quality matters most. Route mechanical sub-tasks (summarization, JSON shaping, tool argument filling) to Claude Haiku through a separate LiteLLM virtual key with its own spend limits. That one routing decision is often the difference between a reasonable monthly bill and a surprising one. Advanced implementations can introduce per-agent spend caps and alerting thresholds through LiteLLM’s virtual key system.
- Turn on tracing from the beginning. Retrofitting distributed tracing into a multi-agent system after the first compliance review is difficult. OTLP export from the gateway is lightweight and makes incident review, audit response, and performance debugging obvious from the start.
- Treat agent prompts as versioned artifacts. Each specialist’s system prompt encodes workflow logic, compliance posture, and output format expectations. Review and roll them out through the same GitOps pipeline as application code. This provides full auditability of what each agent was instructed to do at any point in time.
- Tier the agents based on latency requirements. Client-facing orchestrators can maintain
minReplicasat 1 or more for predictable cold-start latency. Specialist agents can scale from a lower minimum because they are only invoked when delegated to, optimizing compute costs while maintaining responsiveness for the orchestration layer. - Tracing data and AgentCore Code Interpreter execution logs together form a ready chain of evidence, agent, prompt, tools, code, output, that compliance teams can use as explainability artifacts.
- For AgentCore Memory, confirm the KMS encryption model, set an explicit retention or TTL, use the delete API for purges, and fail closed in the orchestrator when Memory is unavailable.
- Plan for regional failover: the ArgoCD app-of-apps and Crossplane compositions are region-agnostic and can target a second EKS cluster for active-passive, with Memory state replicated or re-constructible from the system of record.
Conclusion
Multi-agent systems let FSI organizations build software that looks like the advisory team it is trying to support. Specialists operate in narrow domains. An orchestrator coordinates the specialists and composes the final answer. A shared platform handles identity, authorization, tracing, cost control, and safe code execution.
Running this pattern on Amazon EKS Auto Mode, with inference on Amazon Bedrock and capabilities on Amazon Bedrock AgentCore, gives platform teams a blueprint they can adopt incrementally. You don’t have to choose between “a framework for experiments” and “a custom platform we built ourselves.” You can start with one orchestrator and one specialist and add the next specialist as a pull request deployable via GitOps to your Kubernetes clusters. The reference implementation is housed at the AWS Samples GitHub repository.
Ready to explore more? Check out the Financial Services AWS Blogs to discover additional patterns and solutions designed specifically for the unique challenges of the financial services industry.