AWS for Industries
Optimizing data pipelines during mergers and acquisitions
The technology integration process that occurs as a result of mergers and acquisitions (M&A) can be complex and broad, ranging from re-platform to re-architecture. Planning for a technology integration can take months. While CFOs make sure of compliance with local and global requirements, such as exposure reporting, OFAC screening, and customer communication, CIOs are involved with the technology assessment of the licensing life cycle, data integration, application inventory assessment, and final decision to integrate to one core banking software or continue to run two separate platforms. The assessment period continues for months while regulatory requirements dictate for all activities to be completed under one commercial entity. The requirements range from fraud detection to anti-money-laundering (AML) and the bank secrecy act.
In this post, we’ll explore the interim-stage activities of an acquisition and share an “M&A Data Factory” architecture built on an AWS analytical platform. The M&A Data Factory acts as an integration hub for post-closing compliance activities. Furthermore, it will provide a repeatable platform with architectural components that can be reused in case of multiple acquisitions.
Core banking functions
Let’s look at the most common architecture used across financial institutions to support down-stream regulatory feeds (see the following figure).
The majority of financial institutions maintain several stacks of origination and servicing software applications. They range from retail banking applications to credit card and commercial lending servicing and origination.
Each source system application has been selected and developed to support specific business functionality. Each maintains specific customer-to-product relationships and transactions.
However, they don’t support cross-application data synchronization and consolidated regulatory reporting. Enterprise-wide regulatory reporting requires the total product, relationship, and transaction data of every customer. For example, a credit card servicing application wouldn’t have any information regarding retail banking transactions and vice versa.
Therefore, most organizations will have a centralized Extract, Transform, and Load (ETL) hub where all of the source system transactions are stored, cleaned, conformed, and integrated to provide a 360-degree view of every customer, their entire relationship, and all translations.
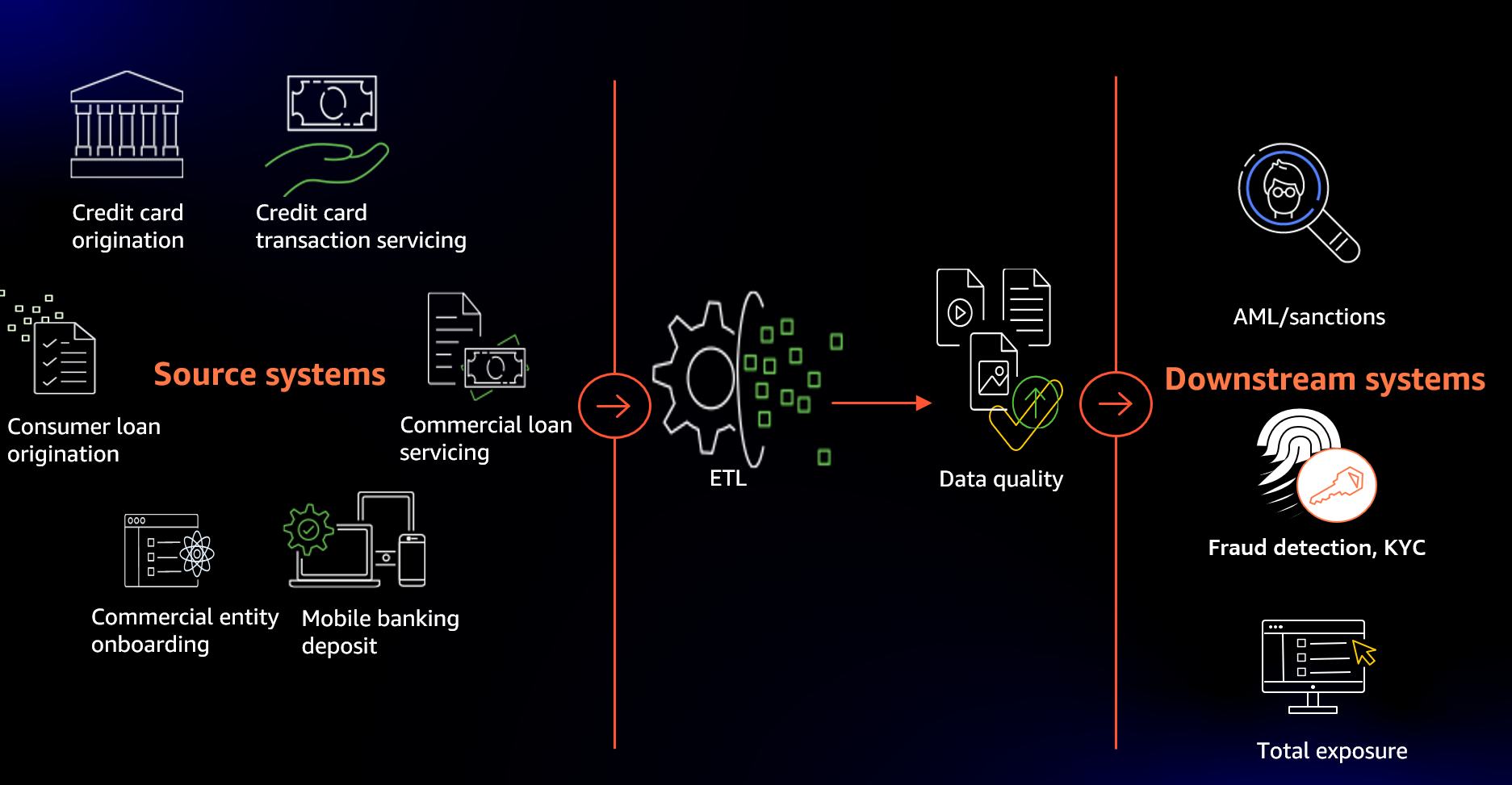
Figure 1 The common architecture for core banking functions
The Challenge
M&A brings many challenges that can impact core banking functions. The migration of a merger or acquisition to the new platform might take months and requires complex technology planning. Moreover, every type of acquisition deal is different, requiring bespoke integration approaches and ETL processes. The volume, variety, and velocity of the data continue to be too expansive. Therefore, creating a repeatable process for every acquired institution to provide data in a standard format is considered extremely complex.
Let’s look at the most common challenges that organizations face:
- People/Roles – M&As create a lot of confusion and extra work for employees of both of the acquired institution, as well as the acquirer. Employees are faced with the unknown, while being asked to continue supporting their original roles and responsibilities, as well as all of the new requests being added as part of M&A. A lot of new data extract requests are being generated. In addition, a lot of duplicated asks are being surfaced, and the engagement model isn’t clear. It’s unknown who will be the recipient of a specific task and who does what.
- Processes and Technology – Technology integration is one of the most complex and expensive challenges faced by organizations. M&A architects must consider repeatable processes that could ease the complexity of technology mergers and integrations. Build once, and use many times!
- Audit/Compliance – Regulatory reporting activities should include both acquired and acquirer data, and be completed under one entity. The risks are further complicated in the global economy as different countries have diverging standards.
- Short Timeline – Last but not least is the challenging timelines.
We’ll focus on designing a solution to address the above four challenges and accelerate the collaboration between merged organizations.
There are two types of patterns that financial organizations adopt when merging the new acquired institution’s data.
The first is data federation to unify heterogeneous datasets on demand at the reporting layer.
It’s unlikely that the two systems being merged have the same levels of regulatory compliance or policies, underwriting processes, nature of client base, and risk rating. Consolidating data when systems are completely incompatible and disparate may result in data quality issues. Moreover, it can have a ripple effect on the success of the M&A.
The second is data amalgamation between merging banks, as this provides a holistic single view of the customer with great visibility into the flow of financial transactions. Especially for processes such as AML, you can derive stronger signals of suspicious activity that can lead to massive money laundering trails.
Therefore, the following questions must be considered:
- How do you integrate the new data in an effective way?
- How do you create synergies between merging banking organizations?
- How do you build reusable technology infrastructure to support subsequent M&As?
In the rest of this post, we’ll focus on the data amalgamation and build an M&A Data Factory.
M&A Data Factory logical model
In this section, we’ll introduce you to the M&A Data Factory. We’ll start by creating a logical architecture design (see the following figure). Logical designs allow the architects to design a system that pertains to the abstract representation of data flows, data content, and encapsulated people and processes. This is done with the objective of creating a role/responsibility engagement model in parallel to the technology.
We’ll follow Amazon’s working backward methodology to create an effective design. Behind every successful technology deployment, you’ll find a problem that must be solved.
Let’s start from the downstream system. We’ll assume that your organization has an existing ETL system that feeds disparate source system data to the downstream regulatory systems. We’ll start by working with the product owner of that in-place product. The original requirement must be provided by them, as our goal is feeding the existing system with supplemental data for every M&A.
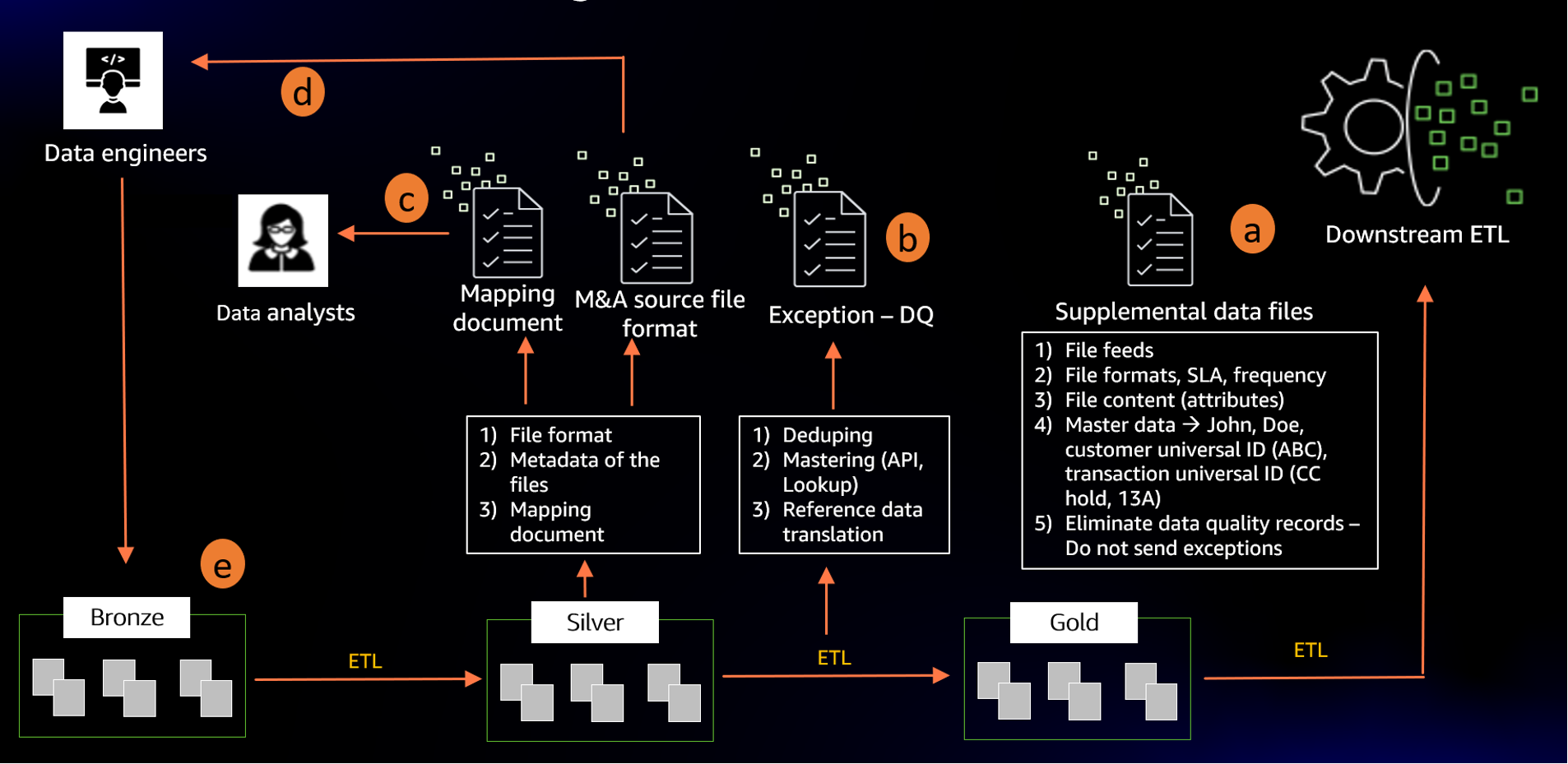
Figure 2 Illustrates M&A Data Factory logical model
Gold-ETL
2a. The Downstream ETL product owner will provide us with a list of all of the file feeds, their format, SLA, frequency, and notification needs. In addition, we capture details such as eliminating data quality issues and master data requirement.
Data quality issues can range from null SSNs to duplicated customer records, or invalid names and addresses.
Master data can be on customer records and their corresponding names and addresses. In addition, they provide us with a list of acceptable transaction codes, products, and relationship reference data. For example, they can request for all credit card hold transactions to be fed to their system as “CC123”.
The objective is to not feed bad data to the existing systems, as they have no mechanism in place to report or remediate the problem. Therefore, flooding their system doesn’t provide us with any meaningful architecture. It will overwhelm their system without any technological means to decrease the impact.
Once we have gathered the full downstream requirement, we’ll build a data model representing the consumption pattern. We call it gold data repository. This model represents the golden data that will be fed to the downstream-ETL. A new gold-ETL will be created to feed the data to the downstream based on the specific frequency and file format requirements. The gold data model and the gold-ETL will be designed and developed once and repeated many times.
This is the first repeatable component of this design. Golden data matches the downstream requirement, is free of duplicates, and doesn’t include data quality errors. Data has been transformed to include all of the reference codes valid to the downstream ETL.
Silver-ETL
2b. The next step will require building a silver model. The silver model should be flexible enough to store all of the different variations of M&A acquired institution data, and it will include duplicates and quality issues. Therefore, some of the data types should be created in a more flexible format, such as characters to allow all of the data to be loaded without any quality checks. This will require a flexible data platform. A silver-ETL program is needed to master the data, eliminate duplicates, translate transaction codes, and product types to the golden copy, as well as feed the data from Bronze to Gold. This silver-ETL is going to have the majority of the integration logic supported. It provides the customer-in-common of both the source and destination systems.
However, since the source and destination data models don’t change, it can be designed to run for all of the acquisitions. Therefore, it’s a repeatable process.
In addition, it covers data quality issues, such as duplicate customer records and missing transactions codes, and it includes canned quality reports that can be fed directly to the acquired institution team for data correction and quality scrubbing.
2c. The Silver-ETL program will require a mapping instruction to translate source system types and reference data to the destination. This requirement can be sent to the acquired institution’s data analyst, as they are actively working with the acquirer to drive core business function integration. The mapping document will serve as a key document for bringing together all of the heterogeneous data in the Silver layer.
2d. A copy of the Silver data model can be sent to the acquired institution’s data engineers as a requirement for new data feeds.
Bronze-ETL
2e. By now you’ve designed a process that can bring repeatable components to your M&A activities, plus clear roles and responsibilities for both parties. However, there’s one more situation that we must take into consideration. What about those scenarios where the acquired institution can’t cut files to the specific Silver data model spec? They might have canned reports or existing files, but no resources to generate new files to the specific spec.
In that case, we’ll introduce a custom component to the process as Bronze data repository. This data repository will be the recipient of any information that is rapidly available. A custom Bronze-ETL program can be written to transform the Bronze to Silver on a case-by-case basis.
Physical implementation of M&A Data Factory
We’ve gone over the logical model in some depth. Let’s discuss how we can build the M&A Data Factory powered by AWS analytical services. First, data analysts must quickly identify all of the new data sets, perform data quality checks, handle PII data, clean the data, and profile the data to understand trends and determine what business entities would be relevant for merging. Historically, they must rely on manual spreadsheets to explore and experiment with data to assess the business data assets that are compatible, or rely on data engineers and ETL developers to transform data into the required format. This often delays the process for weeks or months, as they can spend up to 80% of their time in data preparation tasks, rather than actually ingesting the new data to downstream ETL. Moreover, preparing the mapping document mentioned in 2c requires excessive manual effort.
To address these challenges, we’ll use AWS Glue DataBrew to build a pipeline that automatically scans the data assets, remediates the data quality issues, and then masks the PII data and finally produces the mapping document.

Figure 3 Illustrates the data preparation pipeline to identify business data assets.
Heavy lifting of the mapping document
DataBrew lets you profile the data in minutes and determine the business data assets that are ready for merging. You can easily profile and normalize terabytes and even petabytes of data directly with over 250 built-in transformations. Once you identify the business data assets, use AWS Glue crawlers to automatically infer the schema and persist the metadata into the Glue Data Catalog. Finally, the data analysts can analyze the new datasets using Amazon Athena, as well as automate the mapping document mentioned in 2c.
Data quality and PII
Additionally, you can set up data quality rules to perform the conditional checks mentioned in 2a. For example, the existing systems might mandate the non-null SSN column, and the values should be of certain length. When a data quality rule fails on the incoming datasets, you can inspect the failure, send an automated notification, and clean/enrich the data.
Handling sensitive data at scale during M&A has become extremely complex, especially if the acquired institution might need to adhere to new data privacy and regulatory needs enforced by the acquirer. Using PII statistics, you can identify potential PII columns and apply transformations to redact or encrypt the data at scale.
Now that we’ve identified the relevant data sets, let’s walk through the end-to-end architecture flow on a broader level.
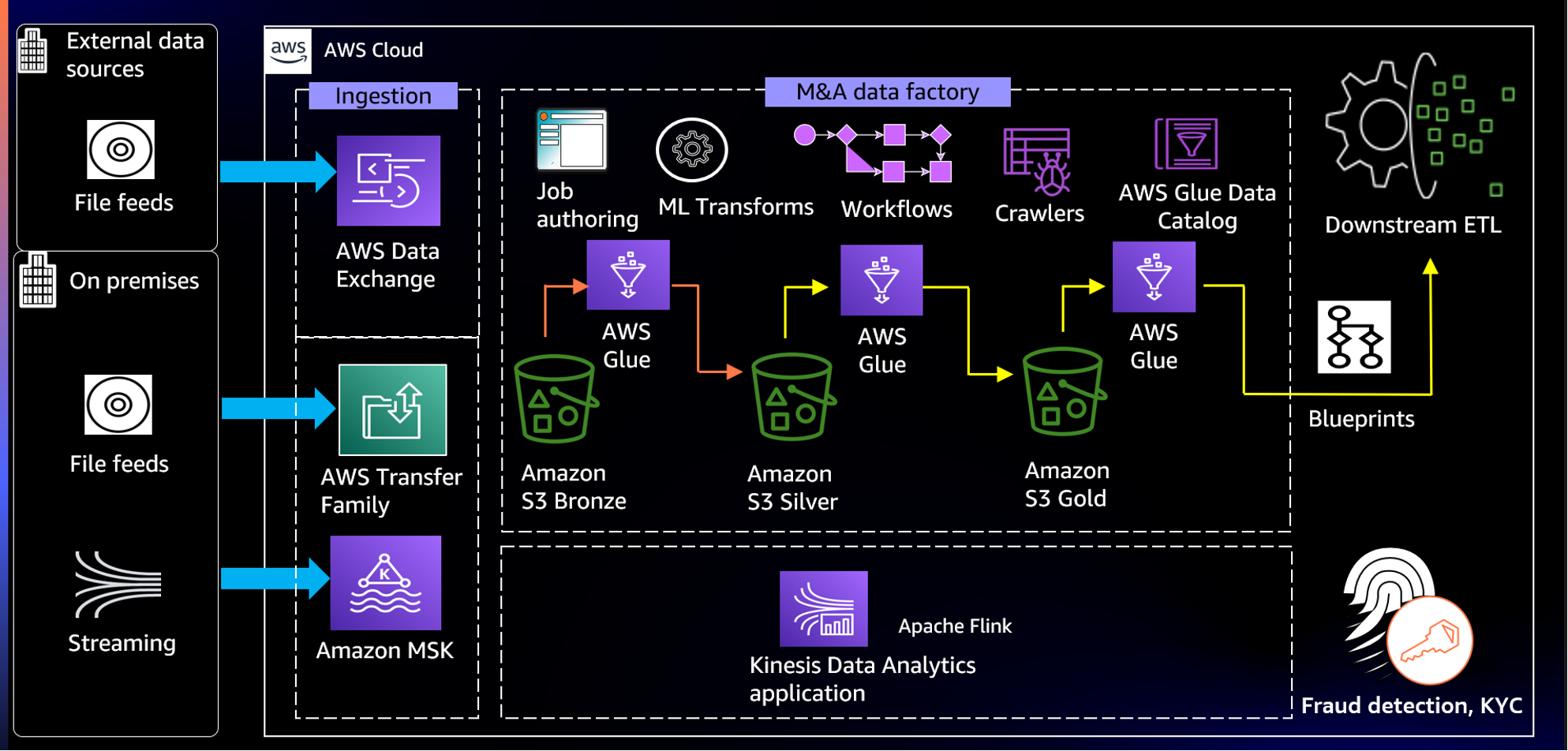
Figure 4 Illustrates how you can build the M&A Data Factory on AWS cloud.
Data ingestion
First, data is ingested from the acquired institution’s on-premises data centers into Amazon Simple Storage Service (Amazon S3) using AWS Transfer Family. Amazon S3 provides an optimal foundation for a data lake, because of its virtually unlimited scalability and high durability. Note that this architecture assumes the acquirer is still on-premises and can provide file feeds in batches. Now, to securely transfer files directly into and out of Amazon S3, Transfer Family provides fully-managed support. In addition, applications such as AML require external data, such as politically exposed persons (PEP) and watchlists. Utilize AWS Data Exchange to easily find and subscribe to external data in the cloud.
Data persistence
As shown in the figure above, let’s consider the three data models mentioned in the logical diagram that are stored in the Bronze, Silver, and Gold Amazon S3 buckets. We mentioned that you can automate the mapping document creation using DataBrew. This mapping document will also be directly written to the Silver S3 bucket and will act as an input during ETL jobs.
Data catalog
You can leverage AWS Glue crawlers to extract the schema in S3 buckets automatically, as well as persist the metadata in the AWS Glue data catalog. This metadata will be available to ETL jobs, as well as services like Athena to support ad-hoc querying on any of the data models.
Data curation
M&A Data Factory heavily leverages the functionality of AWS Glue, which is a fully-managed, serverless, and cloud optimized ETL service. Generally, post M&A data analysts and data engineers must spend months to analyze the data sets, understand data processing requirements, and provision and manage underlying compute resources. AWS Glue takes a data-first approach and lets you focus on the data properties and data manipulation to easily transform the data to a form where you can derive business insights in minutes instead of months.
There’s no need to configure and manage the underlying compute resources. AWS Glue automatically scales based on the new data processing requirements. Equally important is how with AWS Glue you only pay for the time that your processes take to run. The AWS Glue job encapsulates the ETL script. While creating the job, you can select between PySpark, Spark Streaming, and Python Shell. Data engineers with no spark skills can use Glue Studio to create an ETL script. You can customize this script to invoke your master data management (MDM) APIs or any external APIs.
Now that we’ve determined that AWS Glue is the best fit for this use case, let’s discuss how we build the three ETL pipelines. The Bronze-ETL highlighted in orange is bespoke for every acquisition. But the Silver-ETL and Gold-ETL processes highlighted in yellow pipelines should be standardized, as these are repeatable processes for every acquisition. You can choose to use AWS Glue blueprints to build and share reusable ETL processes. For example, you can create a compaction blueprint to compact numerous small files into a smaller number of larger files and optimize your Amazon S3 data lakes. Then you can reuse this blueprint for subsequent acquisitions by specifying the Amazon S3 location as one of the parameters.
When we discuss moving data from bronze all the way to gold zone, it’s inevitable that the data is duplicated between merging banks. We must de-duplicate and store the golden version of all of the data entities. However, the challenge in de-duplication is matching records and comparing all of the pairs, which is a “Big O squared”/O(n²) problem. With the AWS Glue ML transform – FindMatches, you can easily de-duplicate massive datasets. This is used and vetted in Amazon retail workloads.
Another approach to identifying duplicate data is to create your own or pre-built machine learning (ML) model. For example, the AWS Marketplace solution (Mphasis) provides a pre-built model that you can run in Amazon SageMaker.
We addressed the batch feeds processing and the general challenges by implementing M&A Data Factory. The final part of the architecture includes support for real-time requirements.
Data streaming
Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Kinesis Data Analytics can process and analyze the streaming transactions in real time and feeds into your downstream systems, such as Know Your Customer (KYC) and Fraud detection.
Refer to the following resources for an in-depth implementation of the architecture:
- Simplify data integration pipeline development using AWS Glue custom blueprints
- 7 most common data preparation transformations in AWS Glue DataBrew
- Streaming ETL with Apache Flink and Amazon Kinesis Data Analytics
- Implementing anti-money laundering solutions on AWS
Conclusion
In this post, we architected an end-to-end repeatable solution for M&As. Your organization’s downstream systems can differ from the assumption that we’ve made to build the solution. However, the design principle of working backward applies to every scenario.
Work backward from your problem, consider a logical design to include people and processes, and start innovating and building on AWS!