Artificial Intelligence
Author: Roy Allela

Scale Robot Reinforcement Learning with NVIDIA Isaac Lab on Amazon SageMaker AI
In this post, we show how to train robot policies for the Unitree H1 humanoid with NVIDIA Isaac Lab on Amazon SageMaker AI across two compute options: Amazon SageMaker HyperPod and Amazon SageMaker Training Jobs.
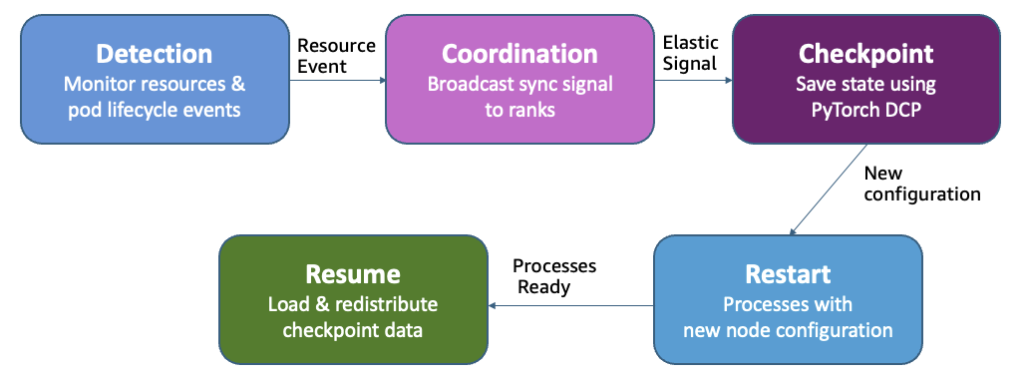
Adaptive infrastructure for foundation model training with elastic training on SageMaker HyperPod
Amazon SageMaker HyperPod now supports elastic training, enabling your machine learning (ML) workloads to automatically scale based on resource availability. In this post, we demonstrate how elastic training helps you maximize GPU utilization, reduce costs, and accelerate model development through dynamic resource adaptation, while maintain training quality and minimizing manual intervention.

Streamline machine learning workflows with SkyPilot on Amazon SageMaker HyperPod
This post is co-written with Zhanghao Wu, co-creator of SkyPilot. The rapid advancement of generative AI and foundation models (FMs) has significantly increased computational resource requirements for machine learning (ML) workloads. Modern ML pipelines require efficient systems for distributing workloads across accelerated compute resources, while making sure developer productivity remains high. Organizations need infrastructure solutions […]

Efficient Pre-training of Llama 3-like model architectures using torchtitan on Amazon SageMaker
In this post, we collaborate with the team working on PyTorch at Meta to showcase how the torchtitan library accelerates and simplifies the pre-training of Meta Llama 3-like model architectures. We showcase the key features and capabilities of torchtitan such as FSDP2, torch.compile integration, and FP8 support that optimize the training efficiency.

Accelerate Mixtral 8x7B pre-training with expert parallelism on Amazon SageMaker
Mixture of Experts (MoE) architectures for large language models (LLMs) have recently gained popularity due to their ability to increase model capacity and computational efficiency compared to fully dense models. By utilizing sparse expert subnetworks that process different subsets of tokens, MoE models can effectively increase the number of parameters while requiring less computation per […]

Announcing the Preview of Amazon SageMaker Profiler: Track and visualize detailed hardware performance data for your model training workloads
Today, we’re pleased to announce the preview of Amazon SageMaker Profiler, a capability of Amazon SageMaker that provides a detailed view into the AWS compute resources provisioned during training deep learning models on SageMaker. With SageMaker Profiler, you can track all activities on CPUs and GPUs, such as CPU and GPU utilizations, kernel runs on GPUs, kernel launches on CPUs, sync operations, memory operations across GPUs, latencies between kernel launches and corresponding runs, and data transfer between CPUs and GPUs. In this post, we walk you through the capabilities of SageMaker Profiler.