Artificial Intelligence
Category: AWS Data Pipeline
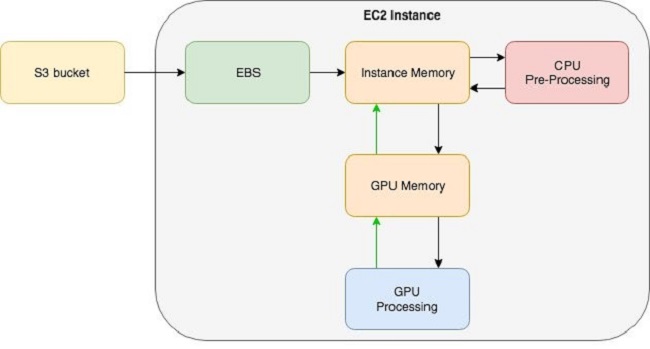
Maximize training performance with Gluon data loader workers
With recent advances in CPU and GPU technology, training complex and deep neural network models in a few hours is within reach for many state of-the-art deep models. However, when you use a system with such high processing throughput potential, the required data for the processing pipeline must be ready before each iteration.