AWS for M&E Blog
Asynchronous media processing on AWS: achieving broadcast quality at scale
Introduction
The media and entertainment industry is undergoing a fundamental shift toward cloud-based live production workflows. Broadcasters want to realize new avenues of revenue by unlocking global workflows, produce more content with fewer resources, and drive viewer engagement at scale. This shift reduces costs through decreased crew travel and capital expenses for production hardware that sits idle between events. It provides scalability and agility to handle variable production schedules without building for peak capacity. Cloud environments offer experimentation and innovation where you can test new technologies without disrupting live productions. They improve sustainability through reduced carbon footprint from decreased travel and more efficient data center operations. They also provide access to a global workforce that can operate productions from anywhere in the world.
Deterministic timing and synchronization are critical in broadcast operations. These are often achieved with clock-driven sequential processing where each component passes frames directly to the next stage in a workflow.
When you lift and shift traditional broadcast workflows to the cloud, they face a fundamental challenge: how can these systems preserve frame-accurate synchronization?
In this blog, we discuss how asynchronous processing architecture using the Matrox ORIGIN framework unlocks modern software-defined media workflows. This approach provides scalability and resiliency for live media applications while maintaining broadcast-grade frame accuracy.
Limitations of synchronous processing
In a scenario where a workflow has multiple live inputs (A and B), a video mixer and output; each stage waits for the previous one to complete its processing:
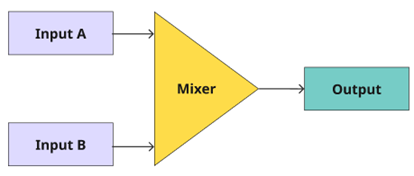
Figure 1: Live broadcast workflow with 2 inputs, a mixer, and an output
While the synchronous, clock-driven model guarantees temporal order through hardware synchronization, it creates critical limitations for distributed cloud deployments:
Vertical scaling only: Adding capacity means upgrading to larger hardware with hard limits on maximum inputs. You cannot simply add more compute nodes to increase capacity.
Tight coupling: Components communicate directly in a fixed topology, making it difficult to add, remove, or restart individual services without disrupting the entire pipeline.
Asynchronous architecture with deterministic timing
Matrox ORIGIN implements an asynchronous processing model that decouples control from compute while maintaining deterministic timing guarantees. The architecture consists of three core components:
Media Services: Independent software components (mixers, Input/Output (I/O) handlers, scalers, keyers, encoders) that process video/audio samples without direct coordination with other services. Each service runs in its own process for maximum isolation.
Control Tracks: Metadata channels that provide frame-by-frame control instructions, enabling operators to interact with a unified interface despite distributed processing.
Media Fabric: A distributed data transport layer that runs as a background service on each compute node. It manages the exchange of uncompressed media frames (“grains”) by coordinating local shared memory pools and inter-node network communication. The Fabric provides a unified API that allows services to retrieve content using logical identifiers, effectively decoupling data consumption from the physical location or identity of the producer.
But without direct synchronization between components, how does the system ensure frames across all nodes remain temporally aligned?
The answer is a deterministic timing model that defines exactly when each frame must be produced and when it becomes available for consumption; grain-based time reference.
In ORIGIN’s timing model, time is measured in discrete intervals called “grain intervals,” each representing one frame period (for example, 1/29.97 seconds for 1080i59.94 video). Every grain carries a sequence number that maps directly to absolute time through a precise equation:
NominalTimestamp = GrainSequenceNo × GrainInterval + EpochReference
This formula ties each grain’s sequence number to an absolute time reference (Unix epoch: January 1, 1970, 00:00 UTC). The result: every frame across every process and host has a predictable, deterministic timestamp.
Enabling stateless architecture
Stateless architecture is a software design approach where an application tier (such as a server or a microservice) does not store any session data, configuration, or context about previous requests on its local file system or memory. Each incoming request is treated as an independent transaction, containing all necessary information for the server to process it from scratch. This approach enables scalability, elasticity, and fault tolerance.
Matrox ORIGIN follows this design approach. Each media essence track within a stream is accompanied by a control track. This control track, decoupled from the media track and the media service instance (example underlying compute), declares the characteristics, actions, and desired state of the stream. This decoupling and stateless approach allows the application to be easily scaled and ported to different instances, AZs, or regions where a stream frame accurately resumes its functionality based on the definitions described in the control track.
This approach is analogous to the definition and implementation of Infrastructure as Code (IaC) where a template, a JSON or YAML document, declares what resources must be deployed and how they are configured, effectively giving the resources personas as they spin up.
Let’s take a simple example: for a given video track, based on time offsets defined in the control track, we change the slate color from red to green to blue to orange and to red again. The control points are described as shown:
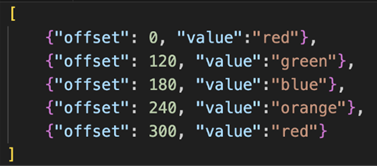
Figure 2: Control points of a video track
This control track describes the intended state of the service over a defined timeline. Each value represents a control point, specifying the desired state the service must assume at a precise moment in time. By externalizing intent in this way, the system can deterministically reproduce behavior without reliance on local state.
This mechanism enables fully deterministic, frame-accurate output across the system, regardless of where or when the media service instance is executed.
The diagram below illustrates the resulting output of the video track as the defined control actions are applied over time.
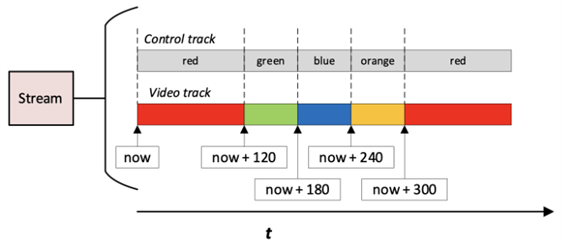
Figure 3: Video track within a stream with defined actions over time. The action points are defined by the control track
Scalability
Going back to our example of a live production, every component in the system, regardless of when it joins or which compute node it runs on, can now independently calculate which frame sequence number corresponds to the current time.
This temporal independence means new components can join the system at any time by:
- Synchronizing their system clock to Amazon Time Sync Service
- Calculating the current frame sequence number
- Beginning to produce or consume frames at that temporal position
As such, you can scale the system by deploying additional compute nodes that connect to the Media Fabric.
Producers commit media frames (grains) using strong identifiers, composed of a unique stream name and a sequence number. This structure allows consumers to retrieve specific frames based solely on their identity, without needing to know which specific producer instance supplied them.
In a live production workflow, this enables a serial composition pipeline. For example, a mixer consumes multiple input grains, processes them, and then commits a new resulting grain with its own identifier. This output then serves as the input for the next stage, creating a chain where media is processed sequentially across multiple independent services.
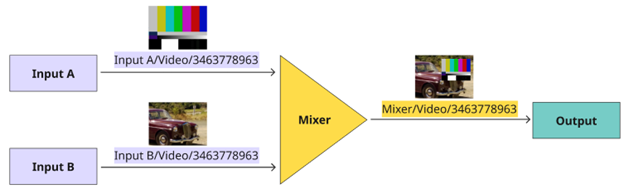 Figure 4: A mixer consuming two input grains, processing them, and then committing a new resulting grain with its own identifier
Figure 4: A mixer consuming two input grains, processing them, and then committing a new resulting grain with its own identifier
To expand this point, consider that as frames move through the pipeline, each processing step produces a new frame with a new identity. For example, two input frames are composited to create a new frame with the mixer, which is then consumed by an output. While each frame contains different content and therefore has a unique identifier, the sequence number remains constant throughout processing.
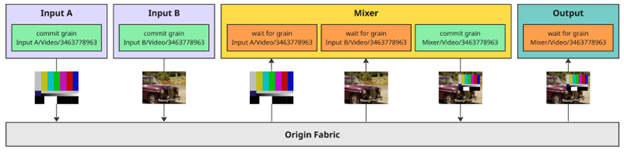
Figure 5: Processing steps in a workflow where producers and consumers interact with the fabric to commit and request frames using their unique identifiers
Keeping the same sequence number ensures that all producer clients contributing to the final frame operate within the same commit window.
Each client waits for the required inputs, performs its processing step, and commits its output independently. There are no direct connections between clients; instead, data flow is the result of multiple self-contained tasks executing concurrently within a shared commit window.
Fault tolerance
The same architectural principles that provide horizontal scaling also provide resilience through three mechanisms:
Multiple Redundant Producers Across Availability Zones
Multiple producers can publish frames with the same stream identifier to the Media Fabric. Consumers request frames by identifier—they don’t care which producer supplied it. If one producer fails, others seamlessly maintain continuity without manual intervention.
The system uses this capability for cross-AZ resilience. If one Availability Zone experiences issues, producers in other AZs continue publishing frames with the same sequence numbers within the same timing windows, and consumers experience no interruption.
Failure and recovery scenario:
Let’s say that in our example, a mixer component crashes at some frame sequence:
- Kubernetes detects the pod failure and starts a new instance
- The new mixer synchronizes to Amazon Time Sync Service
- It calculates the current frame sequence number based on the current time
- It begins consuming input frames from the Media Fabric starting at the current sequence
- It begins producing output frames within its commit window
- Downstream consumers continue reading from the fabric with minimal disruption
Loosely coupled component lifecycles
Because producers and consumers communicate through the Media Fabric rather than directly, they operate independently. If one component restarts, others continue unaffected, providing rolling updates and fault recovery without system-wide disruption.
Software Upgrade scenario:
- A new software version is available for the video mixer service
- ORIGIN Kubernetes controller starts a new pod running a second instance of the video mixer service
- The controller then terminates the original pod
- Downstream services running on other nodes don’t see any dropped frames
Hardware OS Maintenance scenario:
- A patch is available for an EKS node group
- Node upgrade is triggered
- New worker nodes are added to an Auto Scaling group and are available in EKS
- Old nodes begin to drain pods
- ORIGIN Kubernetes controller detects pod shutdown events and schedules new pods to be started on new nodes
- New pods are started, and start consuming and producing media content
- Downstream services running on other nodes don’t see any dropped frames
Implementation on AWS
Matrox built and tested a distributed live mixer application. The system started with a baseline configuration handling 10 concurrent 1080p50 live inputs (1080p 50fps, 2 channel PCM audio at 48KHz) and progressively added compute nodes to the EKS cluster. The system then scaled to over 110 concurrent uncompressed video inputs (without any reconfiguration of the ORIGIN software or operator interfaces). The key performance metrics were:
- Frame accuracy: Sub-frame synchronization maintained across all distributed services
- Latency: Consistent processing latency regardless of input count
- Failover: Seamless transition when simulating instance failures across Availability Zones
- Resource efficiency: Dynamic pod scaling based on actual workload, with unused capacity automatically released
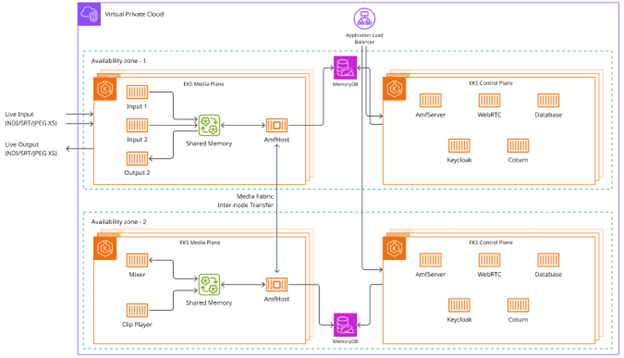 Figure 6: Architecture diagram for Matrox ORIGIN running on AWS in a resilient mode
Figure 6: Architecture diagram for Matrox ORIGIN running on AWS in a resilient mode
The system used the following AWS services:
Amazon Elastic Kubernetes Service (Amazon EKS) cluster: Spans multiple Availability Zones for high availability, with Kubernetes managing pod placement, health checks, and automatic failover.
Amazon EC2 instance types: Mixed instance deployment using c6in.8xlarge instances (CPU-optimized with 50 Gbps enhanced networking) for I/O-intensive services and g4dn.4xlarge instances (GPU-enabled) for effects processing and compositing.
Elastic Fabric Adapter (EFA): Provides Remote Direct Memory Access (RDMA) support for ultra-low latency media transport between instances, critical for uncompressed 4K workflows requiring up to 100 Gbps bandwidth.
Amazon Time Sync Service: Provides microsecond-accurate UTC synchronization across all compute nodes, allowing the deterministic timing model to function reliably across distributed resources.
Elastic Load Balancing: Distributes traffic to ORIGIN API endpoints across multiple instances for redundancy.
Amazon CloudWatch and Amazon Managed Grafana: Real-time monitoring of frame processing rates, latency metrics, and resource utilization.
Conclusion
In this post, we discussed how asynchronous processing architecture unlocks the cloud’s full potential for live media production by providing both vertical and horizontal scaling while maintaining broadcast-grade frame accuracy. By replacing hardware synchronization with software-based timing contracts and decoupling components through a content-addressable Media Fabric, you can build elastic, resilient production systems that scale to hundreds of inputs without sacrificing precision.
Visit Matrox ORIGIN to learn more about ORIGIN