AWS for M&E Blog
What’s in your S3 Bucket? Using machine learning to quickly visualize and understand your media files in S3
As organizations make their transition to the AWS cloud, they often find themselves asking the question “what’s in that AWS S3 bucket?” In an environment where leadership teams expect fast answers from IT, how do you dissect an S3 bucket with ten terabytes and hundreds of thousands of audio files or documents without a way to quickly surface metadata and follow up with visualizations?
Recently, the leadership team at Antenna International, the world’s leading supplier of mobile interpretation for the cultural and heritage sector (aka the company that creates audio and multimedia guides for many of the world’s most important museums), started seeking more clarity regarding their S3 bucket in us-east-1. Instead of spending valuable time and energy building a proprietary solution they would then have to update and manage, Antenna leveraged a product in the AWS Marketplace called LENS.
LENS, developed by Digital ReLab, gives users the power to view, play, and share media files in S3 without moving them. Using Tika and Amazon Rekognition AI for images, LENS runs powerful data transformations at a speed of over 50-terabytes-an-hour revealing powerful insights in minutes rather than weeks or months. Questions like “how many files are in my bucket?” or “how many duplicate files do we have across these three buckets?” become very easy to answer.
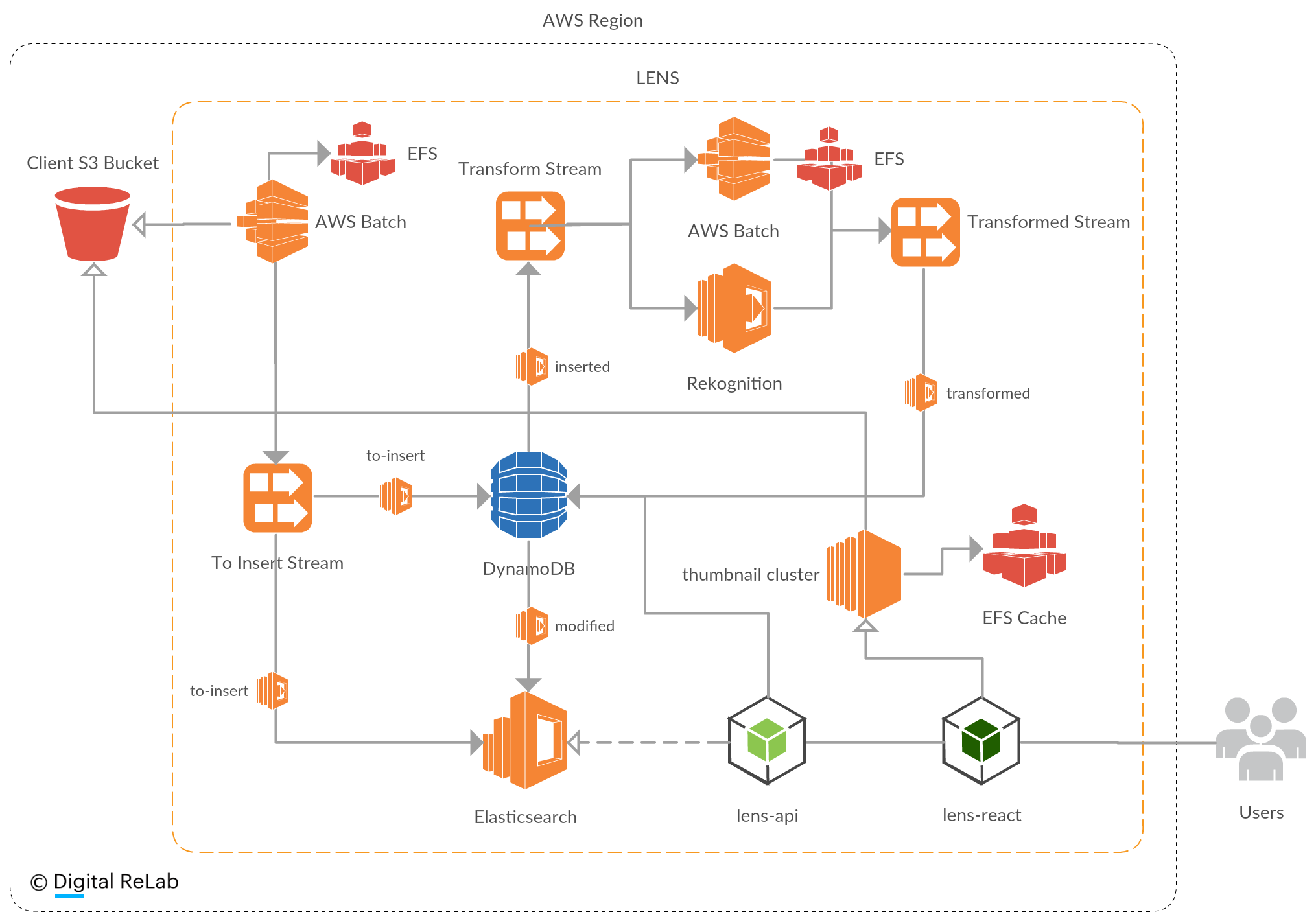
In the case of Antenna International, once LENS surfaced Antenna’s file data, Digital ReLab configured and overlayed the open-source data visualization tool, Kibana, to surface powerful insights. The result? According to Alice Walker, Creative Strategy Director at Antenna International, “In a very short amount of time, and with only a small investment, we were able to get key answers and insights about our IP.”
For AWS customers who are staring into the abyss of their AWS S3 buckets and wondering “what the heck is in there?” – the AWS Marketplace is a great place to find a solution, like LENS.