Front-End Web & Mobile
AWS AppSync field-level resolvers: Enhancing GraphQL API development
Introduction
In this post, we’ll explore AWS AppSync field-level resolvers and how they can enhance your GraphQL API development. Field-level resolvers are powerful units of code that determine how data is fetched, processed, and returned for specific fields in your schema types. By leveraging field-level resolvers in AWS AppSync, you’ll learn how to efficiently handle complex data operations, integrate multiple data sources, and create more flexible and performant APIs. We’ll cover the basics of field resolvers and how they can help you build scalable and responsive applications. Whether you’re new to GraphQL or looking to optimize your existing AWS AppSync implementations, this post will provide you with practical insights to make the most of field-level resolvers in your projects.
Resolver patterns with AWS AppSync
AWS AppSync offers various resolver strategies to accommodate different data access patterns and complexity levels. For straightforward operations involving a single data source, unit resolvers are the go-to solution. These resolvers handle simple queries or mutations, mapping directly to a specific data source like Amazon DynamoDB or AWS Lambda. As applications grow more complex, pipeline resolvers become invaluable for orchestrating multiple data operations. These allow developers to chain together a series of functions, each performing a specific task such as data validation, transformation, or aggregation from multiple sources. This modular approach enhances code reusability and maintainability.
Field-level resolvers in GraphQL provide fine-grained control over individual fields within a type, allowing customized data fetching or computation for each field independently. They are particularly useful when different fields in the same type need to be resolved from various data sources or require unique processing. The choice between field-level resolvers and pipeline resolvers depends on specific application requirements, with field-level resolvers offering granular control and pipeline resolvers providing a structured approach for complex, multi-step operations.
Field-level resolvers provide a different method to reuse query logic in your code. In a pipeline resolver, you can reuse code through AWS AppSync functions, while field-level resolvers allow a field associated with a type to resolve using the same logic from multiple query patterns.
Restaurant scenario
To better understand field-level resolver implementation, we’ll discuss a practical scenario. This scenario explores a common use case in the restaurant industry where a query operation retrieves comprehensive information about a restaurant, including its menu items.
Creating the resolvers
For this example, we will use an Amazon DynamoDB table to store information about the restaurants and an Amazon Aurora PostgreSQL database for storing menu information.
// Restaurant DynamoDB table design
Primary key: id (String)
Attributes:
- name (String)
- address (String)
- menu_id (String)
// Menu table schema
CREATE TABLE menu (
id VARCHAR(36),
menu_id VARCHAR(36),
item TEXT NOT NULL,
description TEXT NOT NULL,
price NUMERIC(10,2) NOT NULL,
PRIMARY KEY (id)
);Creating the getRestaurantDetails field resolver
To retrieve the restaurant details for a single restaurant, we can attach the following unit resolver to the getRestaurantDetails query operation. In the resolver below, we are able to simplify the interaction to the DynamoDB table using the AWS AppSync DynamoDB module.
import { util } from '@aws-appsync/utils';
import { get } from '@aws-appsync/utils/dynamodb';
export function request(ctx) {
return get({ key: { id: ctx.args.id } });
}
export function response(ctx) {
if (ctx.error) {
util.error(ctx.error.message, ctx.error.type);
}
return ctx.result;
}Resolving the menu field
The previous resolver allows us to retrieve the name, address, and menu_id for a specific restaurant. Now we need a way to retrieve the menu items as part of the same query operation. The unit resolver below is attached to the menu field in the Restaurant type so that whenever the Restaurant type is returned using a query operation, this resolver code executes to resolve the menu field. Similar to the resolver above, we are able to simplify the interaction to the PostgreSQL database using the AWS AppSync RDS module.
import { util } from "@aws-appsync/utils";
import { select, sql, createPgStatement, toJsonObject, typeHint } from "@aws-appsync/utils/rds";
export function request(ctx) {
const menuId = ctx.source.menu_id;
const fetchMenu = select({
table: "menus",
columns: "*",
where: {
menu_id: { eq: menuId },
}
});
return createPgStatement(fetchMenu);
}
export function response(ctx) {
const { error, result } = ctx;
if (error) {
return util.appendError(error.message, error.type, result);
}
return toJsonObject(result)[0];
}Notice that on line 4 in the resolver above, we’re able to reference the menu_id which was resolved as part of the parent Restaurant type. In the resolver, you’re able to access any previously resolved fields from the parent type using the ctx.source object. For more information on the structure of the ctx object, please refer to the documentation.
Setting up data
Before executing the query, let’s seed the databases with some sample data. For the PostgreSQL database, execute the following statement:
INSERT INTO
menus (id, menu_id, item, description, price)
VALUES ('39a4e192-92ce-4665-b874-7ffe7ba2d757', '9ce86066-1a49-4f41-b817-8fa605f680d5', 'Strawberry Milkshake', 'Made with 100% artificial ingredients', 10.21);
INSERT INTO
menus (id, menu_id, item, description, price)
VALUES ('0f75668f-3014-4c42-bf82-3da8543b59ad', '9ce86066-1a49-4f41-b817-8fa605f680d5', 'Apple Pie', 'Contains zero apples', 7.11);For the DynamoDB table, insert the following item:
{
"id": {
"S": "0cbf6478-d2c3-4549-a2d6-b4b8a3ddb582"
},
"address": {
"S": "1234 Main Avenue"
},
"menu_id": {
"S": "9ce86066-1a49-4f41-b817-8fa605f680d5"
},
"name": {
"S": "Sam's Diner"
}
}Example query
Below is an example query that illustrates the field resolution we described above. To resolve the requested data for this query operation, AWS AppSync will first resolve the Restaurant type and then subsequently will resolve the menu field in the parent Restaurant type. This operation results in 1 network call from the client while the backed resolution complexity is completely abstracted away from the client.
query MyQuery {
getRestaurantDetails(id: '0cbf6478-d2c3-4549-a2d6-b4b8a3ddb582') {
name
id
menu_id
address
menu {
item
price
description
}
}
}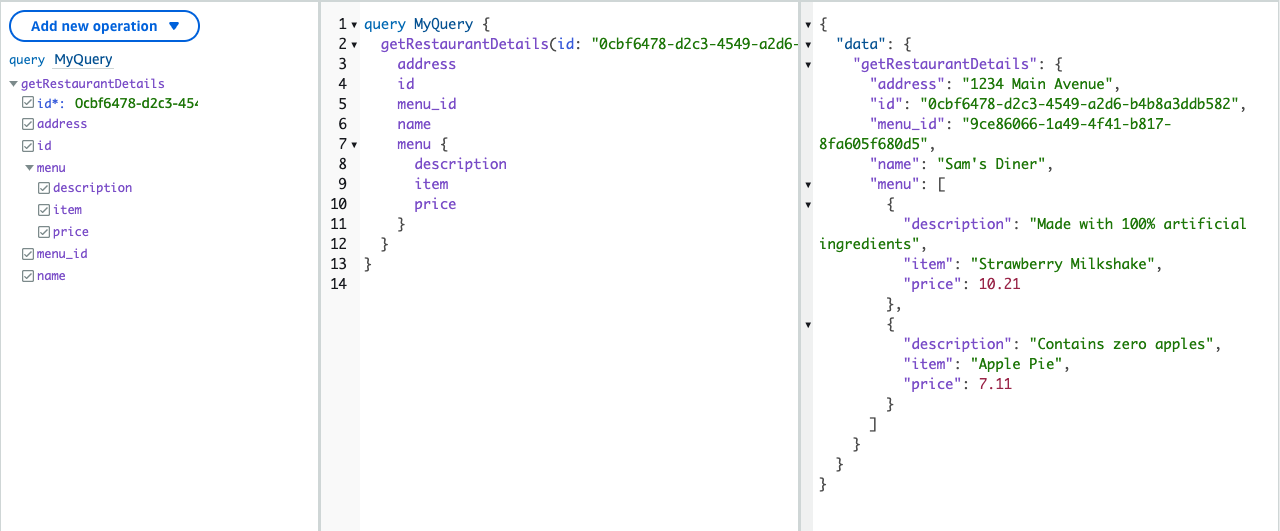
AWS AppSync query editor
When dealing with relatively static information, such as menu items that don’t change often, leveraging caching can significantly boost your query operations’ performance. AWS AppSync offers two caching modes: per-resolver caching and full request caching. For expensive overall requests with many resolvers, the full-operation cache minimizes load and increasing performance across the entire request, while per-resolver caching minimizes load on a resolver, even across multiple request types. By enabling this feature, you can dramatically reduce response times and minimize unnecessary data fetches, resulting in a more responsive and efficient application. To implement caching in AWS AppSync, simply activate the “Per-resolver caching” or “Full request caching” option in the caching section of the AWS AppSync service menu. Per resolver caching allows fine-tune your caching strategy by configuring the caching keys and TTL for your cached data
Conclusion
In conclusion, AWS AppSync field-level resolvers offer a powerful and flexible way to enhance your GraphQL API development. By leveraging field resolvers, you can efficiently handle complex data operations, integrate multiple data sources, and create more responsive and scalable applications. Whether you’re dealing with straightforward queries or more intricate data relationships, field-level resolvers provide the granular control needed to resolve individual fields independently. This approach not only optimizes performance but also promotes code reusability and maintainability. As your API evolves, you can split the implementation into different APIs that can be merged into an AWS AppSync Merged API, further enhancing modularity and scalability. As demonstrated in the restaurant scenario, field resolvers can seamlessly fetch data from different sources and aggregate it into a single, efficient GraphQL query. By understanding and implementing field-level resolvers, you can unlock the full potential of AWS AppSync to build more dynamic and robust APIs.
Amazon Aurora MySQL-Compatible Edition now supports a redesigned RDS Data API for Aurora Serverless v2 and Aurora provisioned database instances. Data API enables access to Aurora databases via AWS AppSync GraphQL APIs through direct data sources which means you can use this same blog with a MySQL Aurora database with some minor changes to the resolver code.