Microsoft Workloads on AWS
How to set up high availability for SQL Server at DR site that was restored using AWS Elastic Disaster Recovery
In an earlier post, I talked about how to set up a disaster recovery (DR) solution for SQL Server Always On availability groups (AG) deployed on Amazon Elastic Compute Cloud (Amazon EC2) platform to another AWS Region. In this follow-on post, I will show you how to set up High Availability (HA) for SQL Server on an Amazon EC2 instance that was restored using AWS Elastic Disaster Recovery.
In this scenario, a customer has set up their disaster recovery solution using Elastic Disaster Recovery for SQL Server using block level replication. By selecting the SQL Server Always On availability group as a source for AWS Elastic Disaster Recovery replication, it will replicate your primary node. However, when the DR system is brought up on your target cloud, the DR copy of the cluster will be restored as a standalone SQL Server machine.
If your SQL Server Always On cluster is built on SQL Server failover clusters, it will be replicated to Amazon EC2 as a standalone SQL Server instance. Since Elastic Disaster Recovery does not check for Windows cluster services, the Windows failover cluster will break in this case. You will need to fix the cluster and set up HA using Always On Availability Groups for SQL Server Failover cluster. I will show you how to do that in this post.
Solution Overview
SQL Server Always On availability groups are an advanced, enterprise-level feature to provide high availability and disaster recovery solutions. This feature is available if you are using SQL Server 2012 and later versions.
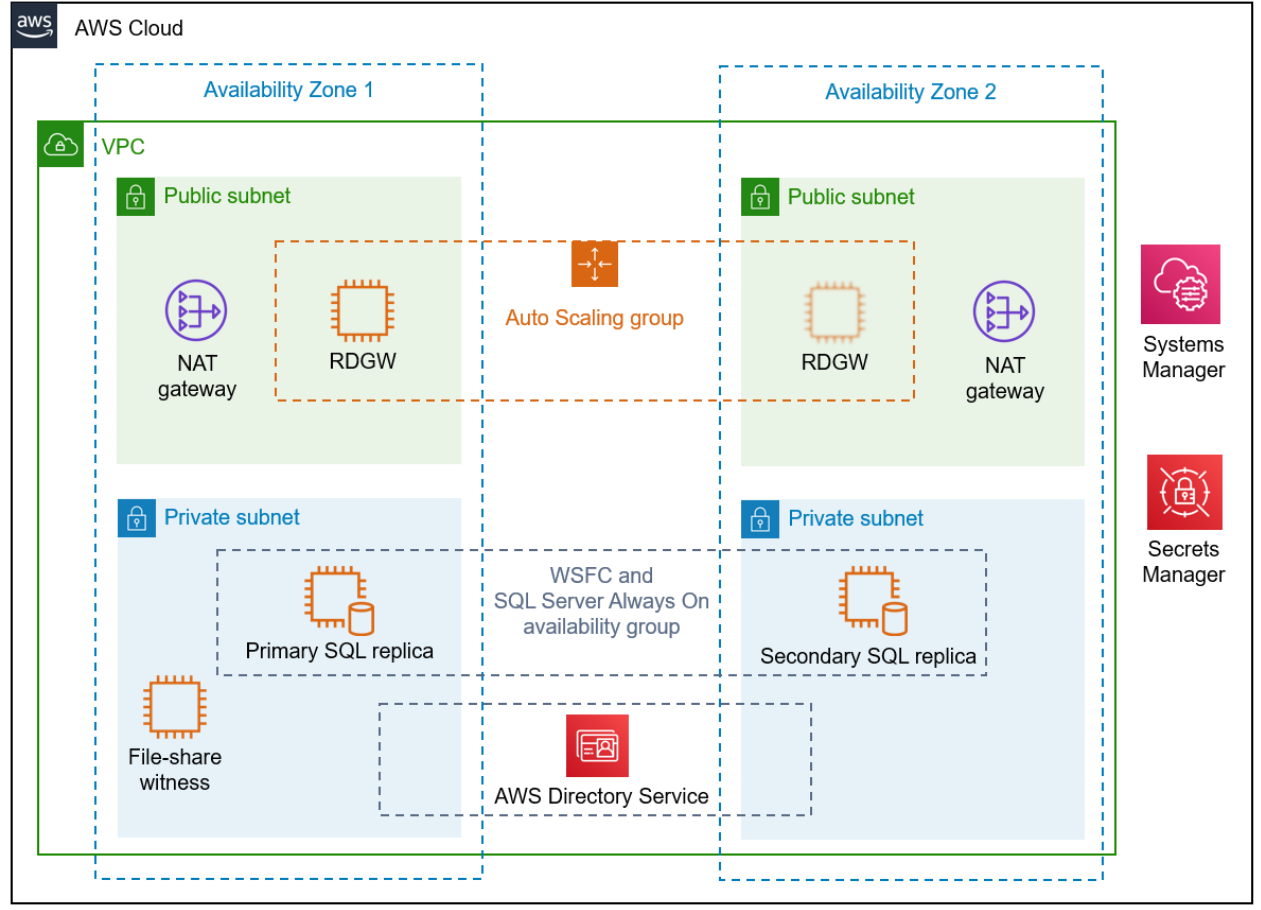
Figure 1 How to setup HA at the DR site restored using AWS Elastic Disaster Recovery solution overview
You can use AWS Elastic Disaster Recovery to recover your SQL Server without any issues. However, you must extend your Windows domain to AWS if the Always On availability group nodes and the cluster resources depend on Active Directory. AWS Elastic Disaster Recovery can replicate SQL Always on nodes without any issues as long as you are not running a Failover Cluster Instance (FCI) as part of an Availability Group.
Prerequisites
- VPC in secondary Region
- Subnet with two Availability Zones in a secondary Region
- Active Directory domain replicated in AWS secondary Region
- SQL Server on EC2 for primary server
- SQL Server on EC2 for secondary server
- SQL Server Management Studio
- Security groups to ensure the secure flow of traffic between the instances deployed in the VPC
Here are the steps to recover and rebuild Windows Failover Cluster and SQL Server Always On cluster at your DR site:
1.When trying to join the server SQLV04DR.octank.com to the primary Region cluster name the first time, you will get an error, as shown in Figure 2.
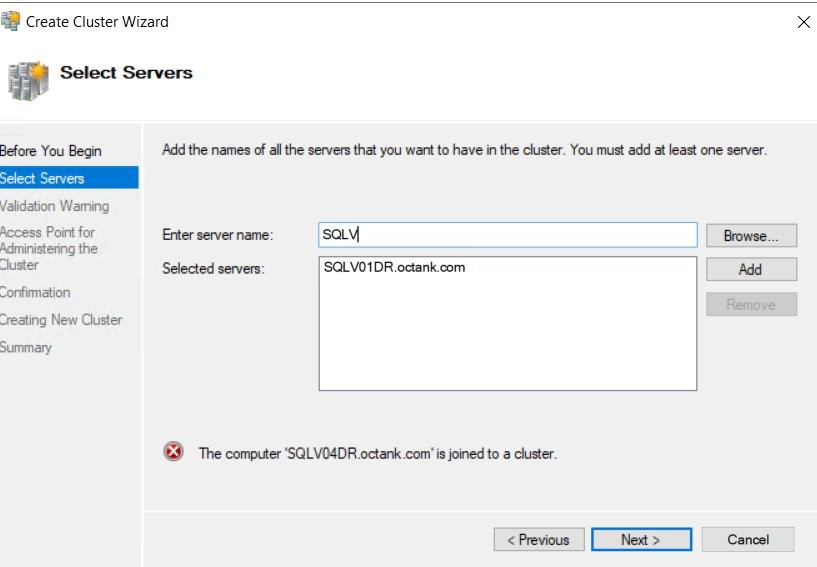
Figure 2 Check Windows Cluster Status
2.To resolve the error, you have to stop the Cluster Service using the Windows services console.

Figure 3 Stop Cluster service
3.Create new cluster using the Create Cluster wizard.
4.Change the cluster’s primary and secondary IP addresses to the EC2 instance’s unused secondary IP (e.g. 10.0.1.18 and 10.0.2.18). Refer to Figure 4.
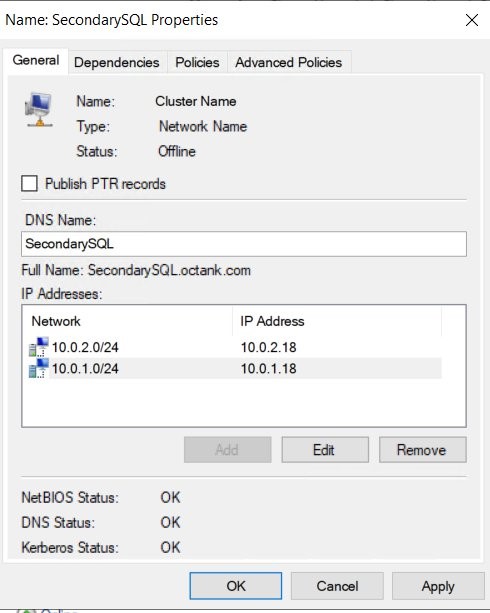
Figure 4 Add IP address for secondary EC2 instance for clustered nodes
5.Right-click the IP address (10.0.1.18) and bring it online for the primary IP and cluster IP address.
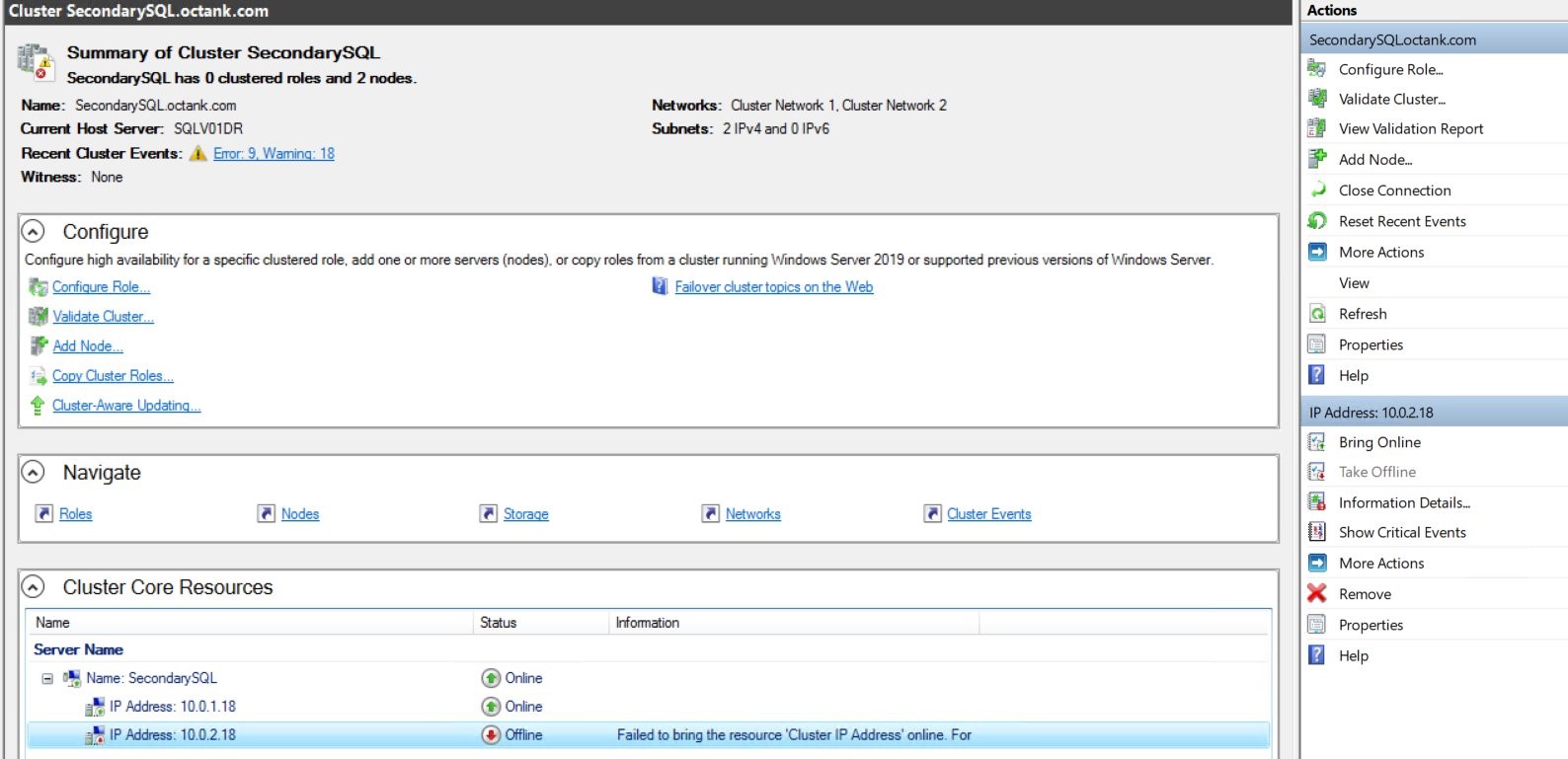
Figure 5 Validate Cluster setup
6.Validate that the cluster is running with both nodes (SQLV01DR and SQLV04DR) added.

Figure 6 Validate Cluster setup using Failover Cluster Manager
7. Now set up SQL Server Always On Availability group using the SecondaryDR (SQLV04DR) cluster:
In Figure 7, you will note that the cluster is broken and databases are restored as standalone databases on both instances SQLV01DR and SQLV02DR.
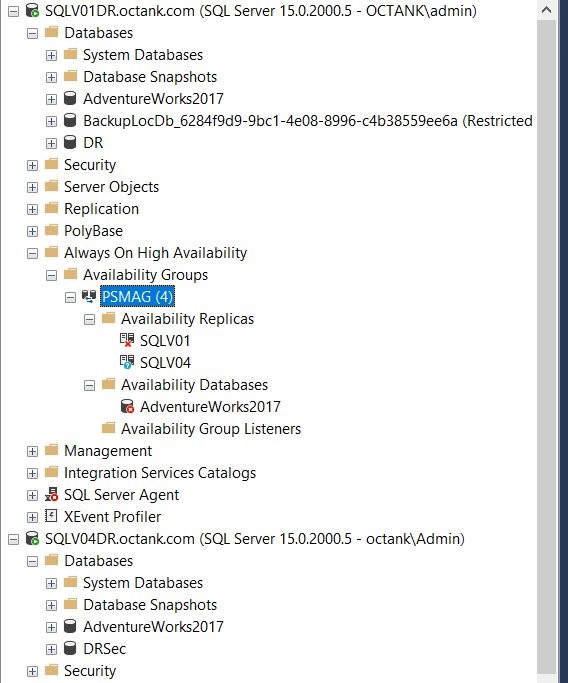
Figure 7 Check SQL Server Always on AG status using SSMS.
8.Remove the availability group from both the primary (SQLV01DR) and secondary (SQLV04DR) database servers. Refer to Figure 8.
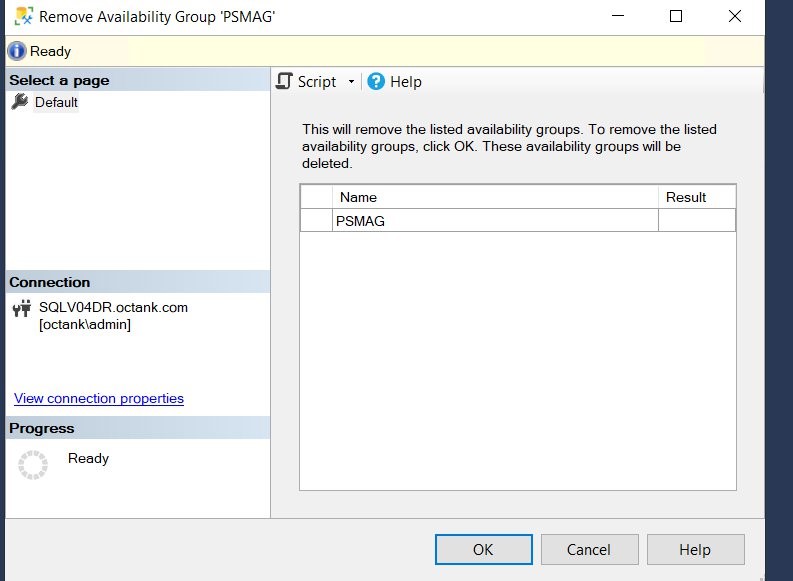
Figure 8 Remove SQL Server Always on AG.
9.Before you add the Always On availability group, you have to turn the Always On feature off and on again. One common error is if the Enable Always On Availability Groups configuration for the SQL Server Services was turned on before you have installed and configured the Windows Failover Cluster. If you don’t follow this step, you might get error:
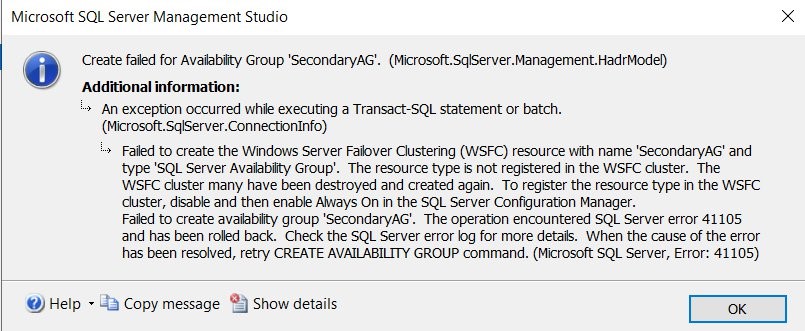
Figure 9 Error message if you don’t turn off Always On feature
10. If you receive this error, simply stop the Enable Always On Availability Group option, restart the SQL Server Services, re-enable the option, and then restart the service. Refer to Figures 10 and 11.
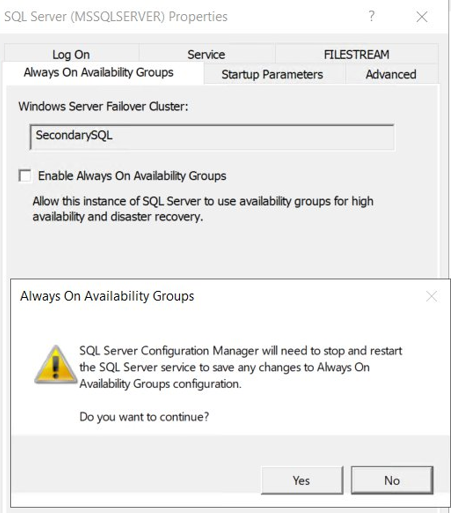
Figure 10 Stop Always on AG from SQL Server service console
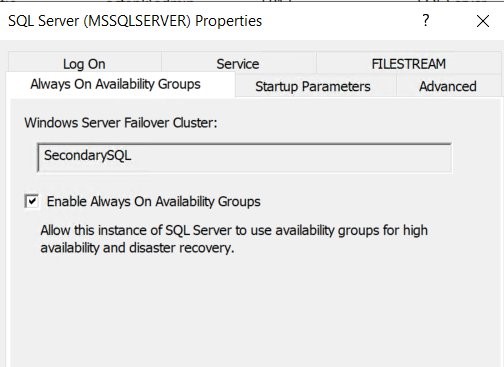
Figure 11 Enable SQL Server Always on availability group
11. Restart SQL Server service after the changes.
12. Delete the database from the secondary server (SQLV04DR), as both databases are now out of sync.
13. Create a new Availability group replica on the primary database server (SQLV01DR).
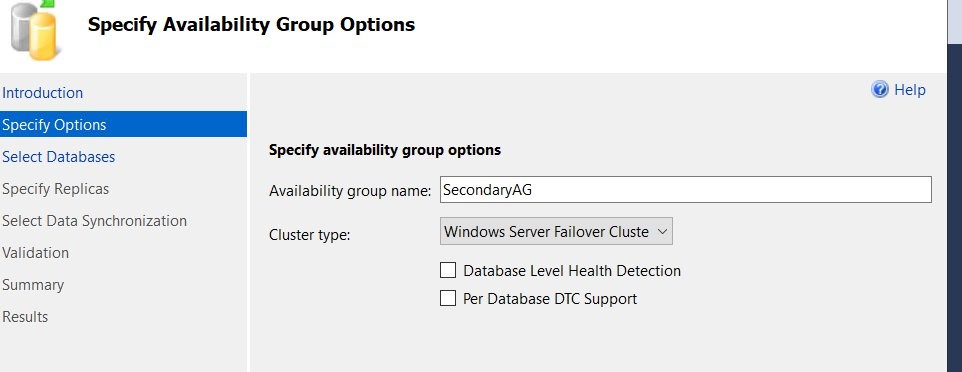
Figure 12 Create SQL Server Always on AG
14. Add replica with synchronous commit for both the primary and secondary databases. In this case, SQLV01DR is the primary database server and SQLV04DR is secondary database server.
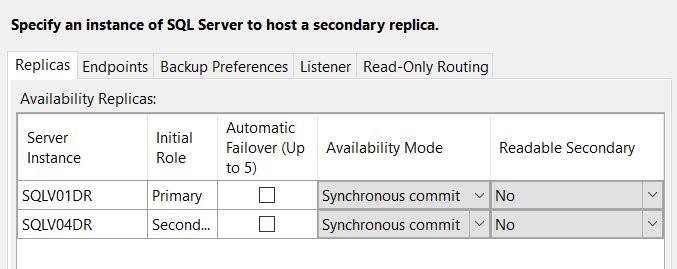
Figure 13 Add SQL Server replica
Tip: Create the Always on availability group replica and add secondary with automatic seeding.
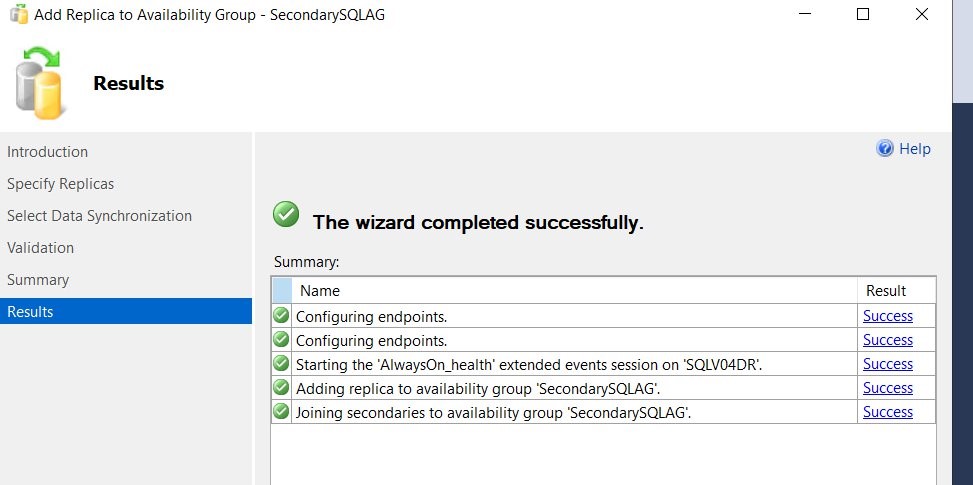
Figure 14 SQL Server AOAG add replica status check
In Figure 15, your primary and secondary database are back in a High Availability configuration with a synchronized replica.
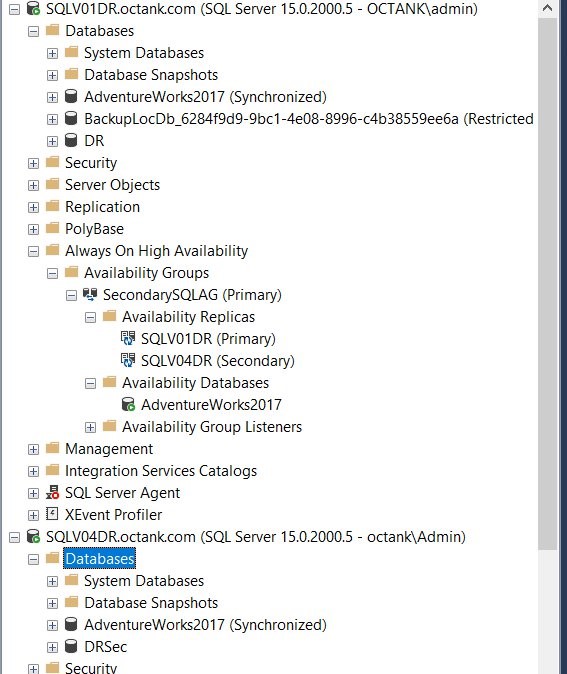
Figure 15 Verify SQL Server AGAO status using SSMS
Conclusion
When you use AWS Elastic Disaster Recovery as a disaster recovery solution, it will bring up the SQL Server primary server as a standalone server. In this post, you have learned how to set up High Availability (HA) for SQL Server on an Amazon EC2 instance that was restored using AWS Elastic Disaster Recovery.
You can also set up Always On availability group using AWS Launch Wizard for new deployments. To learn more about it, check simplify SQL Server Always on availability group deployment using Launch Wizard.
To learn more about best practices of running SQL Server on AWS, check best practices of running SQL Server on EC2.
AWS can help you assess how your company can get the most out of cloud. Join the millions of AWS customers that trust us to migrate and modernize their most important applications in the cloud. To learn more on modernizing Windows Server or SQL Server, visit Windows on AWS. Contact us to start your modernization journey today.