AWS Cloud Operations Blog
Improve the resiliency with AWS Fault Injection service and Amazon ARC Region switch
System impairments occur frequently in distributed cloud environments, making application resilience critical for customers. While traditional disaster recovery testing approaches are often manual and time-consuming, modern chaos engineering practices help validate your application’s ability to handle failures automatically.
Amazon Application Recovery Controller (ARC) simplifies application recovery across AWS Regions and availability zones by providing readiness checks and routing controls. The new Region switch service orchestrates seamless recovery with flexible workflows, supporting both active/passive and active/active configurations. This fully managed service offers real-time recovery dashboard to monitor progress, automatic failover capabilities, and independent data planes for maximum reliability during failover scenarios.
AWS Fault Injection Service (FIS) enables you to conduct controlled chaos engineering experiments on your AWS workloads, allowing you to observe how your applications respond to various failure scenarios. This proactive approach helps you improve your application’s reliability and availability before real incidents occur.
By combining AWS Fault Injection Service and Amazon Application Recovery Controller, you can build and validate resilient multi-Region architectures. This blog post shows you how to:
- Configure ARC Region switch for automated failover
- Create FIS experiments to simulate regional failures
- Monitor recovery dashboard using Synthetics Canary and CloudWatch
- Validate cross-Region resilience automatically
Prerequisites
-
- You’ll need an AWS account. If you don’t have one, you can create a new account.
- You’ll need any application that is in multi availability zones (AZ) and multi-Regions, and which is behind Application Load Balancer (ALB) and have configured AWS Auto Scaling Group (ASG) with database connection.
- Identity Access Management (IAM) permissions to access and manage Route 53 ARC, FIS and monitoring services such as Synthetic monitoring (canaries) and CloudWatch alarm.
- To configure ARC Routing Controls follow this blog post.
Application architecture – sample workload
Let’s take an example that demonstrates a highly available three-tier web architecture deployed across multiple AWS Regions.
Architecture Overview:
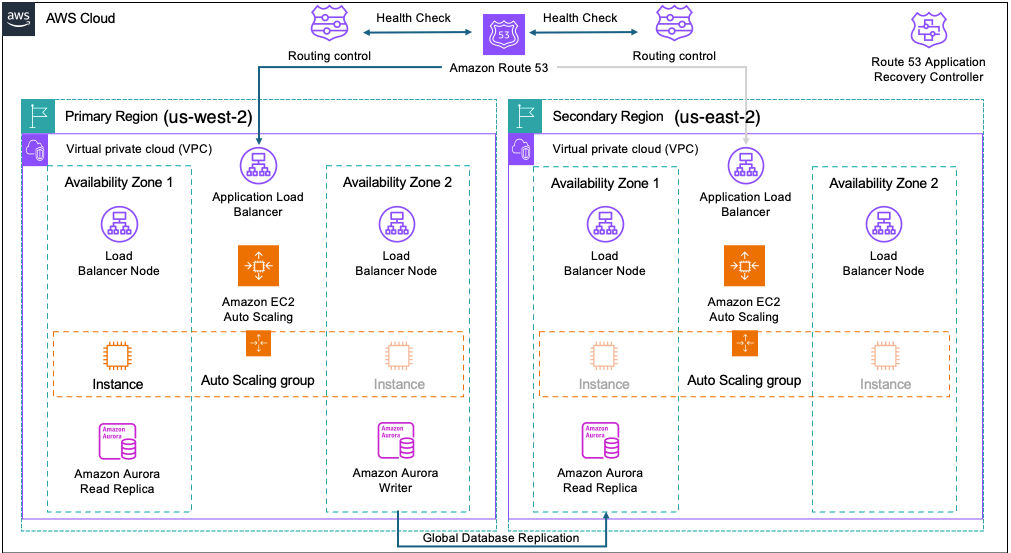 [Figure 1: multi-Region architecture with ARC]
[Figure 1: multi-Region architecture with ARC]
The solution discussed here consists of three main layers working together. The frontend layer uses Application Load Balancer distributed across multiple AZs and Regions, with Amazon Route 53 handling DNS routing. The application layer employs Auto Scaling groups of Elastic Compute Cloud (EC2) instances in two AZs, hosting the custom “ARC Demo” website application to demonstrate failover scenarios.
For the database layer, we utilize Amazon Aurora Global Database configured with a primary cluster and a writer instance in US West (Oregon), complemented by read replicas in both the primary Region for read scaling and US East (Ohio) for disaster recovery. This Active/Passive deployment model, with US West (Oregon) as primary and US East (Ohio) as secondary Region, provides high availability across AZs and Regions, automatic failover capabilities, scalable performance under varying workloads, and consistent data replication across Regions.
Solution Walkthrough
1. Verifying the primary website configuration
Let’s verify ARC Demo website’s current state before proceeding with failover testing. Accessing the website URL shows “Hello, World! PRIMARY REGION – Oregon”, confirming that traffic is being served from US West (Oregon) Region in Active mode. The website is configured in a Route 53 public hosted zone using failover routing policy and is associated with ARC routing control health checks. By default, when the routing control state is off for both US West (Oregon) and US East (Ohio) Regions, traffic routes to the primary record in US West (Oregon).
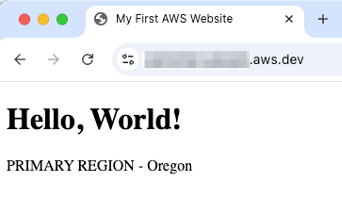 [Figure 2: ARC Demo website is serving from primary Region]
[Figure 2: ARC Demo website is serving from primary Region]
 [Figure 3: Routing controls for primary US West (Oregon) and US East (Ohio) Regions]
[Figure 3: Routing controls for primary US West (Oregon) and US East (Ohio) Regions]
2. Setting up Application Recovery Controller – Region switch plan
Amazon Application Recovery Controller (ARC) Region switch helps orchestrate application recovery across AWS Regions. In the AWS Management Console, navigate to ARC and create a new Region switch plan implementing an Active/Passive multi-Region recovery approach. This configuration specifies US West (Oregon) as primary Region and US East (Ohio) as standby Region, with a Recovery Time Objective (RTO) of 30 minutes. This RTO benchmark helps measure actual failover performance and optimize recovery procedures for business continuity.
 [Figure 4: Region switch plan]
[Figure 4: Region switch plan]
3. Designing regional failover workflow in ARC
Region switch workflows help orchestrate complex recovery tasks systematically across AWS Regions, allowing business continuity while reducing operational overhead. By automating and sequencing recovery actions, you can monitor progress and maintain control throughout the failover process.After confirming the Region switch plan is ready (indicated by a green evaluation status as shown in Figure 4), create a structured workflow using AWS Application Recovery Controller’s graphical design editor. This sequential execution flow allows a controlled and reliable regional transition.This workflow incorporates following key execution blocks:
- Auto Scaling Configuration: Enable 100% capacity matching in the activated Region
- Manual Approval: Implements manual verification with proper IAM permissions
- Aurora Global DB Management: Handles database switchover operations
- Route Control: Manages traffic flow between primary and secondary Regions
Each execution block is strategically sequenced to maintain application availability while minimizing potential disruptions during the failover process.
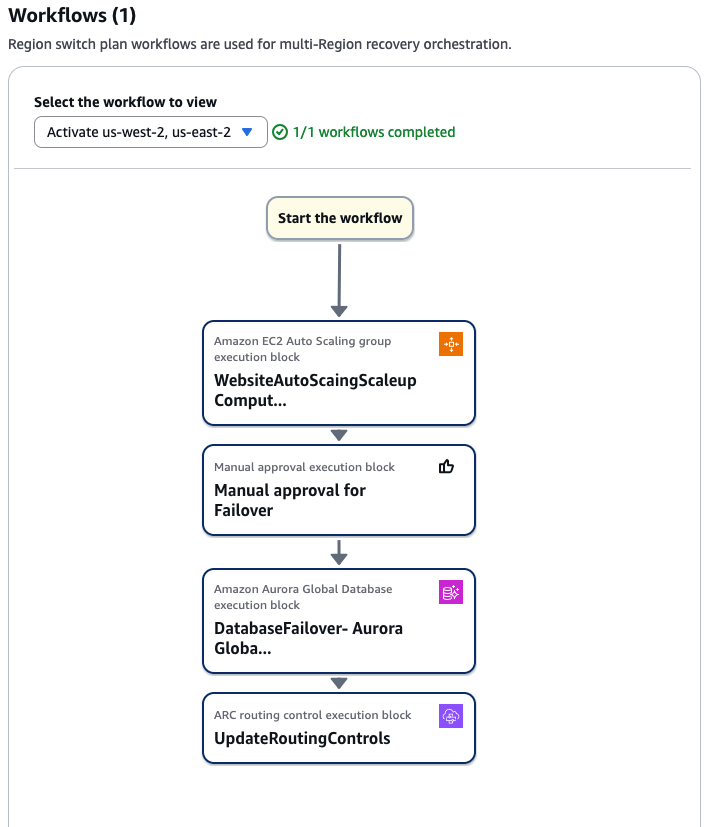 [Figure 5: Region switch plan workflow for multi-Region orchestration]
[Figure 5: Region switch plan workflow for multi-Region orchestration]
4.Proactive monitoring of website performance using AWS Synthetic canary
To enable automatic disaster recovery in ARC Region switch, we need monitoring metrics to configure the Region switch trigger. Implement “website-monitoring” AWS Synthetic canaries – automated scripts that regularly check website endpoint. These canaries act as virtual users, systematically testing this website across different browsers at scheduled intervals.
The canaries simulate real user interactions, following predefined paths that mirror actual customer behavior. This proactive monitoring approach helps detect potential issues before they impact users and allows reliable service delivery through continuous validation of the website functionality.
This monitoring setup includes:
- Regular canary tests confirming primary website health
- CloudWatch metric configuration for “Failed request” from website-monitoring canary
- Alarm trigger set to activate when failures are greater than or equal to 1 within 1 minute
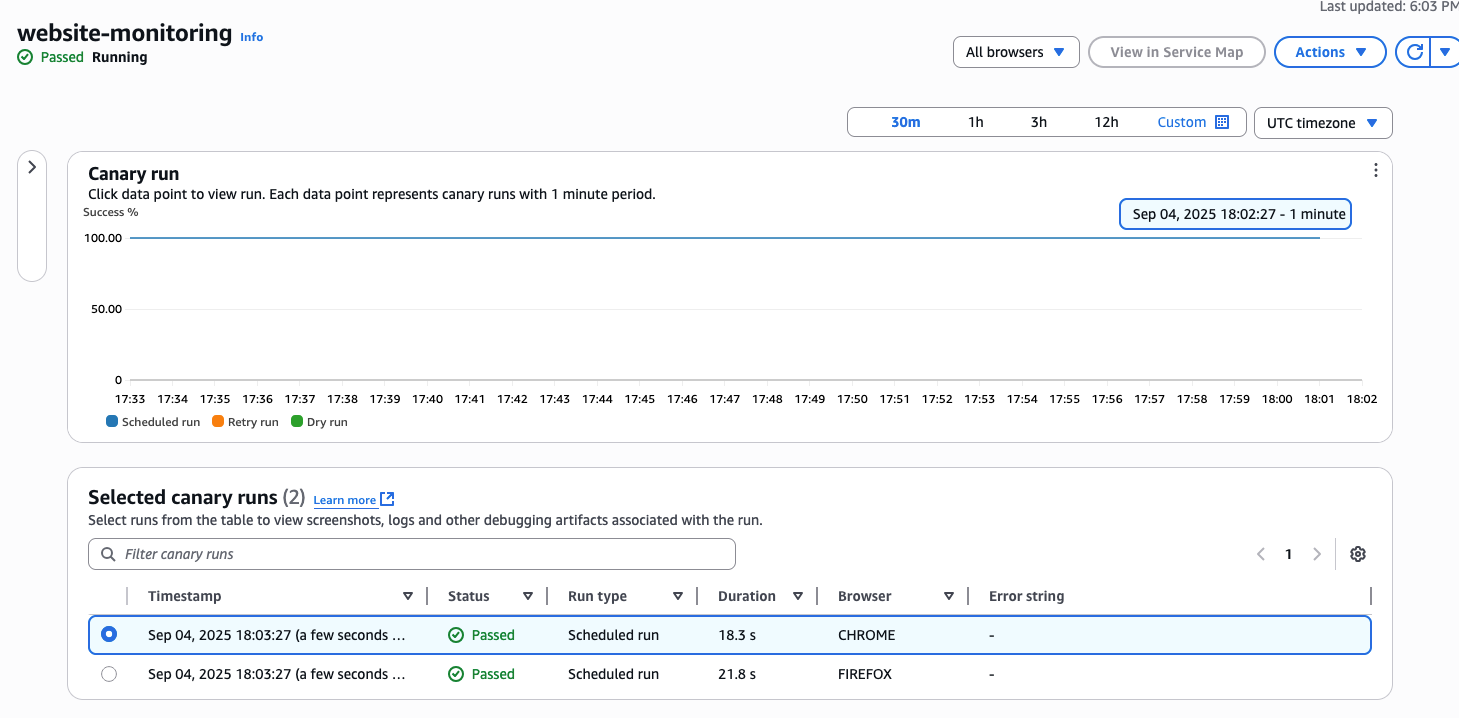 [Figure 6: Website-monitoring using Synthetic canary]
[Figure 6: Website-monitoring using Synthetic canary]
5.Automating recovery: configuring Region switch plan triggers
To enable automatic disaster recovery, we’ve integrated triggers into Region switch plan that respond to primary Region failures. The system uses website-monitoring Synthetic canary and CloudWatch alarms to detect outages. When the canary detects website unavailability and the CloudWatch alarm transitions to ALARM state, it automatically initiates the ARC Region switch plan.
This automated trigger mechanism enables rapid response to regional failures, eliminating manual intervention and reducing recovery time. The direct connection between monitoring and recovery procedures creates a seamless failover process that activates immediately upon detecting primary Region issues.
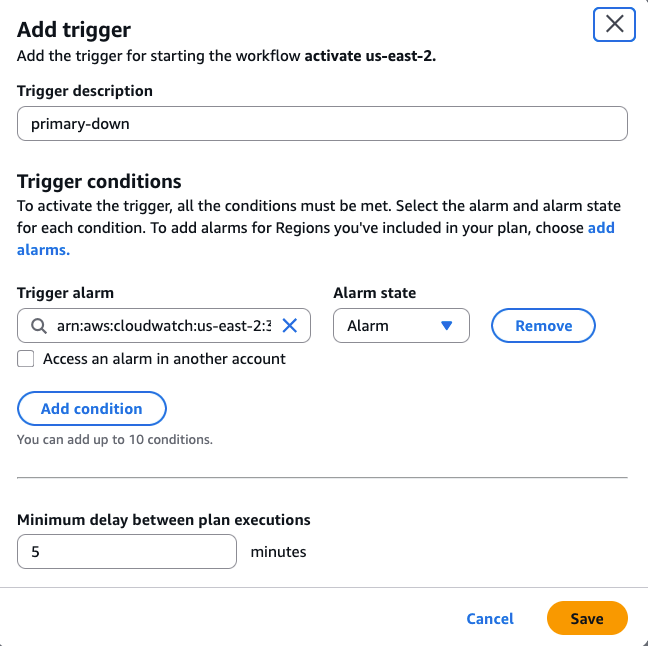 [Figure 7: Adding trigger in ARC Region switch]
[Figure 7: Adding trigger in ARC Region switch]
6. Simulating primary Region failure using AWS Fault Injection Simulator (FIS)
In this scenario, we use FIS to simulate a network impairment in the primary Region (US West). The experiment template is configured with the following specifications:
- Create an AWS FIS experiment template
- Fault action: aws:network:disrupt-connectivity
- Target resources in primary Region (US West):
- Application Load Balancer(ALB) public subnets
- EC2 webserver private subnets
This experiment denies specified traffic to the primary Region’s ALB and application subnets, simulating a regional impairment to validate the failover mechanisms.
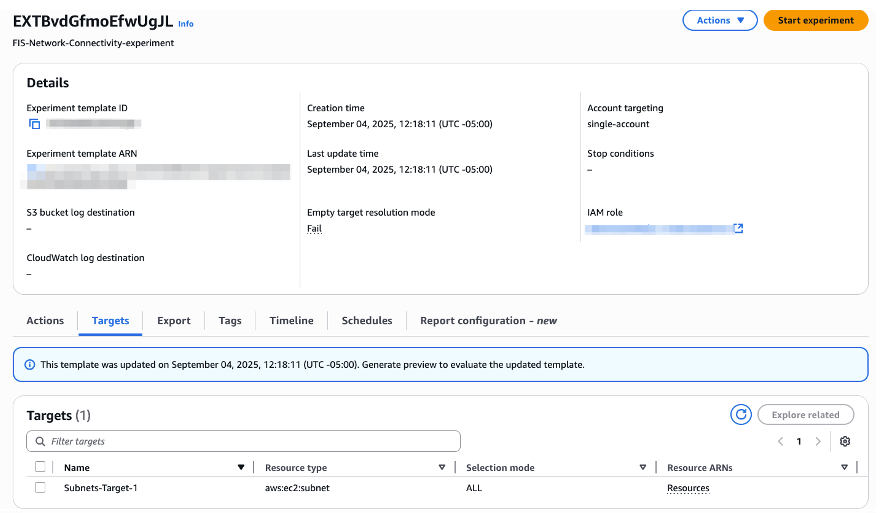 [Figure 8: FIS-Network-Connectivity-experiment]
[Figure 8: FIS-Network-Connectivity-experiment]
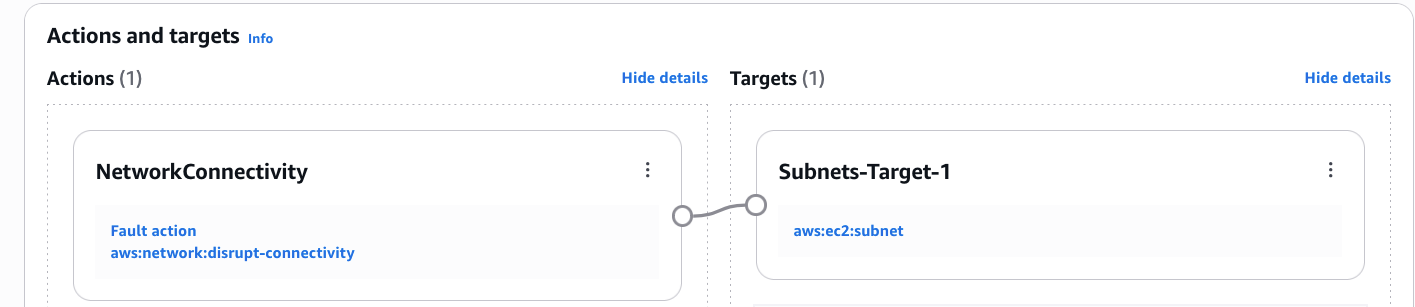 [Figure 9: FIS-Network-Connectivity-experiment action and target]
[Figure 9: FIS-Network-Connectivity-experiment action and target]
7. Detecting primary Region failure through synthetic monitoring
The Synthetic canary monitoring detected immediate impact when network connectivity was disrupted in the primary Region. The canary, which continuously monitors the ARC Demo website, reported failed requests, triggering a CloudWatch alarm that quickly transitioned to ALARM state.
This real-time monitoring response validates the Synthetic canary setup’s effectiveness in identifying regional outages. The transition from successful to failed canary tests confirmed that the primary Region was experiencing connectivity issues, requiring immediate failover action.
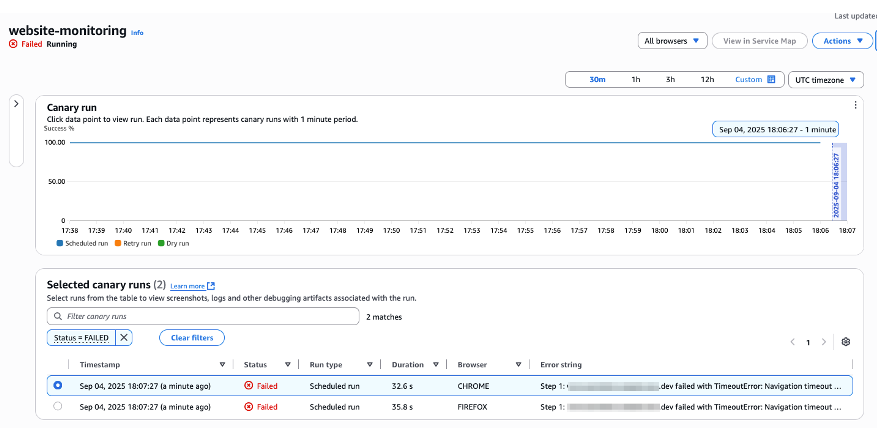 [Figure 10: Status checks of website using Canary dashboard]
[Figure 10: Status checks of website using Canary dashboard]
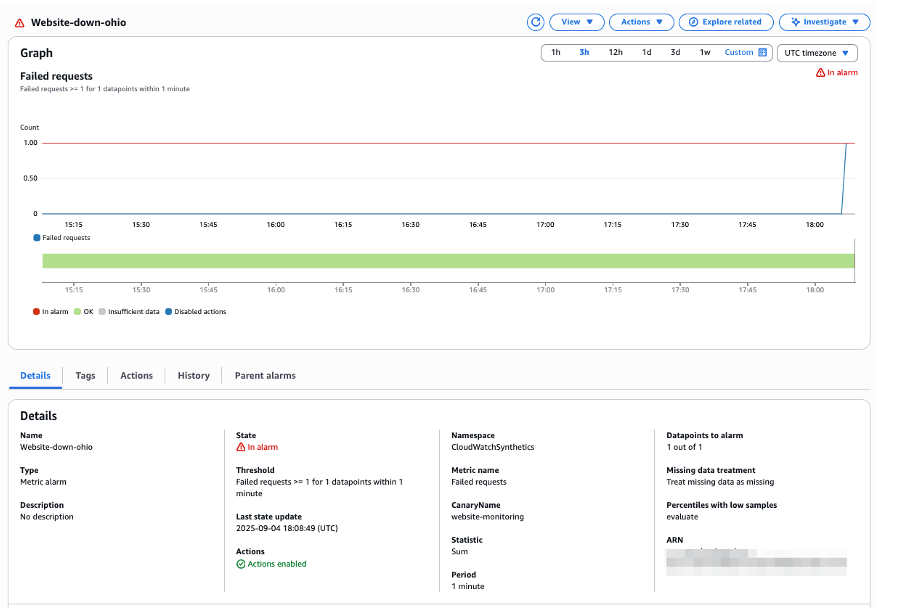
[Figure 11: CloudWatch alarm indicating primary site down]
8.Mitigating single Region failure using Amazon Route 53 ARC Region switch
The monitoring system detected an issue when CloudWatch entered ALARM state, automatically triggering the Region switch plan. The failover process is now executing as designed to restore service availability.
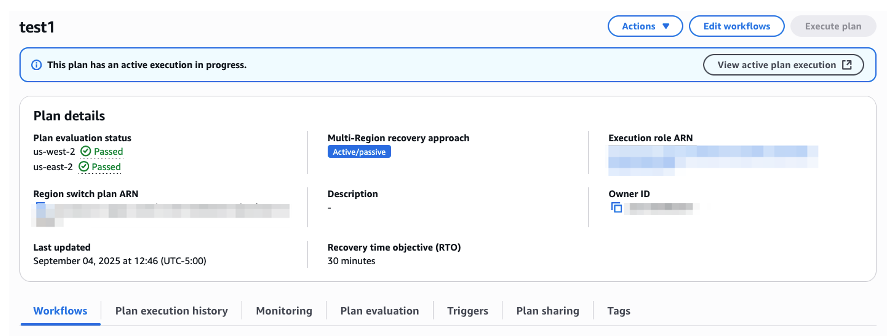 [Figure 12: Shows plan is active and in execution phase]
[Figure 12: Shows plan is active and in execution phase]
The failover sequence paused at the Manual Approval execution block. After monitoring confirmed the primary Region outage, the request to transition to the secondary Region approved, allowing the disaster recovery process to continue.
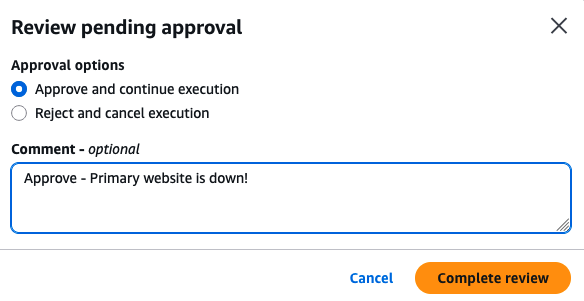 [Figure 13: Manual approval during failover]
[Figure 13: Manual approval during failover]
The Region switch execution completed successfully. The execution history confirms the process initiated through an automated trigger, validating that the automated disaster recovery system functions as designed.
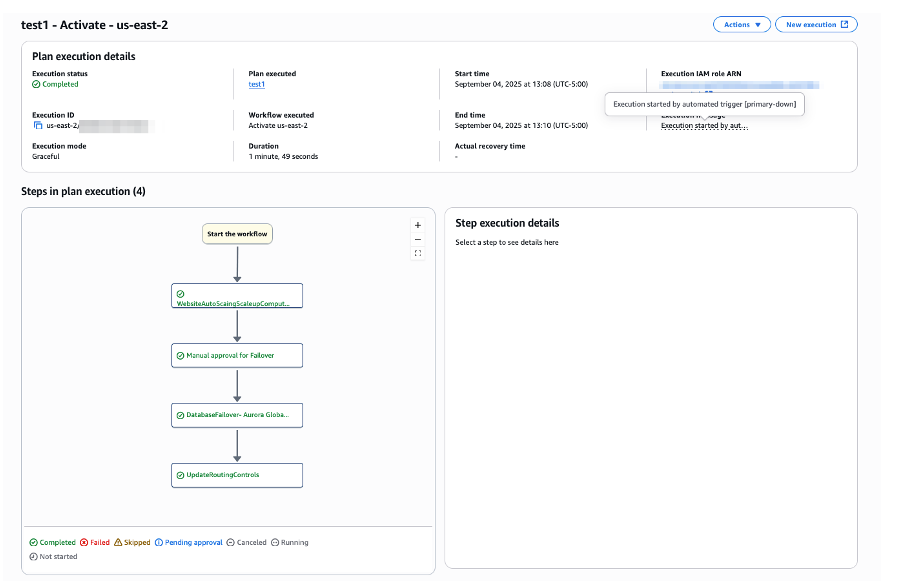 [Figure 14: Region switch execution results]
[Figure 14: Region switch execution results]
The final execution block automatically updated the routing control to ON state in ‘east’ successfully redirecting all traffic to secondary Region as shown in Figure 15.
 [Figure 15: Final routing control update]
[Figure 15: Final routing control update]
9. Confirming secondary Region activation
The ARC Demo website is now successfully serving traffic from secondary Region in US East (Ohio), confirming complete failover execution.
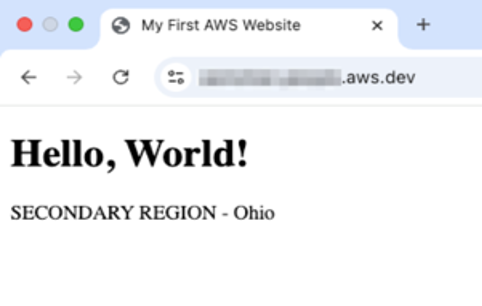 [Figure 16: Verifying secondary Region activation]
[Figure 16: Verifying secondary Region activation]
Clean Up
While Amazon Route 53 ARC is offered at no additional charge, the underlying AWS resources incur costs at their standard rates. To avoid ongoing charges, delete the Region switch plan, AWS Synthetic canary, CloudWatch alarms, FIS experiment template, Route 53 configurations, EC2 instances, Auto Scaling groups, Application Load Balancers, and Aurora Global Database clusters in both Regions. Finally, we recommend delete the role and associated permissions created for ARC and FIS. We recommend following these cleanup steps in reverse order of creation to allow proper resource dependency handling.
Conclusion
In this post, we demonstrated how to implement automated cross-Region failover using Amazon Route 53 Application Recovery Controller (ARC) with a traditional three-tier web architecture. By combining ARC Region switch with AWS Synthetic canaries and Fault Injection service, we created a robust disaster recovery solution that automatically detects and responds to regional failures.
This solution enables several key capabilities:
- Automated recovery with minimal disruption
- Real-time monitoring and failure detection
- Controlled failover orchestration
- Systematic testing of recovery procedures
The implementation showcases how ARC simplifies disaster recovery management while providing the flexibility to handle various scenarios, from performance degradation to planned maintenance. By following this approach, you can build resilient applications that maintain availability even during regional outages, helping business continuity and improved customer experience.To learn more about implementing and testing disaster recovery solutions with AWS services, refer to these resources:
- Getting Started with AWS Fault Injection Simulator
- Creating and Running FIS Experiments
- Cross-Region Failover Testing with FIS