Networking & Content Delivery
Extending NLB health checks for RADIUS using an Amazon ECS witness
Remote Authentication Dial-In User Service (RADIUS) underpins VPN access, 802.1X network admission control, Wi-Fi authentication, and identity services from vendors like Cisco Identity Services Engine (ISE), Aruba ClearPass, and Microsoft Network Policy Server (NPS). As you migrate these workloads to AWS, a gap in the load balancing layer becomes apparent: The Network Load Balancer (NLB), part of Elastic Load Balancing, supports TCP, HTTP, and HTTPS health checks against its target groups, but it doesn’t have an application-layer health check for RADIUS. For a UDP target group, the available health check options can validate transport-layer reachability, but not whether the RADIUS daemon can actually authenticate a user.
This post walks through an open source reference solution that extends an NLB with application-layer RADIUS health checks using a single Amazon Elastic Container Service (Amazon ECS) witness that performs RADIUS authentication probes and directly manages NLB target group membership, with AWS Secrets Manager for credential storage. The complete code is available in the sample-nlb-radius-witness repository on aws-samples.
The challenge: A UDP response doesn’t prove functionality
For identity workloads – VPN concentrators, Wi-Fi controllers, 802.1X switches – a RADIUS server that accepts packets but returns Access-Reject for every request continues to receive traffic. Clients receive authentication failures instead of failing over to a healthy peer, and end users are unable to authenticate.
Running RADIUS behind an NLB encounters three specific challenges:
- NLB health checks for UDP target groups are transport-layer. NLB doesn’t support UDP health checks. For a UDP target group, you must configure the health check protocol as TCP, HTTP, or HTTPS, which probes a listener on the target rather than the RADIUS service itself. These can confirm the instance is reachable. What they don’t confirm is that the RADIUS daemon can decrypt a shared secret, look up a user in its identity store, and return a valid response.
- Silent identity store failures are not surfaced by native health checks. RADIUS servers typically depend on downstream Active Directory, LDAP, or SQL backends. When that backend becomes unreachable, the RADIUS daemon stays up but every authentication fails. NLB keeps routing traffic to it.
- Regional or Zonal failover is manual. Without a signal that distinguishes “listening” from “answering correctly,” you can’t build automated failover between a primary and a secondary RADIUS fleet in a different .
This post draws from a real engagement migrating a Cisco ISE RADIUS authentication layer from on-premises to AWS, where the team encountered exactly this gap. Cisco delivers ISE as a vendor-managed virtual appliance. It’s distributed as an Amazon Elastic Compute Cloud (Amazon EC2) Amazon Machine Image (AMI). These appliances don’t provide shell-level rights to install custom software, agents, or witnesses on the appliance itself, and modifying the operating system can void vendor support. This pattern applies to enterprise authentication products from Cisco, Aruba, Microsoft, and other vendors, and it’s the reason an off-box probe is a viable approach. A solution that required code changes on the RADIUS server itself was not an option.
Previous state: Native NLB transport-layer health checks
Before implementing the witness, a typical AWS RADIUS deployment looks like Figure 1. Authentication clients (VPN concentrators, wireless LAN controllers, network clients and infrastructure) send RADIUS requests to an NLB, which distributes them across a target group of EC2 instances running the RADIUS service. Because NLB doesn’t support UDP health checks, one option for the UDP target group is a TCP, HTTP, or HTTPS health check pointed at a separate listening process on each target.
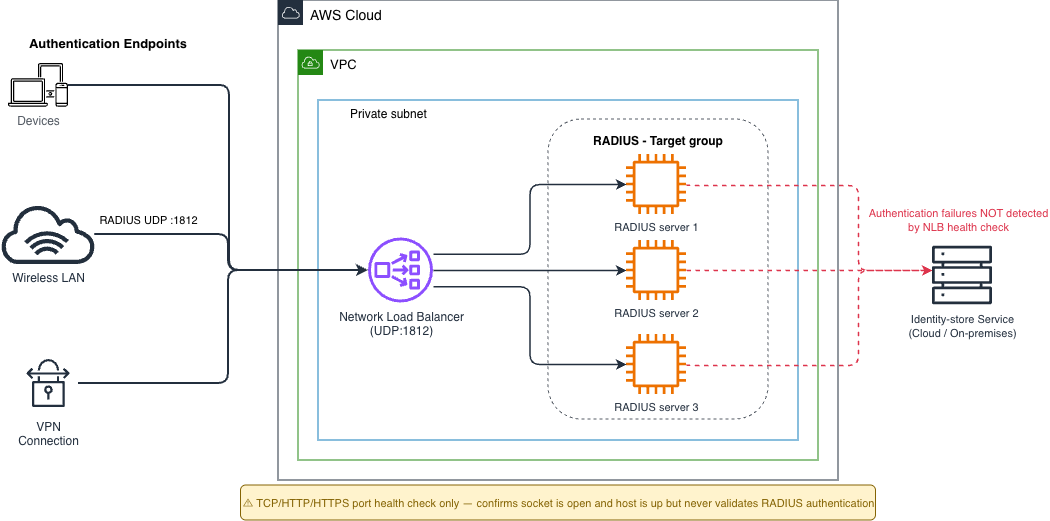
Figure 1: Previous state, NLB with transport-layer health checks for the UDP RADIUS target group
This design has two drawbacks: it confirms a TCP socket answers but never exercises the RADIUS authentication flow, so a partially failed server remains in rotation. And a RADIUS server that has lost its connection to its identity store still passes the health check. NLB does fail open natively when every registered target is unhealthy, and you can use target group health thresholds to trigger DNS failover and traffic fail-open at configurable counts of unhealthy targets. Those mechanisms operate on the count of unhealthy targets reported to NLB, so they cannot turn an identity store outage into an unhealthy signal in the first place.
This gap calls for a solution that performs real RADIUS probes, tracks state per server, and translates that state into NLB target group membership.
Current state: A single-process RADIUS witness
The reference solution adds one component alongside the existing RADIUS fleet, deliberately off the data path: a RADIUS health check witness running as an Amazon ECS task. The witness probes each RADIUS server and reconciles the NLB target group directly, registering healthy targets and deregistering unhealthy ones. Client RADIUS traffic continues to flow unchanged through the NLB to the RADIUS EC2 instances. The witness is non-blocking and decoupled from that data path, so a witness outage doesn’t interrupt authentication, it only stalls health-driven target group changes until the witness is back.
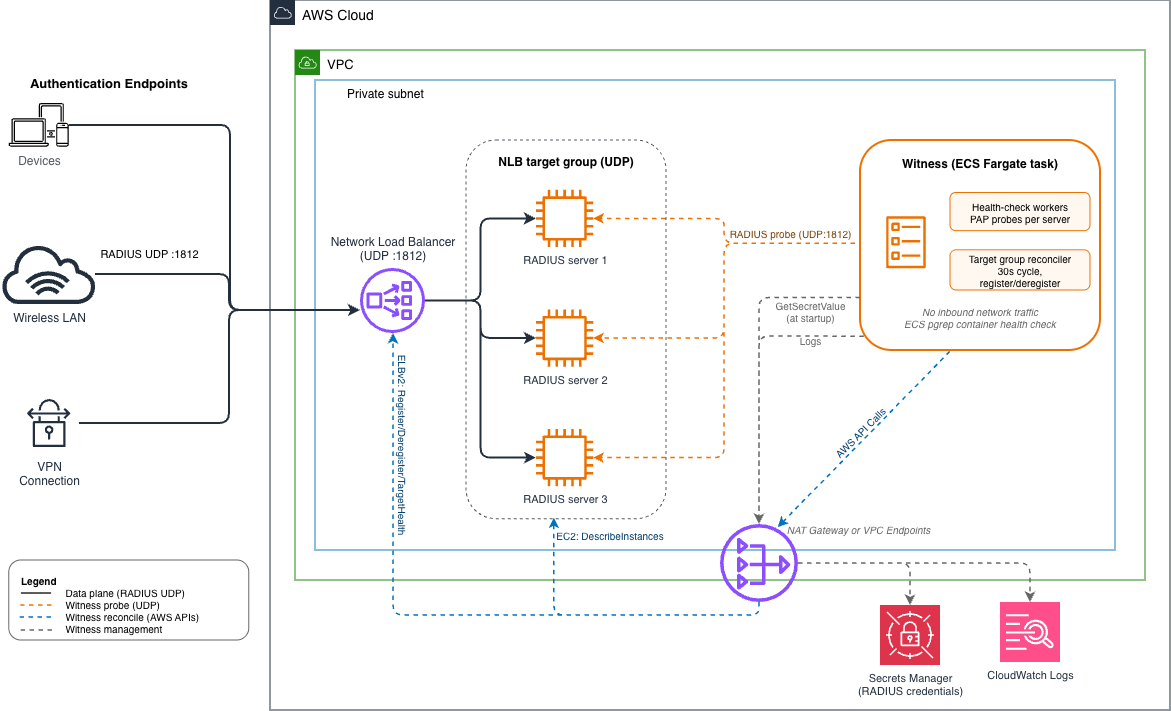
Figure 2: Current state, the witness runs alongside the RADIUS fleet, probes each server, and directly reconciles the NLB target group
The witness is a single Python process running in one container. Internally it has two cooperating components: a set of per-server health-check workers that run RADIUS Password Authentication Protocol (PAP) probes on a configurable interval, and a target group reconciler that translates the resulting health state into NLB register and deregister calls. Both share an in-memory health state store with a simple lock for safe concurrent access.
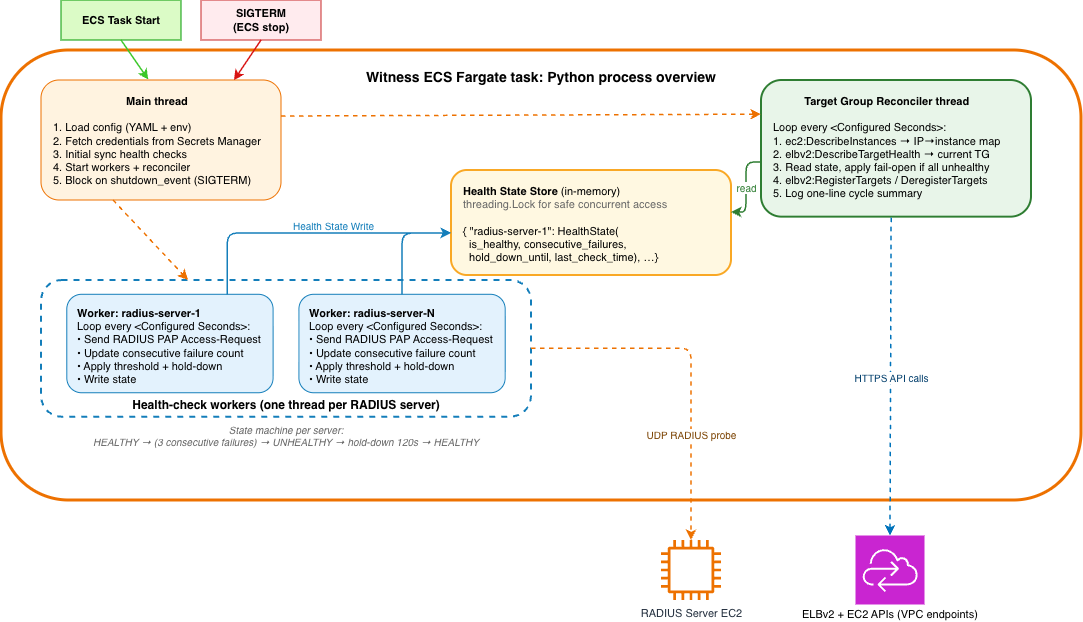
Figure 3: Internal threading model. Health-check workers and the reconciler share a thread-safe health state store. The reconciler calls EC2 and ELBv2 directly.
The witness: Real RADIUS probes with state
The witness is a Python application packaged as a container image and deployed as an Amazon ECS service. On startup it reads its configuration from either a YAML file or environment variables (environment variables take precedence) and retrieves RADIUS credentials – the shared secret, test username, and test password – from AWS Secrets Manager. For local development or air-gapped testing, a skip_secrets_manager flag allows you to inject credentials directly through environment variables. The approach generalizes: if you are using HashiCorp Vault, CyberArk, or another credential vault, you can swap the Secrets Manager client with your own implementation without touching the rest of the code.
For each configured RADIUS server, the witness spawns a worker thread that runs an authentication probe every 10 seconds (configurable). Each probe is a full PAP transaction: the worker encodes an Access-Request with the test credentials, signs it with the shared secret, sends it over UDP, and waits for the response. An Access-Accept marks the server healthy and an Access-Reject, timeout, or protocol error increments a failure counter.
Two state-machine features make the signal reliable enough to drive automation:
- Failure threshold. The witness marks a server unhealthy after a configurable number of consecutive failures (default 3). This absorbs transient packet loss without flapping.
- Hold-down timer. After a failed server recovers, it stays marked unhealthy for a stabilization period (default 120 seconds) before the reconciler returns it to the pool. This prevents rapid state changes during partial outages.
The witness also implements an explicit fail-open mode: if every configured RADIUS server is unhealthy, the reconciler treats each of them as effectively healthy for registration purposes. NLB itself fails open when every registered target is unhealthy, but that behavior only helps if the targets remain registered. Because the reconciler would otherwise deregister every unhealthy target, a fully-unhealthy state would keep the target group empty and stop traffic, rather than triggering the native fail-open behavior of the NLB. Fail-open keeps targets registered so the NLB continues forwarding traffic during a complete identity store outage, so that the downstream RADIUS servers surface the real error to clients and trigger well-understood client-side retry and failover logic. This is a business-risk decision rather than a purely technical one, and teams with stricter security postures, where authenticating against a degraded identity store is unacceptable, should disable this behavior and accept the hard failure. Make this decision explicitly in your security review.
The reconciler: From health state to NLB membership
The target group reconciler is a daemon thread inside the same witness process. It wakes every 30 seconds (configurable) and translates the in-memory health state into NLB target group membership. On each cycle it:
- Calls the Amazon EC2 API to map each configured RADIUS server’s private IP to its instance ID.
- Calls the Elastic Load Balancing v2 API to read the current target group registrations.
- For each server, decides whether to call RegisterTargets or DeregisterTargets based on the in-memory health state, with the fail-open override applied if every server is unhealthy.
- Logs a one-line cycle summary with healthy and unhealthy counts, current registration count, fail-open state, and any changes made.
Because the reconciler operates on observed state and is idempotent, it self-heals drift between the witness’s view and the configured targets of the NLB. If someone manually registers or removes a target, the next cycle restores the correct state within the reconcile interval.
Keeping the probe and the reconciliation in one process is deliberate. There is no event bus, no scheduled invocation, and no clock skew between “what the health checker saw” and “what the reconciler did about it.” The two components share the same memory, the same log stream, and the same lifecycle, which keeps the operational footprint small and makes the cause-and-effect chain easy to follow when debugging.
Integration strategy and deployment
The witness runs as a single-replica Amazon ECS task on AWS Fargate service in the same Amazon Virtual Private Cloud (Amazon VPC) as the RADIUS fleet, with no inbound network listener. Amazon ECS uses a process-based container health check (pgrep -f src.main) defined in the task definition, so no port is exposed. The task needs reachability to the RADIUS servers on UDP/1812 and outbound HTTPS to the AWS Secrets Manager, Amazon EC2, and Elastic Load Balancing v2 service endpoints (VPC endpoints recommended). The Amazon ECS task role consolidates the required permissions: secretsmanager:GetSecretValue scoped to the credentials secret ARN, elasticloadbalancing:RegisterTargets and DeregisterTargets scoped to the target group ARN, plus elasticloadbalancing:DescribeTargetHealth and ec2:DescribeInstances, which AWS requires at Resource: *.
The reference AWS CloudFormation template in the repository deploys the Amazon ECS service with DesiredCount:0 so the stack succeeds before an image exists in the created Amazon Elastic Container Registry (Amazon ECR) repository. After the stack completes, build and push the image to Amazon ECR, then, scale the service to one.
Credential handling
The witness retrieves RADIUS credentials from AWS Secrets Manager at startup and caches them in memory. The secret content is a JSON document with the shared secret, test username, and test password. Rotating credentials requires updating the secret and restarting the witness task, and a rolling update at the Amazon ECS service level handles this without operator intervention.
The reference solution uses AWS Secrets Manager instead of AWS Systems Manager Parameter Store SecureString primarily for its native rotation support: an AWS Lambda rotation function can rotate the RADIUS shared secret on a schedule and update the corresponding configuration on the appliance through its management API, without operator action. Parameter Store doesn’t provide a built-in rotation mechanism. For deployments that don’t need automated rotation, Parameter Store SecureString is functionally equivalent for static credential storage, supports the same encryption, policies, and VPC endpoint access, and is materially cheaper. If rotation isn’t a requirement, swap the SecretsManagerClient class for a Parameter Store client and reduce cost accordingly. If you have standardized on a different vault (HashiCorp Vault, CyberArk Conjur), you can replace the client class with your implementation.
Observability
The witness emits structured logs to stdout, collected by the awslogs driver and written to Amazon CloudWatch Logs. Every probe records the server name, duration, and outcome. Each reconciliation cycle emits a one-line summary with healthy and unhealthy counts, current target group size, fail-open state, and any register or deregister actions taken. Because health checks and reconciliation share a process and a log stream, you can correlate a probe failure with the resulting target deregistration without joining log groups.
The reference implementation emits structured logs, but doesn’t emit CloudWatch metrics directly. If you want first-class metrics, you can extend the witness with CloudWatch Embedded Metric Format (EMF) or push metrics through the aws-embedded-metrics library or boto3.client(“cloudwatch”).put_metric_data. The probe loop and the reconciler each have a natural place to emit per-server latency, success rate, and reconcile-lag metrics.
Results and considerations
In the engagement that inspired this pattern, the witness detected a RADIUS-to-Active-Directory backend failure within 30 seconds. The next reconciliation cycle deregistered the affected target from the NLB before any VPN clients received authentication failures. A native transport-layer health check would have kept the target in rotation indefinitely, since the RADIUS process kept its socket open even with the identity store down.
A few considerations to weigh before adopting this pattern:
- Operational surface. You are adding one Amazon ECS service to your environment. The witness is a few hundred lines of Python and an Amazon ECS task, but it still must be monitored, patched, and included in your deployment pipeline.
- Test credentials are real credentials. The witness uses a production RADIUS username and password to perform its probes. Provision a dedicated service account with the minimum permissions needed to authenticate and nothing else. Audit its usage.
- Fail-open is a policy decision. As discussed earlier, fail-open keeps traffic flowing during a total identity store outage at the cost of forwarding to servers that reject every request. Disable it if your security posture requires hard failure on loss of identity validation.
- Witness availability. The reference deployment runs a single witness task in a Multi-AZ Fargate service, so Amazon ECS replaces the task on host failure. Running multiple witnesses against the same target group at the same time isn’t recommended, since each instance would independently reconcile and might cause registration instability. If you need more than Amazon ECS task replacement provides, run a single active witness with a hot standby pattern, or shard servers across multiple witnesses with disjoint target groups.
- Protocol coverage. The sample implements PAP, which is sufficient for validating the RADIUS transaction even in production environments that use CHAP or EAP for real client traffic, since the health probe isn’t required to match the production authentication method. If your compliance regime requires a probe that uses the same method as production, you can extend the pyrad-based client to CHAP or MSCHAPv2.
Conclusion
NLB provides a high-performance load balancer for UDP workloads, but its health check model stops at the transport layer. For protocols like RADIUS, where “the socket answers” and “the service works” can diverge silently, that isn’t enough. The pattern in this post (a single RADIUS-speaking witness with built-in NLB target reconciliation, plus AWS Secrets Manager for credentials) closes the gap without replacing the NLB or introducing a third-party appliance. The witness code is open source, and the entire deployment fits inside a single VPC and one Amazon ECS service.
The same pattern generalizes to other protocols the NLB cannot natively health-check: LDAP, custom TCP protocols, custom UDP services. Replace the RADIUS client inside the witness with whatever probe your protocol requires, keep the reconciler as-is, and you have a reusable building block for application-layer health checks on an L4 load balancer.
Try it yourself, clone the sample-nlb-radius-witness repository, review the README.md and RADIUS_WITNESS_ARCHITECTURE.md files, and follow the deployment instructions. Contributions and issue reports are welcome.
To dive deeper on the AWS building blocks used in this solution, see the documentation for Network Load Balancer health checks and target group health settings, rotating secrets in AWS Secrets Manager, and running Amazon ECS tasks on AWS Fargate. For the design principles behind health-based failover, the Reliability Pillar of the AWS Well-Architected Framework covers the patterns this witness builds on.
About the author

Tim Franklin
Tim Franklin is a Senior Technical Account Manager with the Retail and Consumer Packaged Goods team at AWS Enterprise Support. He brings more than 20 years of IT experience across network engineering, product management, and DevOps. He focuses on networking and operational excellence, helping enterprise customers build and operate resilient, scalable architectures that stay available through peak demand.