Networking & Content Delivery
Host Single Page Applications (SPA) with Tiered TTLs on CloudFront and S3
Many of our customers use Amazon CloudFront and Amazon Simple Storage Service (Amazon S3) to deploy Single Page Applications (SPA): web applications created with React, Angular, Vue, etc. The development teams of these SPAs often have the following, seemingly conflicting, requirements:
- Users should experience as little latency as possible in downloading the web application. Therefore, the web application is cached at CloudFront edge locations near users. Furthermore, the web application is cached in the user’s browser, so returning visits are even quicker.
- Instant deploys. That is, they want to deploy their updated code and have users “see” the new version of the web application as soon as possible.
- They want to rely on Cache-Control HTTP headers instead of cache invalidations of their CDN (CloudFront in this case). Cache invalidations don’t affect the user browser’s cache, may incur additional costs (if beyond CloudFront’s free tier), and are a control plane operation with less availability guarantees than serving content with the right Cache-Control HTTP headers (data plane).
Can these seemingly conflicting requirements all be met at the same time? Yes, they can, by using versioning together with the right cache strategy using HTTP headers. In this post, we explain how to make that work for your web application with “tiered TTLs” (TTL, time-to-live: the maximum amount of time an object may be cached).
Architecture Overview
The following diagram illustrates the architecture at a high level. The web application files are stored in an S3 bucket that is served by CloudFront. Both CloudFront edge locations and the user’s browser may have stored a cached version of these files:
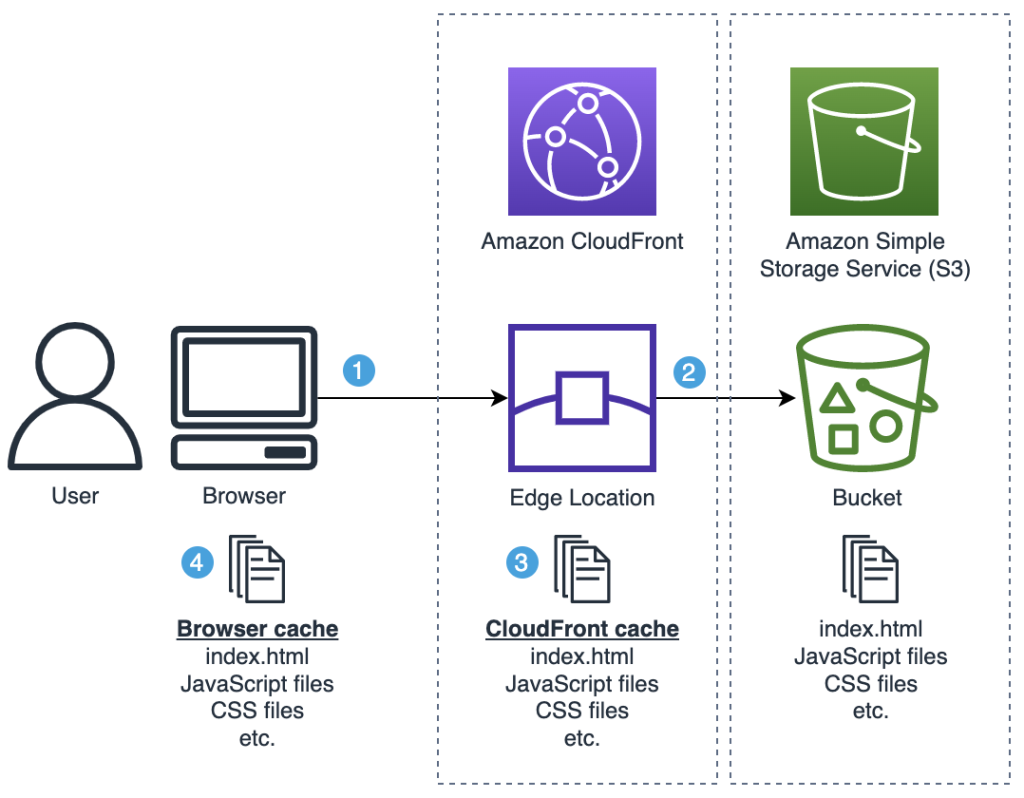
Diagram 1: Situation overview
Here’s a high-level explanation of that diagram (we’ll dive into the details later):
- User requests the SPA by opening the URL in their web browser. This request is served from the CloudFront edge location that is closest to the user.
- The CloudFront edge location requests the SPA files from S3.
- The CloudFront edge location caches the SPA files received from S3 and returns the files to the user’s browser.
- The user’s browser caches the SPA files received from CloudFront and renders the web application to the user.
We’ll show how to implement tiered TTLs first to cater to readers with haste, then we’ll dive deep into the “why” behind this in the remainder of this post.
Implementing tiered TTLs for your SPA
There are two things we must do:
- Specify the right cache-control attribute as object metadata on our web application files in Amazon S3: a short TTL for
index.html, and a long TTL for immutable assets, e.g. JavaScript and CSS. This object metadata field is used by CloudFront and returned to the user’s browsers in the HTTP response headercache-control. Here’s the cache settings to use, that we’ll explain later this post:- Immutable assets, e.g. JavaScript and CSS files:
public,max-age=31536000,immutable(“cache one year, then revalidate”) index.html:public,max-age=60(“cache 60 seconds, then revalidate”),stale-while-revalidate=2592000(“serve expired cached versions for max 30 days, while you revalidate the content in the background”)
- Immutable assets, e.g. JavaScript and CSS files:
- Make sure that the CloudFront cache policy we’re using allows both small TTLs (such as one second) and large TTLs (e.g. 31536000 seconds = 1 year), so that CloudFront doesn’t cap the TTLs that you set in the max-age cache-control directives on your S3 objects. Choose for example cache policy
Managed-CachingOptimized.
Uploading your files to Amazon S3 with the right cache-control object metadata
You could upload files manually in the AWS Console and set the cache-control object metadata while there. Here’s how to do it with the AWS CLI, where you could do this as part of your continuous integration/continuous development (CI/CD) pipelines:
# Use a short TTL for index.html:
aws s3 cp <sourcedir>/index.html s3://<bucketname> --cache-control 'public,max-age=60,stale-while-revalidate=2592000'
# Use a long TTL for immutable assets, e.g. JavaScript and CSS:
aws s3 cp <sourcedir>/bundle.hash778.js s3://<bucketname> --cache-control 'public,max-age=31536000,immutable'
aws s3 cp <sourcedir>/styles.hash631.css s3://<bucketname> --cache-control 'public,max-age=31536000,immutable'
We upload each file like that, instead of using aws s3 sync <sourcedir> <s3bucketname>, so that we can differentiate the cache settings per file type. For the same reason, we don’t use the CDK aws_s3_deployment module (it uses aws s3 sync under the hood).
Since typing out this AWS CLI command can be tedious, especially if your app has more files, you could use e.g. the following (third party) open-source NodeJS script: s3-spa-upload. This script uploads a directory that you specify to Amazon S3, and sets the cache-control headers on each file as mentioned above (it sets the Content-Type too, as an added benefit):
npx s3-spa-upload <sourcedir> <s3bucketname>For example, on my React Vite projects, I first run npm run build, which creates a directory dist with all of my application’s files: index.html, bundled JavaScript files, CSS files, etc. Then, I run:
npx s3-spa-upload dist my-bucket-nameOptionally, you can specify --delete, which would also remove old files from Amazon S3 (after it finished uploading new ones). You must do this clean up one way or the other, otherwise old versions would pile up indefinitely.
npx s3-spa-upload dist my-bucket-name --deleteNote that this will delete all of the files present in the S3 bucket that aren’t part of the current upload. Use with caution, as you may want to use a more fine-grained solution.
That’s it, that’s all there is to it! Your files are now on Amazon S3 with the right cache-control headers. CloudFront and the user’s browsers will respect these. No more cache invalidations needed! Read on to understand why this actually works.
Why tiered TTLs optimize caching for your SPAs
To understand the use of tiered TTLs, we must first understand how object versioning works with CloudFront.
Common versioning for SPAs
Versioning simply means that any time you make a change to a file, you use a different filename for it. For example:
- Let’s say you host a JavaScript file on CloudFront:
mycode-v1.js. - Now if you want to change that file, you wouldn’t actually change that file, but rather copy it to a new filename
mycode-v2.js, and then make the changes in that new file. - In this case, CloudFront would serve both files, although you could remove the old one if you wanted to.
This method makes caching easy, as each distinct file (version) can be cached forever. Said differently, each version is immutable. There is a downside to this: your users must know when to “switch” to the new filename.
Let’s discuss how this is often solved. Many SPA build tools implement versioning as just described: every time your source code changes and you build a new distribution of the SPA, new JavaScript and CSS files are generated with new, unique filenames (using hashes based on their contents, e.g. index-ae387ba8.js). Now the trick is that the “root” file that users actually access is index.html, and that filename doesn’t change. For example, when a user navigates to https://mysite.cloudfront.net they will actually download index.html (which is often used as the default root object for a CloudFront distribution). The index.html file contains links to all of the required JavaScript and CSS files that it needs; the SPA build tool has updated all referenced filenames to the latest version. Your users don’t have to worry about this, they download index.html, and let their web browser parse its contents and download the right JavaScript and CSS files.
Tiered TTLs for your SPA
After reading this object versioning outline, you can understand that the following caching strategy with “tiered TTLs” makes a lot of sense:
- JavaScript and CSS files:
public,max-age=31536000,immutable(“cache one year, then revalidate”) index.html:public,max-age=60(“cache 60 seconds, then revalidate”)
Notes:
- To “revalidate” means: check with the origin if the cached version is still the latest version. If there’s a newer version, then download that, otherwise use the cached version. Technically, this works using HTTP Conditional requests (described in the next section).
- Strictly speaking this is not “instant” deploy, but rather after (at most) 60 seconds. This is instant enough for most use cases, and you trade that for better CloudFront edge cache utilization – and a reduced number of requests to your Amazon S3 origin. If you want, you could of course go lower than 60 seconds, but if you set
max-ageto0that would disable request collapsing (see Simultaneous requests for the same object).
This simple caching strategy is effective for many use cases. The upside is that it doesn’t require any cache invalidations. Every time you deploy a new version of your web application, within 60 seconds your users will “see” that new version when they navigate to your web application’s URL: both CloudFront and the user’s browser will revalidate index.html as they both respect the cache instructions.
HTTP conditional requests
Objects that you upload to Amazon S3 will get an ETag from Amazon S3 automatically. The ETag is a unique identifier for that version of the object, for example: 9ee3d9fdce32d3387f822383bf960027. The ETag comes into play when your browser requests a file from CloudFront that it already downloaded before and has in its cache but has expired. In turn, your browser will issue a new HTTP GET request for the file to CloudFront, while passing the HTTP header if-none-match with the ETag as header value. This is called a revalidation, or conditional request.
If CloudFront determines that the ETag for that file didn’t change, then it won’t actually send the file back. Instead, it will send back an empty response with the status code 304 Not modified. It’s as if your browser told CloudFront: “please give me the contents of this file, but don’t bother if its current ETag is the same as the one that I’m sending you now, because that’s the ETag of the version that I already have in my cache”. This same mechanism is also used between CloudFront and Amazon S3.
Therefore, even if your browser revalidates a file from CloudFront, it may be very quick, as it doesn’t necessarily require the file to be transferred over the internet again––in the case that ETags still match. However, it still makes sense to set the right cache-control HTTP headers to prevent your browser from doing that revalidation. This is still an HTTP fetch after all. The quickest HTTP fetch is the HTTP fetch that your browser doesn’t have to do.
s-maxage
Besides max-age origins may also specify s-maxage and for completeness we must mention it in this post. The s-maxage directive is ignored by browsers but used by all shared caches, such as CloudFront, and overrules maxage for shared caches. Thus, you can use different cache settings for browsers than shared caches. Often, you would use a higher s-maxage because shared caches may be under your control (CloudFront) and you can trigger cache invalidation for them. However, this post is about a strategy to make cache invalidations unnecessary, and therefore we don’t use s-maxage.
Sequence diagrams
Let’s reiterate the explanations so far by looking at sequence diagrams for some concrete scenarios.
Scenario: Initial cache population
Here’s what it looks like for the first user to access your web application. For the sake of simplicity, we’ll pretend that index.html only links to one additional file (a JavaScript bundle):
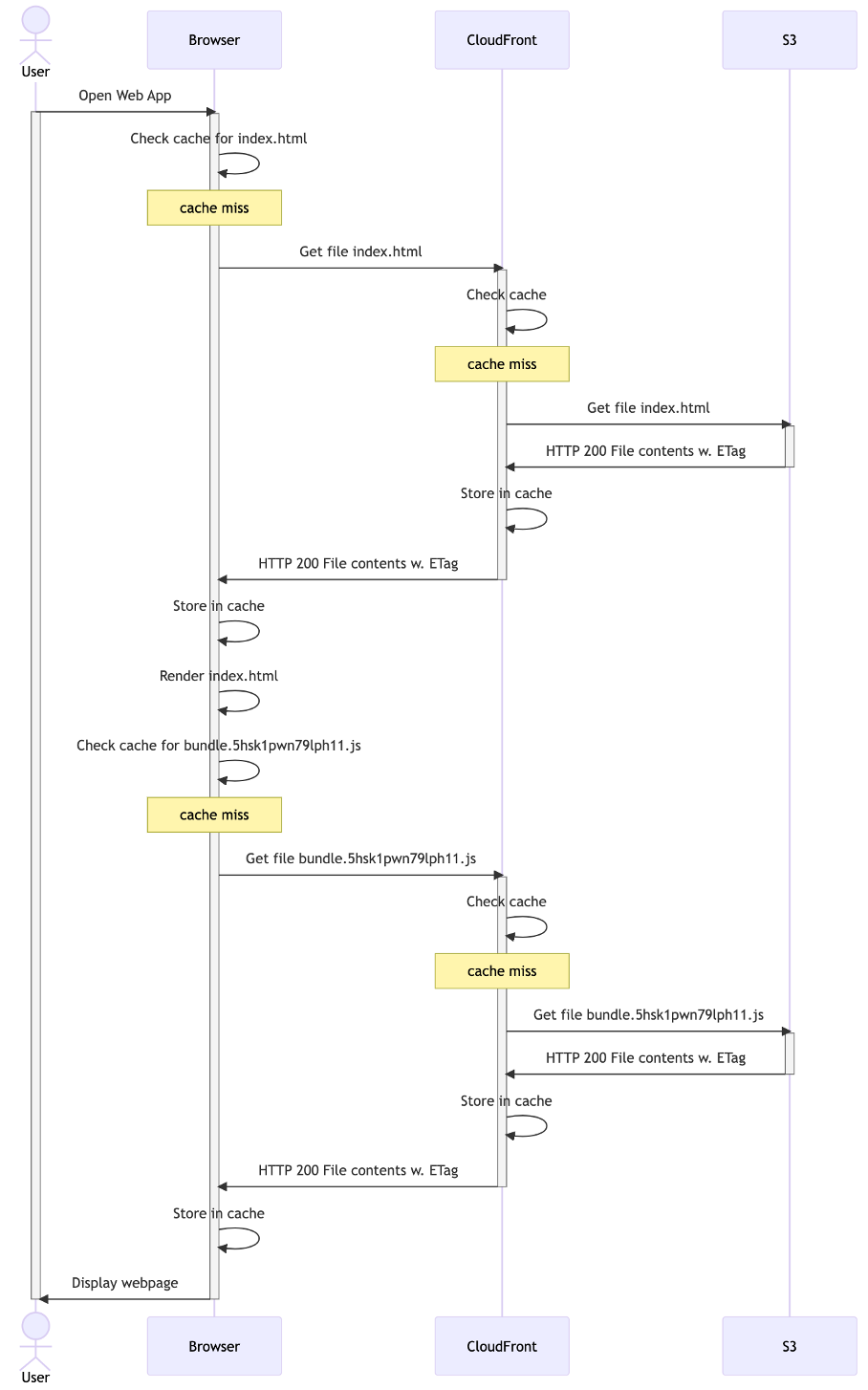
Diagram 2: initial cache population
Scenario: Returning visitor
Here’s what it looks like if that same user visits your website again. The index.html file will be revalidated (because of the short TTL: max-age: 60). However, because it’s unchanged on Amazon S3, it doesn’t actually need to be downloaded. The JavaScript bundle that’s in the browser’s cache is still valid (because of the long TTL: max-age: 31536000) and doesn’t need to be revalidated:
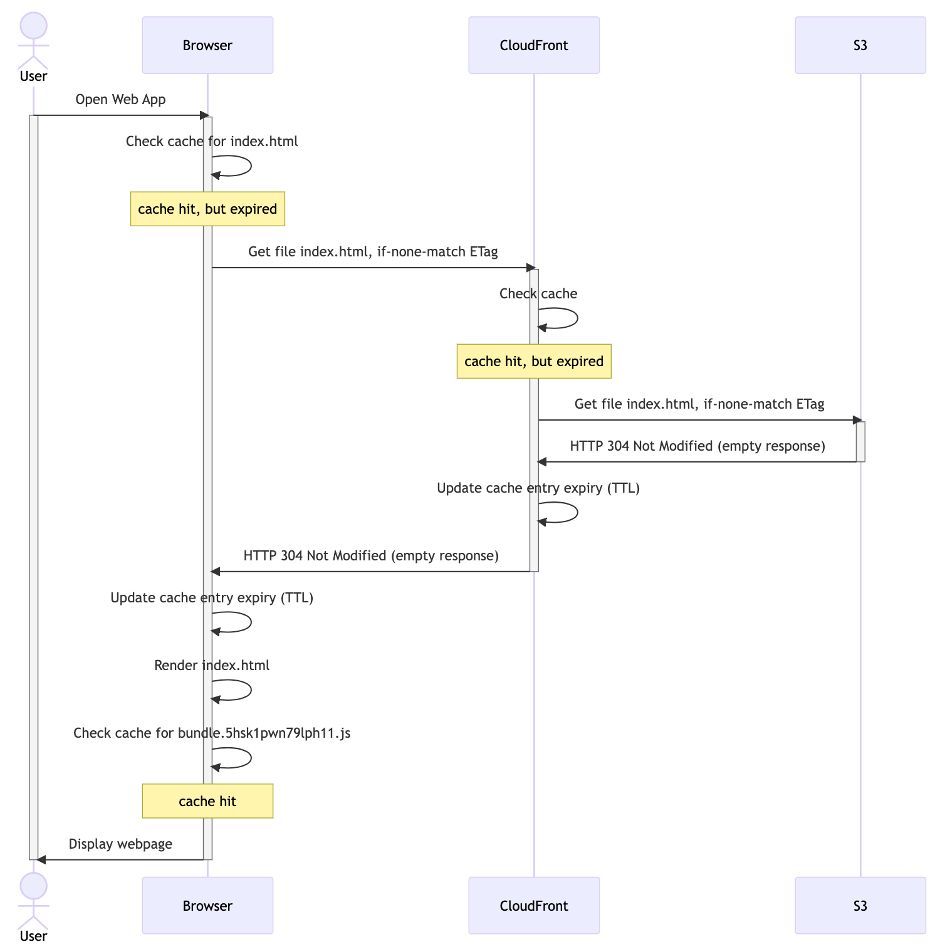
Diagram 3: returning visitor
Scenario: New visitor
If a new user visits your website, then they’ll have to download all of the files. CloudFront might revalidate index.html that it cached before (unless yet another user made CloudFront do this less than 60 seconds ago), but it can serve the JavaScript bundle directly from its cache:
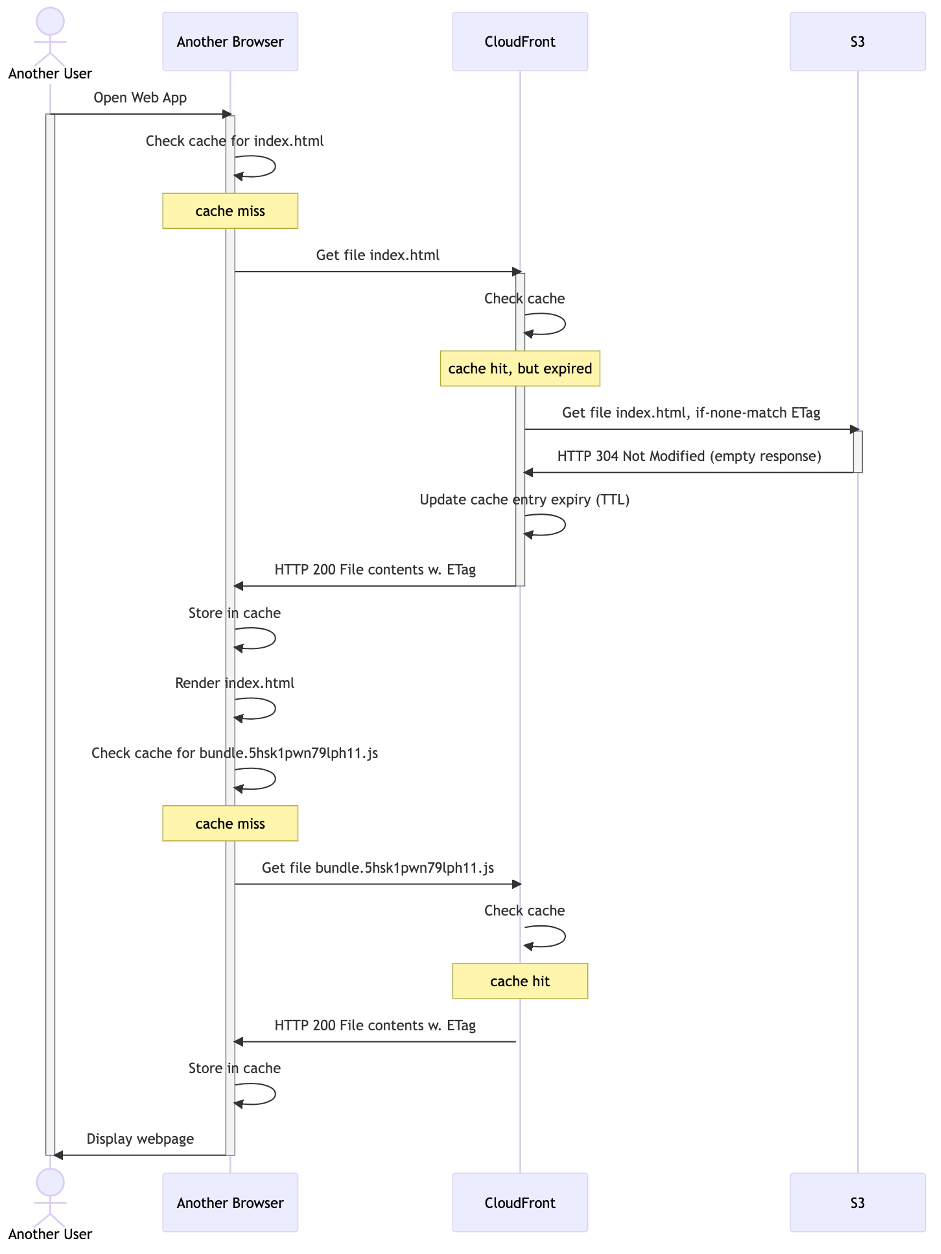
Diagram 4: new visitor
Scenario: Update of web application to v2
Here’s what happens if you upload a new version of your web application. Because index.html is revalidated (after 60 seconds), and it’s ETag now changed, it will be downloaded. This index.html points to a different JavaScript bundle that will also be downloaded. Therefore, this is an example of “instant deploys”:
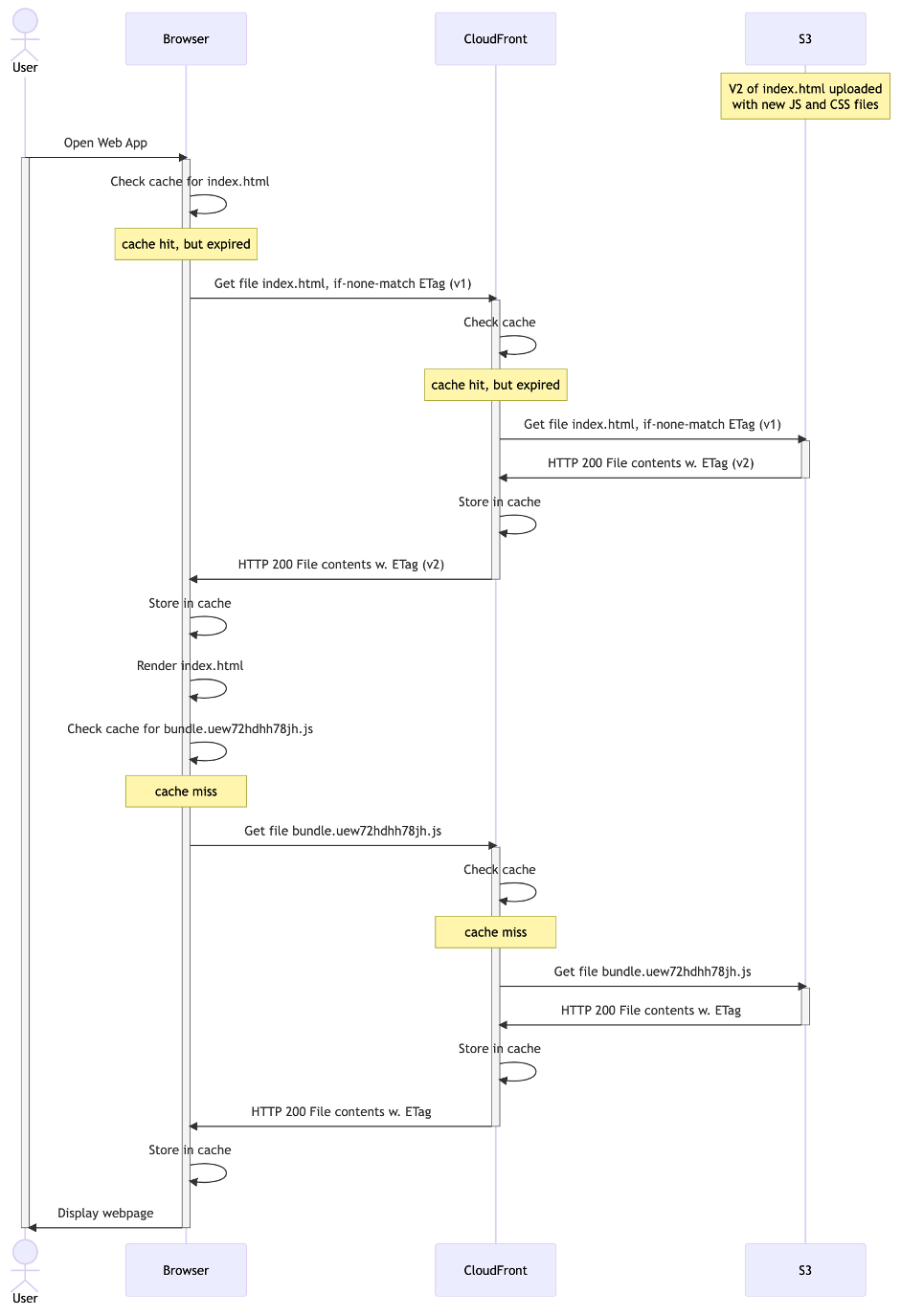
Diagram 5: instant deployment
Adding stale-while-revalidate
A potential improvement to the caching strategy described here is to also specify the stale-while-revalidate directive for index.html. This tells the cache at hand (be that CloudFront or the user’s browser) that the file may be used beyond the passage of time specified by max-age, for the duration of the stale-while-revalidate window. This is provided that the cache revalidates the file against the origin in the background (i.e. download the new version if any). Hence the name stale-while-revalidate: use a stale version of the file while you revalidate in the background. Then, if the user would request that same file again later, the cache could immediately serve that refreshed version of it that it downloaded in the background.
Updated cache settings (update in bold):
- JavaScript and CSS files:
public,max-age=31536000,immutable(“cache one year, then revalidate”) index.html:public,max-age=60(“cache 60 seconds, then revalidate”), stale-while-revalidate=2592000 (“serve expired cached versions for max 30 days, while you revalidate the content in the background”)
Concretely, this means that any latency in downloading a new version of the file is hidden from the user, and the user would simply get the old version of the file from the cache instead. This may be a nice trade-off for you between low latency and instant deploys: latency isn’t perceivable to the client (they use the cached version, from their local browser cache). Furthermore, the next time that they request the file (such as when they refresh the page) their browser will show the new version immediately, as it had downloaded it already in the background. Essentially, your users are never waiting for page downloads. Unless, of course, they are repeatedly pressing the refresh button, or they have disabled their local cache. But that’s not users, that’s developers – it’s probably you. (And note that such parallel requests would be collapsed by CloudFront: CloudFront will only reach out to your origin once)
stale-while-revalidate is also useful to “hide” latency for revalidations between CloudFront and your origin. Let’s take for example a user near Sydney, Australia. If your S3 bucket resides in Dublin, Ireland, then the CloudFront Sydney Edge cache will have to make a long roundtrip across half the world, to revalidate the files for the user. Even though that network traffic traverses AWS’ high-speed network, the speed of light is finite, and latency is unavoidable. With stale-while-revalidate, this latency can be effectively hidden from users, because downloads happen in the background.
Conclusion: using stale-while-revalidate works well for content that needs to be refreshed, but having the latest version immediately is non-essential. This is the case for many SPAs, and hence this post. We recommend implementing stale-while-revalidate after careful consideration of the nature of the content and the request patterns at play. Do not use stale-while-revalidate for content whose updates must be reflected immediately. For example, for an API that returns real time inventory data where the most recent available stock is required, or when you have to render user specific content like an account balance that needs to be accurate. For content that never or seldomly changes, you should opt for a large maxage, to prevent unnecessary background network requests that stale-while-revalidate would induce.
Let’s see how adding stale-while-revalidate changes our sequence diagrams.
Scenario: Update of web application to v2 with stale-while-revalidate
When a returning user visits your web application, they’ll get the old version immediately from the browser cache. This will trigger the user’s browser, and subsequently CloudFront, to revalidate. This looks as follows (assuming the 60 second TTL on index.html has lapsed, and that a similar request from another user already made CloudFront cache V2):
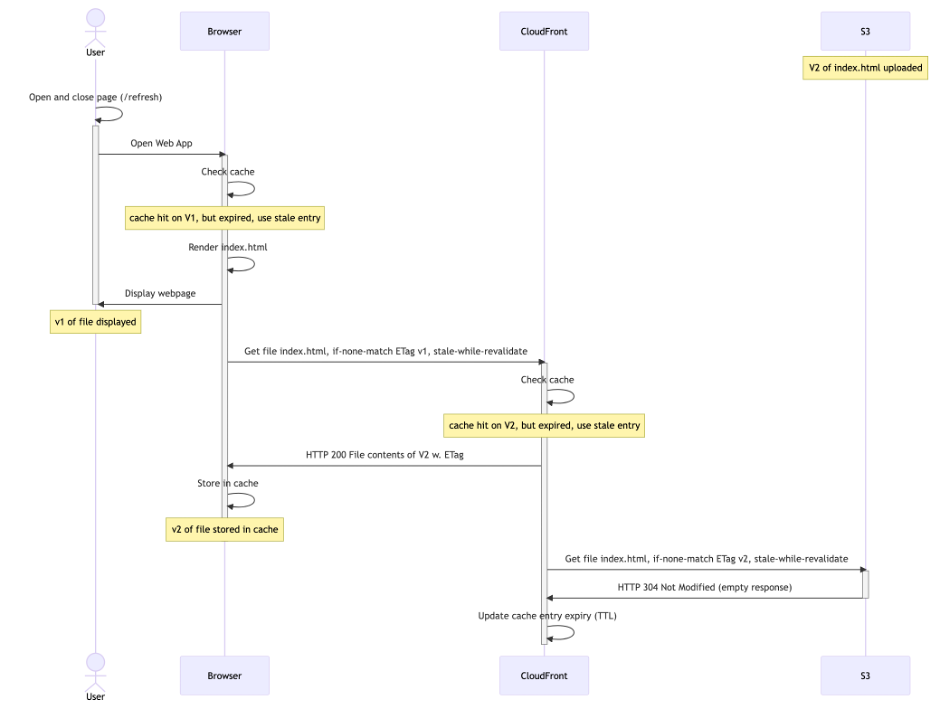
Diagram 6: stale-while-revalidate first request
The user’s browser cache has now been updated to v2 in the background, but your user is still viewing v1. Only on the next request would the user see v2 (again triggering a revalidation in the background, after 60 seconds):
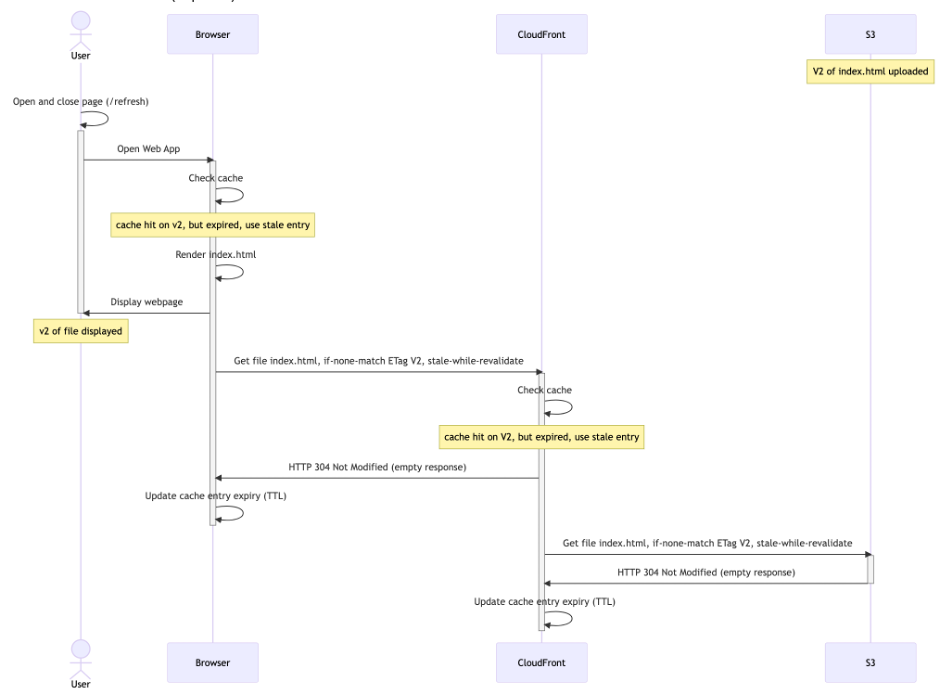
Diagram 7: stale-while-revalidate second request
In conclusion, because of stale-while-revalidate, it will now take one additional request for the user to see V2. The upside is that the user never has to wait for downloading (or revalidating) index.html.
Requiring this additional request for users to see the latest version of your web application may be an undesirable effect for you. However, it’s something you already had to think about. How were you deploying a new version of your web application to users that kept it running indefinitely in a browser tab that they never close? Were you already counting on them to (eventually) explicitly refresh the page to get the latest version? You can solve this automatically if you decide that it’s important enough, but that’s beyond the scope of this post.
Summary
In this post we explored a caching strategy for web applications, which caches using tiered TTLs. This offers developers the ability to deploy new versions of the code without having to do cache invalidations. It boils down to using object versioning together with the right cache strategy using HTTP headers. We added the stale-while-revalidate cache directive, to achieve a low latency for downloading new versions of the SPA.
Call to action
- Implement tiered TTL’s for your SPAs by using a short TTL (e.g.
max-age: 60) forindex.htmland longer TTLs for immutable assets, such as JavaScript and CSS files. Many SPA build tools support this, because they generate new filenames for JavaScript and CSS files upon changes to the source code. If you’re looking for a good tool to start building an SPA, use Vite. - Make sure you use a CloudFront cache policy that allows long TTLs, for example:
Managed-CachingOptimized. - Use the
stale-while-revalidatecache directive, to achieve a low latency for downloading files. Use it in those cases, where having users download the latest version of the files immediately is not essential. For many SPAs this is the case. - Use the NodeJS script mentioned in this post to upload your SPA with the right cache-headers to S3, or build something similar yourself now that you understand the pattern.

Otto Kruse
Otto Kruse is a Senior Solutions Developer within AWS Industries – Prototyping and Customer Engineering (PACE), a multi-disciplinary team dedicated to helping large companies utilize the potential of the AWS cloud by exploring and implementing innovative ideas. Otto focuses on application development and security.