AWS Open Source Blog
How Netflix uses Deep Java Library (DJL) for distributed deep learning inference in real-time
This post was written by Stanislav Kirdey, Lan Qing, Lai Wei, and Lu Huang.
Netflix is one of the world’s largest entertainment services with over 260 million members in more than 190 countries. One of the ways Netflix is able to sustain a high-quality customer experience is by employing deep learning models in the observability and monitoring space, specifically in observability of system and application logs (not user data) to help improve the customer experience. The Netflix observability team uses deep learning to automatically analyze and cluster gigabytes of log lines coming from various microservices in real-time.
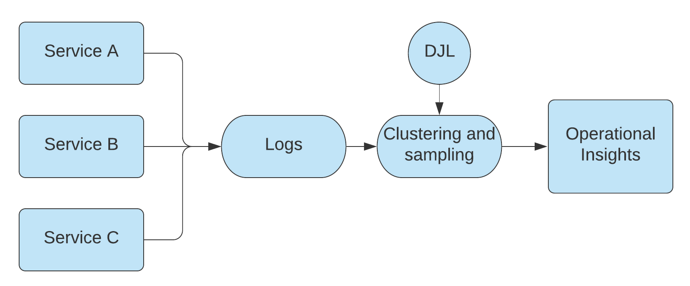
In this article, we’ll walk through how the observability team at Netflix uses Deep Java Library (DJL), an open source, deep learning toolkit for Java, to deploy transfer learning models in production to perform real-time clustering and analysis of applications’ log data. Being able to utilize deep learning to cluster log data in real time allows the Netflix observability team to gain operational insights on high-cardinality system logs, identify outliers, and improve the alerting-on-logs experience. Utilizing pre-trained deep learning models to convert any log line from natural language into a cluster ID that preserves similarity reduces the volume of alerts and storage cost of storing logs.
For example, imagine we want to send an alert to the service owner if we see the following log messages:
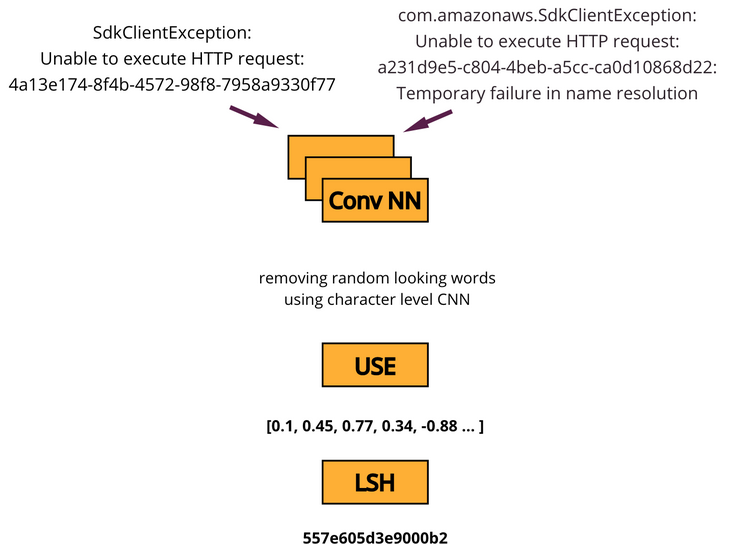
com.amazonaws.SdkClientException: Unable to execute HTTP request: a231d9e5-c804-4beb-a5cc-ca0d10868d22: Temporary failure in name resolution
and
SdkClientException: Unable to execute HTTP request: 4a13e174-8f4b-4572-98f8-7958a9330f77
The log lines are not exactly the same, but they convey the same meaning and ideally should be clustered together, especially if alerting is set up to trigger on the lines that look like those above. For example, the cluster ID for both messages will be 557e605d3e9000b2, which allows these two events to be grouped together, counted, and send out a single alert.
How do we end up with the same cluster ID? We run our log lines through character-level convolutional neural networks (CNNs) that help to remove random-looking words and then extract semantic dense vectors via the Universal Sentence Encoder (USE). Once we have the vector, we apply a custom version of locality-sensitive hashing (LSH) to come up with the cluster ID that preserves similarity. We use DJL to run pre-trained CNN and USE models, as well as the custom LSH implementation.
Using DJL and transfer learning lets the team process both log messages in about 7ms each, extract semantic meaning, and assign the same cluster ID for both log events without any pre-training or offline learning of cluster assignments. The above pipeline lets us harness the power of transfer learning and achieve somewhat universal log clustering ability.
The pre-trained Universal Sentence Encoder is one of the models that is being used in production to perform the clustering. The model takes sentences as input and transform it into high-dimensional vector space (text embedding). The user can then perform semantic similarity analysis or clustering on the result vector. Anomaly detection or proper actions such as alerting can be automatically triggered based on insights gained from the text embedding inference.
Challenge
Initially, the Netflix observability team built a deep learning-based log clustering system in Python for offline processing. However, offline processing results in alerting latency and, as a result, issues may not be resolved in a timely manner. Therefore, we decided to build an online system to achieve real-time processing of log ingestion coming from hundreds of microservices. The goal was to analyze logs and send out alerts in real time.
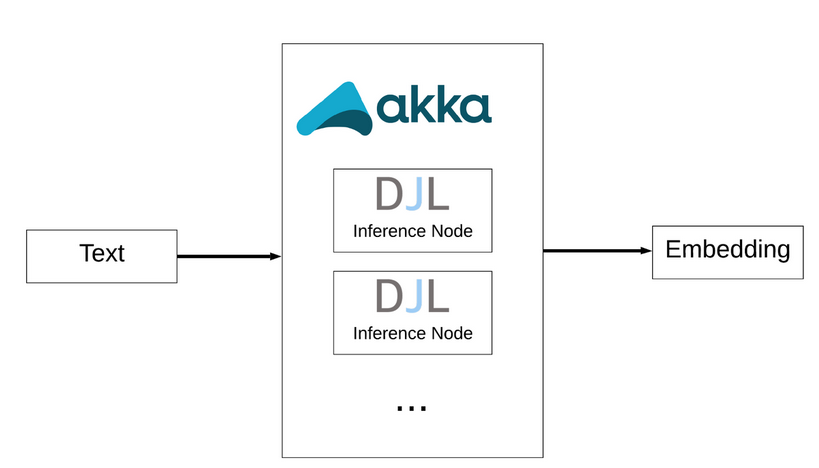
There are a few challenges in building an online system. First, the log streaming application used at Netflix is the Java/Scala-based Akka streams. Akka streams does reactive streaming data for Java/Scala applications in a concurrent and distributed manner. Deploying a Python model directly in a Java application will have communication overhead and won’t fulfill the latency requirement of a real-time system. Second, when Netflix was building the service, there was no high-level Java support for TensorFlow 2. Finally, running a Python/C++ model in a Java/Scala application often results in memory leaking problem. A typical Java Virtual Machine (JVM) garbage collector in the Java/Scala application does not have visibility into the C++ program’s memory usage; therefore, the JVM garbage collector cannot release memory inside the C++ program in a timely manner.
Solution
Netflix decided to use Deep Java Library (DJL) to solve the problems in Java compatibility and memory leakage. DJL is a deep learning framework written in Java, supporting both training and inference. DJL is built on top of modern deep learning engines (TensorFlow, PyTorch, MXNet, etc.) to easily train or deploy models from a variety of engines without any additional conversion. It contains a powerful ModelZoo design that enables the management of pre-trained models and loads them in a single line. The built-in ModelZoo currently supports more than 70 pre-trained and ready-to-use models from GluonCV, HuggingFace, TorchHub, and Keras.
DJL‘s native Java API can work naturally with Akka, Akka streams, and Akka-Http (for example, the data-streaming application used at Netflix) because DJL supports multithreading, which is used by Akka for concurrent processing. More importantly, DJL addresses the memory-leaking problem through its special memory collector, NDManager.
The NDManager is native to the C++ application and collects stale objects inside the C++ application (a low-level API that uses frameworks such as TensorFlow or Pytorch) in a timely manner. Netflix was able to create their online inference application by calling the DJL API to run inference directly in an Akka-Http application. In short, DJL was able to provide stability in the production environment after passing testing of 100 hours of continuous inference without crashing. Additionally, DJL is engine-agnostic and was able to automatically detect the framework in use and utilize the same C++ API. This also enables the Netflix team to introduce new frameworks (for example, PyTorch) in the future without needing to change deployment code.
Here is a sample inference pipeline design and some dummy deployment code to show you how to deploy a deep learning model directly via Akka-Http.
Route
Akka used Route to establish a RESTful request. As shown above, you can define endpoint /inferences to handle the POST request. In here, we call the method getInference to ask the Actor to perform the inference task.
Actor
Below is a simple Akka Actor setup. We simply create a function called inference where we will call the inference API. Through designing this module, Akka can help to scale for concurrent requests with multiple machines.
DJL inference
After defining the two basic Akka roles, we can start working on the core inference task. First, let’s try to load the model:
Loading a model in DJL is simple; you only need to define the model URL and corresponding Translator to do preprocessing and post-processing. After that, the model will load into memory and will be ready for use.
Next, we simply define a predict method, which will be managed by Akka for multithreading calls. Because the DJL predictor is not threadsafe, we use a predictorHolder, which is a thread-local object to handle the multithreading.
Application
Finally, let’s move into the major application. All we need to do is glue everything together here. We defined an Actor and Route to get them connected. And, then, we can start the HTTP server from startHttpServer.
The following code defines the basic IP and port for the server.
This example project is available on GitHub and can easily scale up to a cluster of machines to do distributed online inference.
In the specific example that we introduced earlier (where two log messages containing similar information were coming in at the same time), using DJL allowed the Netflix observability team to process both log messages in about two milliseconds, extract semantic meaning, and assign the same cluster ID for both log events. The team was able to achieve stable performance by optimizing the TensorFlow engine to operate only on several threads and by using NDManager for all memory management tasks, thereby leaving room for stream processing, data cleanup, and so on.
Conclusion
With DJL, the Netflix observability team was able to build an online inference system that is running real-time inference on Tensorflow 2.0 models directly in their data-streaming application. Our future plans with DJL include trying out its training API, scaling usage of transfer learning inference, and exploring its bindings for PyTorch and MXNet to harness the power and availability of transfer learning.
Follow the GitHub, demo repository, Slack channel, and Twitter for more documentation and examples of DJL.

Stanislav Kirdey
Stanislav works at Netflix where he focuses on large-scale, applied machine learning in the areas of NLP, search, and anomaly detection. Outside of machine learning and work, Stanislav is obsessed with RuPaul’s Drag Race, POSE, and Star Trek.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.