AWS Open Source Blog
How TalkingData uses AWS open source Deep Java Library with Apache Spark for machine learning inference at scale
This post is contributed by Xiaoyan Zhang, a Data Scientist from TalkingData.
TalkingData is a data intelligence service provider that offers data products and services to provide businesses insights on consumer behavior, preferences, and trends. One of TalkingData’s core services is leveraging machine learning and deep learning models to predict consumer behaviors (e.g., likelihood of a particular group to buy a house or a car) and use these insights for targeted advertising. For example, a car dealer will only want to show their ads to customers who the model predicts are most likely to buy a car in the next three months.
Initially, TalkingData was building an XGBoost model for these types of predictions, but their data science team wanted to explore whether deep learning models could have a significant performance improvement for their use case. After experimentation, their data scientists built a model on PyTorch, an open source deep learning framework, that achieved a 13% improvement on recall rate. (Recall rate is the percentage of times a model is able to give a prediction within a predefined confidence level.) In other words, their deep learning model managed to generate more predictions while maintaining a consistent level of accuracy.
Deploying a deep learning model in production was challenging at the scale at which TalkingData operates, and required the model to provide hundreds of millions of predictions per day. Previously, TalkingData had been using Apache Spark, an open source distributed processing engine, to address their large-scale data processing needs. Apache Spark distributes data processing and computing jobs over multiple instances, which results in faster processing; however, Apache Spark is a Java/Scala-based application that often results in memory leak issues (such as crashes) when running Python programs. This is because the Java garbage collector in Spark does not have visibility into the memory usage of the Python application, and thus does not complete memory cleaning in time.
The XGBoost model supported Java, and TalkingData was able to use the XGBoost Java API to deploy the model in Java and it worked well on Spark. However, PyTorch, the framework used by TalkingData’s deep learning model, did not have an out-of-box Java API. As a result, TalkingData could not directly run the PyTorch model on Apache Spark due to the memory leak issue. To circumvent the memory leak problem, TalkingData had to move data from Apache Spark (after data processing) to a separate GPU instance for running the PyTorch model inference job, which increased the end-to-end processing time and introduced additional maintenance overhead.
The article Implement Object Detection with PyTorch in Java in 5 minutes with DJL, an Engine-agnostic Deep Learning Library taught the TalkingData production team about DJL (Deep Java Library), an open source deep learning framework written in Java and developed by AWS.
In this post, we will walk through the model that TalkingData used and showcase their solution of using DJL to run inference for PyTorch models on Apache Spark. This approach provides an end-to-end solution to run everything on Apache Spark without involving additional services, and it reduced running time by 66% and reduced maintenance costs.
About the model
Trained on aggregated multi-field data collected by SDK embedded applications, TalkingData’s model is a binary classification model used to infer whether the active user is likely to buy a car. Different fields of data are aggregated and processed as arrays of categorical features, which are inevitably sparse. When TalkingData used traditional machine learning models, such as logistic regression and XGBoost, training becomes challenging for these simple models to learn from sparse features without overfitting. However, millions of training data points made it feasible to build more complicated and powerful models, so TalkingData upgraded their model to DNN (Deep Neural Network) models.

In compliance with laws and regulations, the TalkingData model takes user information, user application information, and advertising information as inputs. User information includes device name and device model, user application information covers SDK embedded app package names, and advertising information is user-engaged campaign information. These different fields of input are aggregated over time and preprocessed—including tokenization and normalization—as categorical features.
Inspired by Wide and Deep learning (refer to the Wide & Deep Learning for Recommender Systems [PDF]) and YouTube Deep Neural Networks (PDF), categorical features are first mapped to their indices according to a pre-generated mapping table and truncated as fixed length before being fed into the PyTorch DNN model. The model is trained with corresponding word embeddings for each field.
Embedding is a method to represent categorical variables with numeric vectors. It is a technique for reducing dimensionality of sparse categorical variables. For example, millions of different categories can be represented using hundreds of numbers in a vector, thus achieving dimensionality reduction for modeling. Different fields’ embeddings are simply averaged before concatenation into a fixed-length vector, which is fed into a feedforward neural network. During training, the max training epoch is set as 40, whereas the early stopping round is set as 15. Compared to the XGBoost-Spark model, the DNN model improves Area under the ROC Curve (AUC) by 6.5%, and recall at desired precision by up to 26%. The DNN model’s result is impressive considering TalkingData’s data volume is huge.
Scenario

Deployment became an obstacle to the DNN model because most of the processing logic was written in Scala. Deploying a PyTorch model directly on Scala often created memory leak issues—the JVM garbage collector did not have visibility into memory usage inside the C++ application (lower-level API that PyTorch calls). To avoid this issue, TalkingData’s machine learning engineering team had to use a separate GPU instance to do the offline inference.

This solution also created its own set problems:
- Performance issues: Pulling the data off and re-uploading took around 30 minutes.
- Single point failure: Users were unable to utilize the multi-instances Spark provides for computing. Computing (i.e, inferencing) ran on one single GPU instance separately, and there was no fallback mechanism if that GPU instance failed.
- Maintenance overhead: TalkingData needed to maintain code bases for both Scala and Python.
- Hard to scale: Because the dataset is large, a single instance solution was not sufficient.
The volume of data size was hundreds of gigabytes. It took more than six hours to finish an end-to-end inference job, which was twice the amount of time the TalkingData team was hoping it would take to complete the process. This design became the bottleneck for the whole pipeline.
Implementing DJL
To solve this issue, TalkingData rebuilt their inference pipeline using DJL, which offered a PyTorch Java package that can be directly deployed on Spark. As shown below, all work can be done inside the Spark instance:
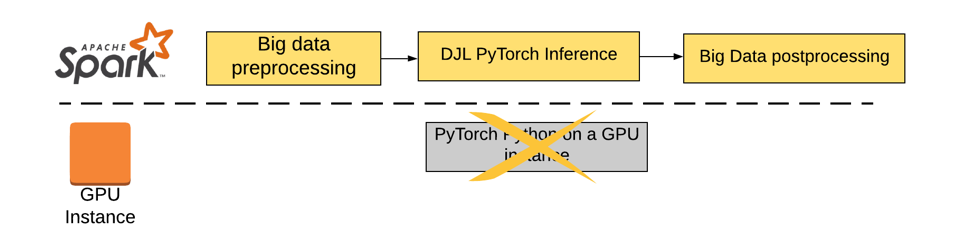
This design delivered the following advantages:
- Reduced failure rate: Spark helped manage instances to avoid single points of failure.
- Reduced cost: In TalkingData’s original workaround, inference was running on a separate GPU instance instead of utilizing the multi-instance compute power from Apache Spark. Now, TalkingData could leverage Apache Spark’s computational power to save money. In this case, they were able to avoid 20% cost from GPU instance costs each time they ran batch inference.
- Reduced maintenance: Scaling on Spark and maintaining a single language was relatively easy.
- Improved performance: DJL’s multi-thread inference boosted the performance on Spark.
After implementing DJL, TalkingData managed to run the complete inference job in less than two hours, which was three times faster than the previous solution. It also saved them time from maintaining both the separate GPU instance and Apache Spark instances.
DJL’s multithreading strategy
DJL’s configuration options allowed users make the most out of Apache Spark’s distributed processing capability. Along the lines of PyTorch’s advanced feature on inter-op parallelism and intra-op parallelism (for optimizing inference performance), DJL offered similar functionality via the configuration settings num_interop_threads and num_threads. The number could be adjusted along with the Apache Spark core executors configuration, such as --num-executors, as both of them were using the same underlying CPU pool. Thus, DJL still allowed users to fine-tune the computing resource allocation for different performance goals in the same manner as PyTorch.
Correctness reliability check
To ensure DJL’s PyTorch solution would also achieve the same result as PyTorch using Python, TalkingData conducted an experiment. They ran 440k test samples, which resulted in the following element-wise difference between Python and DJL’s Scala inference results:
| Item | Result | Explanation |
| Count | 4387830 | Total number of data |
| mean | 5.27E-08 | mean diff |
| std | 1.09E-05 | standard deviation |
| p25 | 0.00E+00 | Ascending order top 25% of data |
| p50 | 2.98E-08 | Ascending order top 50% of data |
| p75 | 5.96E-08 | Ascending order top 75% of data |
| p99 | 1.79E-07 | Ascending order top 99% of data |
| max | 7.22E-03 | Maximum difference on result |
This experiment proved DJL was highly reliable on the inference result by ensuring more than 99% of the data would fall into 10^-7 compared to the training results on PyTorch using Python, or a floating point difference of less than 0.0000001.
For more information about Spark inference, view the DJL Spark example on GitHub and review the blog post.
Conclusion
TalkingData is now deploying deep learning models on Apache Spark using DJL. They switched to using DJL for deployment for the following reasons:
- DJL eliminates the need to maintain additional infrastructure other than Apache Spark.
- DJL let TalkingData fully utilize the computing power from Apache Spark for inference.
- DJL is framework-agnostic, which gives TalkingData the ability to deploy any deep learning model (i.e, Tensorflow, PyTorch, MXNet, etc.) without any deployment code change, reducing time to market for TalkingData’s new products/services.
About DJL
Deep Java Library (DJL) is a Deep Learning Framework written in Java, supporting both training and inference. DJL is built on top of modern Deep Learning engines (TenserFlow, PyTorch, MXNet, etc.). Using DJL can help you train your model or deploy your favorite models from a variety of engines without any additional conversion. It contains a powerful ModelZoo design that allows you to manage trained models and load them in a single line. The built-in ModelZoo currently supports more than 70 pre-trained and ready to use models from GluonCV, Hugging Face, PyTorch Hub, and Keras.
Follow our GitHub, demo repository, Slack channel, and Twitter account for more documentation and examples of DJL.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.