AWS Open Source Blog
Querying AWS at scale across APIs, Regions, and accounts
This post was contributed by David Boeke, Bob Tordella, Jon Udell, and Nathan Wallace.
Steampipe is an open source tool for querying cloud APIs in a universal way and reasoning about the data in SQL. To enable you to select * from cloud, the tool embeds Postgres, and it maps cloud APIs to database tables using a bundled Foreign Data Wrapper extension that supports a growing list of API-specific plugins. The AWS plugin maps the suite of AWS APIs to nearly 250 SQL tables that you can query separately or in combination, to answer questions about compute, networking, and storage resources, check your security posture, explore billing, and more.
In this post, we focus on three strategies that work together to deliver the best possible speed and throughput: parallelism across sub-APIs, across Regions, and across Amazon Web Services (AWS) accounts.
Parallel use of sub-APIs
To answer a question about Amazon Simple Storage Service (Amazon S3) buckets, you may need to consult various Amazon S3 sub-APIs, such as GetBucketVersioning, GetBucketTagging, and GetBucketReplication. If your query is select * from aws_s3_bucket, then Steampipe makes all the sub-API calls and returns a rich set of columns. The calls happen in parallel, so this is a quick operation, and they’re intelligently cached so it’s also efficient.
If you don’t need all those columns and data, however, select only the ones you need. In that case, you won’t pay for gratuitous calls, and won’t impose an unnecessary burden on the monitoring and logging systems.
Parallel queries across Regions
When your account is configured for multiple Regions, Steampipe automatically queries across all of them. Again, parallelization makes this a quick operation.
The engine fans out concurrent connections to the configured Regions, aggregates the results, and then presents them as one result set. The slowest Regional response governs the speed of the entire multi-Region query. By default, results are cached for five minutes, so a subsequent query for the same columns happens instantly.
Parallel queries across AWS accounts
The following example shows how to configure multiple AWS accounts in a single instance of Steampipe:
All Steampipe configuration is expressed using a familiar language: Terraform’s HCL (Hashicorp Configuration Language). In the preceding example, we chose different profiles for the connection credentials. You can also configure Steampipe to use access_key/secret_key pairs instead of an AWS profile. After changing any .spc configuration, restart Steampipe (steampipe service restart).
Per-account namespaces
Each account configuration creates a separate namespace in the embedded Postgres database. This lets us query different accounts using standard schema.table_name syntax.
You could aggregate results across accounts with a SQL UNION.
Even better, you can set up a connection aggregator to do that for you.
Connection aggregators
Check out this multi-account setup:
The wildcard in [dmi*] matches dmi_prod and dmi_dev, so the all_dmi connection combines both. We can now run a single query to retrieve results for all accounts and Regions:
As you might have guessed, Steampipe also makes parallel use of aggregated connections. The FDW (Foreign Data Wrapper) layer uses its multi-threaded core to begin fetching results from all connections in parallel, and immediately streams back results. The gating factor is, again, the slowest connection in the group.
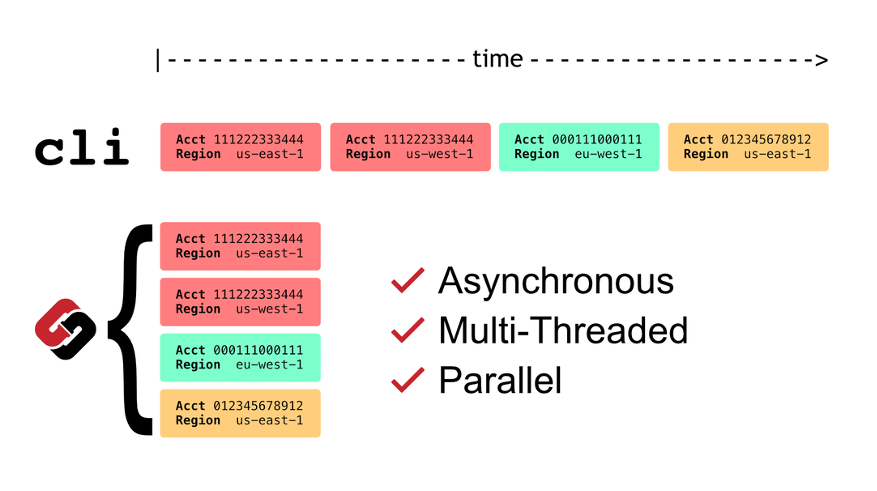
Caching is woven into the architecture here, too. Running an aggregate query preloads the cache for subsequent multi-connection queries and for each of the individual connections.
How to get involved
Try using Steampipe to explore your AWS environments and tell us how that goes. The AWS plugin covers a massive API surface area; we want to learn more about how and why people are probing it.
To get started with Steampipe on AWS, first install the engine, then the plugin using steampipe plugin install aws. Then set up one or more connections using your preferred type of credential.
Select a table of interest, such as aws_iam_role, launch steampipe query, paste examples from the documentation into the terminal, and explore the results.
Next, try varying the examples and writing new queries in order to answer your own questions. Let us know what you are able to learn about your AWS infrastructure.
Note that critical insights can sometimes emerge from queries that join tables in the AWS plugin with tables from another plugin. In the blog post “Using Shodan to test AWS Public IPs”, for example, we show how to check public IP addresses against the Shodan database of open ports and vulnerabilities.
Your exploration may lead to ideas for enhancing the existing suite of tables, or adding new ones. If you’re not a developer, let us know what you have in mind; our team continuously converts feedback into enhancements.
If you are a developer and you’d like to enhance a table or add a new one, check out our documentation and give it try. We’ve received contributions to the AWS plugin from several community members, and we are eager for more.
Conclusion
As operators of cloud infrastructure, we are all in the business of probing APIs in order to reason about that infrastructure. Doing that at scale for AWS requires the three levels of parallelism we’ve discussed here: across sub-API calls, across accounts, and across Regions.
Rapid acquisition of API-based data is only the start. We think that SQL is the best way to normalize data from diverse APIs, then reason across them. We’ve compiled a rich set of examples to spark your imagination. Now it’s your turn: Show us your own queries!
Resources
- Install Steampipe
- Install the AWS plugin
- Launch the Steamipe CLI
- Explore the AWS tables
- Tips for writing queries
- Show us your queries

David Boeke
David Boeke is the CTO of Turbot. David has 25+ years of experience in IT and is recognized as a transformational leader who has enabled some of the world’s largest enterprise organizations to make the transition to public cloud. Prior to joining Turbot, David was the Global Head of Enterprise Architecture and led the cloud transformation for a Fortune 50 life sciences company.

Bob Tordella
Bob Tordella is the CRO of Turbot. He is recognized as a cloud governance leader who has enabled the world’s largest enterprise organizations to secure and optimize their public cloud environments. Bob is currently improving the way teams operate in the public cloud to discover and auto-resolve incidents using Turbot. He is also an advocate for Steampipe, an open source project that simplifies querying your cloud with SQL.


Nathan Wallace
Nathan Wallace is the Founder and CEO of Turbot. He is recognized as a transformational leader who has enabled some of the world’s largest enterprise organizations to make the transition to public cloud. Prior to starting Turbot, Nathan tackled these challenges head on as the Global Director of Cloud and DevOps for a Fortune 50 multinational pharmaceutical company.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.