AWS Physical AI Blog
How Certis achieved autonomous robot security patrols with AWS
The authors would also like to thank Charlie Chang, Amit Kulkarni, Paul Amadeo, Alla Simoneau, Howie Tan for their contributions in making this initiative possible.
Introduction
Certis is a leading integrated operations service provider, with over 25,000 employees globally and one of the largest Auxiliary Police Forces in Singapore. As part of its broader autonomous security program, Certis is exploring how Physical AI and robotics can augment frontline operations and enhance patrol coverage, consistency, and response in complex security environments.
In this post, we show how Certis partnered with the AWS Generative AI Innovation Center (Innovation Center) to overcome the key technical challenges of vision-based autonomous navigation and build an end-to-end inspection system for quadruped (four-legged) robots. You’ll learn how the team used generative AI and a single monocular RGB camera to autonomously detect, approach, and inspect targets of interest with the system trained on Amazon SageMaker AI and deployed to edge devices on the robot for real-time decision-making.
“For Certis, this is not just a robotics milestone. Physical AI gives us a practical way to scale patrol coverage. We can deliver 30% faster incident response, improve coverage and consistency across security operations. This is an important step in our broader autonomous security program, and strengthens how we serve critical infrastructure customers across the region.”
— Raahul Kumar, Chief Executive, International and Robotics, Certis
Key challenges in vision-based autonomous navigation
Deploying vision-based autonomous navigation for real-world robotic systems presents both fundamental technical limitations and practical operational constraints.
Operational constraints in production deployment
Certis faced several operational challenges: its security operations at critical infrastructure sites remain heavily dependent on large numbers of trained officers to conduct routine patrols, inspections, and surveillance around the clock. Officers often cover limited ground and face safety risks at critical infrastructure. It also poses safety risks as officers face potential hazards such as chemical spills, unauthorized intruders, or suspicious unattended objects. Additionally, scaling security coverage to meet growing demand is constrained by the availability of trained personnel. Autonomous patrol systems directly address these constraints. They have demonstrated up to a 30% improvement in incident response time compared to traditional patrolling, while reducing exposure to on-site hazards.
Technical limitations of existing approaches
Existing goal-conditioned visual navigation models – systems that take a camera feed plus a picture of a target and predict where the robot should move next, have critical limitations that hinder their practical deployment in real-world security operations. One crucial concern lies in the fragility of static goal representations where prevailing systems rely on curated, static goal image repositories to define navigation targets, an assumption that proves impractical in dynamic real-world environments. Target appearances can vary significantly due to changes in viewpoint, lighting conditions, and approach angle, introducing considerable goal domain shift that undermines the reliability and generalization of goal-conditioned navigation. Another fundamental limitation is the absence of robust vision-only halting mechanisms. Without a depth sensor, it is hard for the robot to know when it has reached a safe stopping distance from the target. Vision-only approaches without a principled stopping criterion can suffer from “stop chatter,” where the robot repeatedly alternates between moving and stopping just short of the target. Together, these limitations highlight a critical gap between the current capabilities of off-the-shelf models and the robustness required for reliable autonomous inspection and surveillance in uncontrolled, real-world settings.
The vision: Fully autonomous RGB-only navigation
To address these compounding challenges, Certis envisioned a fully autonomous navigation system. The system needed to handle end-to-end mission execution using only the robot’s onboard monocular RGB camera, with minimal human intervention. The target capability required the robot to autonomously:
- Detect a target of interest in the visual field
- Navigate toward the target from any arbitrary starting angle
- Halt at a consistent and safe standoff distance
- Execute a structured 360-degree circular inspection orbit
Achieving this vision required a solution that simultaneously overcame the technical limitations of existing vision-based navigation methods while satisfying the operational requirements of real-world, fleet-scale security deployment.
The solution: Vision-action navigation and inspection framework
The Innovation Center at AWS worked with Certis to develop a solution that addresses the fundamental gaps between laboratory demonstrations and real-world field deployment.
The following diagram shows the overall training and deployment pipeline.
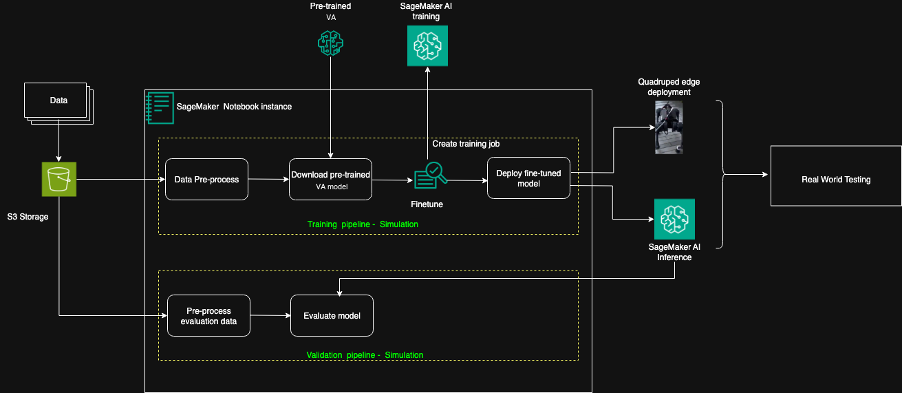
Figure 1: Diagram showing the overall training and deployment pipeline on AWS
The solution is built on Amazon SageMaker AI for the full model lifecycle. Training data (RGB images and robot odometry collected from real quadruped trajectories) is stored in Amazon Simple Storage Service (S3) and pre-processed in an Amazon SageMaker Notebook instance. A pretrained vision-action navigation backbone is downloaded into the Amazon SageMaker AI environment, fine-tuned on Certis-specific trajectory data using Amazon SageMaker AI Training Jobs, and then evaluated through an Amazon SageMaker AI-based validation pipeline. Once validated, the fine-tuned model is packaged and deployed to the edge device on the quadruped robot for real-world testing, while Amazon SageMaker AI Inference is used for offline evaluation and regression testing of new model versions. This cloud-to-edge workflow allows Certis to iterate on models quickly in the cloud while running low-latency inference directly on the robot. By centralizing training and evaluation on Amazon SageMaker AI, Certis can more expediently push validated models to the robot fleet, without rebuilding infrastructure for each deployment.
The complete solution integrates several technical contributions into a unified deployable system.
Component 1: Efficient navigation policy
The navigation policy uses an efficient single-step generative model (Rectified Flow) instead of traditional multi-step diffusion models. In plain terms, diffusion models usually generate an output (here, a short sequence of waypoints for the robot to follow) by starting from random noise and cleaning it up over many iterations. Rectified Flow learns a direct path from noise to the final answer, so the model can produce waypoints in a single step. This reduces computational cost while maintaining accuracy, important for running on a resource-constrained robot.
Component 2: Multi-phase inspection pipeline
This component runs on top of the navigation policy and orchestrates the full mission: detecting the target, approaching it, stopping at the right distance, and orbiting it. It is organized into three phases that together let the robot autonomously detect, approach, halt, and inspect a target using only its onboard RGB camera.
Phase 1: Real-time goal refinement. By “real-time,” we mean running continuously on the robot itself as it walks, not in the cloud and not requiring an internet connection. This phase removes the need for a library of pre-captured goal images by building the goal image dynamically from the robot’s own live camera feed. An object detector draws a bounding box (a rectangle around the detected object in the image) and assigns a confidence score. The system continuously re-crops the goal image from inside that bounding box and updates its cached goal only when the new crop is more confident, larger (closer), and better-centered than the previous one. The result: as the robot gets closer, its “mental picture” of the target becomes sharper and more accurate.
Phase 2: Vision-only bounding box ratio halting. Without depth sensors (a sensor that would directly measure distance), the robot decides when to halt by tracking how much of the camera image the detected target fills. As the robot walks closer, the bounding box around the target grows; when it occupies roughly 20% of the frame, the robot is at the right standoff distance (approximately 1–1.2 meters for a typical backpack). To avoid the robot stopping prematurely on a single noisy frame, this ratio is smoothed over time using an Exponential Moving Average (a standard technique for filtering out short-term noise in a signal) and must stay in the target range for several consecutive frames before the robot halts. This eliminates the “stop chatter” problem described earlier.
Phase 3: Target-lock visual serving. During both approach and orbital inspection the robot needs to keep the target centered in its field of view, even as the legged gait causes the camera to pitch and roll. A lightweight vision controller watches how far off-center the target’s bounding box is in the image and issues small corrective turns to steer the robot back toward the target. A “deadband” (a small no-correction zone around the center) prevents the robot from constantly micro-correcting in response to detection jitter.
Deployment: Production-ready on the edge
The navigation model is deployed directly on the robot, on an NVIDIA Jetson Orin with 64 GB of memory, which enables real-time decision-making without needing a cloud connection. The system is organized as two cooperating modules running on the robot:
- Waypoint prediction module: This is the “brain.” It reads camera frames and detected bounding boxes, maintains a short history of recent observations, and uses the GPU to predict the robot’s next waypoints. Once the stopping criterion triggers, it switches from the ‘approach’ model to the ‘circular inspection’ model for the 360° orbit.
- Motion controller module: This can be likened to the “hands” of the robot. It translates the predicted waypoints into smooth velocity commands for the robot’s legs. During approach, it drives the robot forward smoothly with built-in acceleration limits so the motion never becomes jerky. During circular inspection, it coordinates a sideways and rotational motion to trace a smooth circle around the target. The underlying control technique is Proportional–Derivative (or PD) Controller, a well-established control method that produces smooth, stable motion by reacting both to how far off the robot is from its target waypoint and to how quickly that error is changing.
Both modules continuously receive feedback from the robot’s onboard odometry, the robot’s internal estimate of its own position and heading, computed by fusing leg-joint encoder readings with its built-in IMU (inertial measurement unit). This lets the system track how far it has moved and in what direction, independently of the camera.
Together, this tightly integrated edge architecture delivers low-latency autonomous navigation and inspection suitable for real-world security surveillance.
Results
The result: a quadruped robot that autonomously detects, approaches, halts at a safe distance, and inspects a target using only a single RGB camera.

The following metrics were selected from 15 test trials, and includes some of the most extreme scenarios, maximum distance combined with maximum deviation angle. Moreover, the robot starts from the far left and the far right, both with the maximum distance and largest deviation angle from the target point, as well as starting from directly in front of the target point at the maximum distance. More specifically, Figure 2 shows where the robot starts from when moving toward the target object.
The target is placed at the top center. The robot can start from five different positions:
- O — Directly in front of the target.
- A1 — On the right side.
- B1 — On the left side.
- A2 — At an upper-right angled position.
- B2 — At an upper-left angled position.
The target is 5 meters away from the center starting point O. The left and right positions are also 5 meters away from the center. The two angled positions are placed symmetrically on both sides, with a 65° viewing angle toward the target.
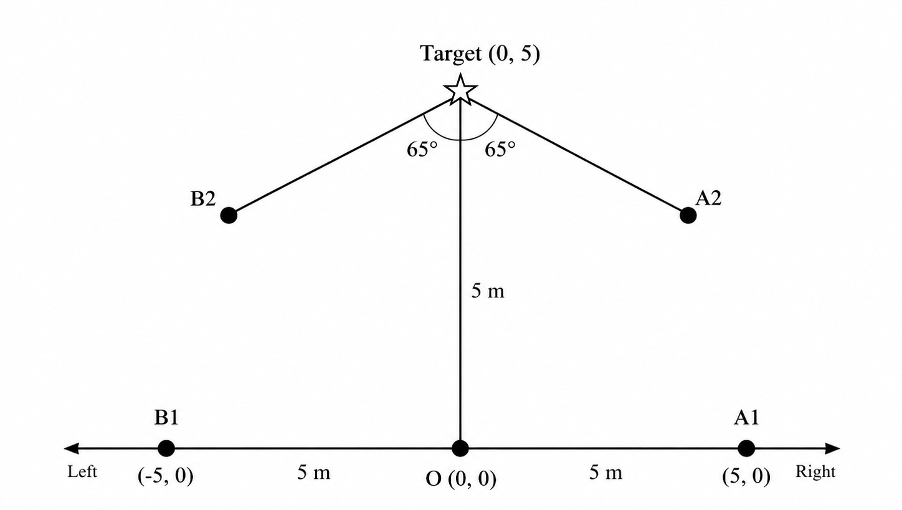
Figure 2: Diagram showing where the robot starts from when moving toward the target object
| Metric | Result |
|---|---|
| Navigation accuracy (from reference point to target bag position) | 100% |
| End-to-end mission success rate (identify, navigate to bag, and complete a circle around bag) | 100% |
| Average completion time | 102.3 s |
| The percentage of time the camera fully captures the object during the robot’s 360° orbit around it. | 91.3% |
Based on 15 test trials conducted jointly by Certis and the Innovation Center under controlled daytime conditions with unobstructed line of sight.w
The system achieved 100% navigation accuracy and mission success rate, which is under clear daytime conditions with an unobstructed line of sight between the robot and the target, and with the farthest successful detection at approximately 7 meters. Moreover, the system completed missions in an average of 102.3 seconds, and inspection coverage reached 91.3%.
What this means for autonomous security operations
This project demonstrates that generative AI techniques can extend beyond text and images to power autonomous physical systems in specific operational contexts. By combining efficient flow-based generative models, the Innovation Center and Certis showed that quadruped robots can perform complex, multi-stage security missions with reliability that meets operational requirements.
For Certis, this means the ability to scale autonomous security patrols without proportional increases in trained operators. This enables broader coverage, more consistent inspection quality, with the potential to extend to both day and night conditions.
For the broader robotics community, this work provides a blueprint for moving vision-based navigation from benchmark performance to field deployment, with architectural insights that generalize across different robotic systems and applications.
What’s next
Several directions are planned to broaden the system’s operating envelope beyond the current deployment scope. Future work includes handling cluttered and multi-target environments where the robot must reason about which object to approach first, as well as supporting broader object categories through open-vocabulary detection so new target types can be recognized without retraining. The team also plans to implement adaptive stopping distances that adjust automatically to different target sizes, extend operation to low-light and night-time conditions, and explore additional applications beyond security patrol, including search-and-rescue and industrial inspection.
Get started
If you’re exploring how generative AI can drive autonomous systems in your organization, whether in security, industrial inspection, or beyond – the Innovation Center can help. The program has supported customers including Formula 1, Nasdaq, Ryanair, and S&P Global, with more than 73% of recent projects reaching production. Connect with your Account Manager to start your journey, or explore Amazon SageMaker AI to begin building today.