AWS Startups Blog
Large Scale Disaster Recovery Using AWS regions
 Guest post by Senthilkumar Ramaswamy, Lead Architect at Sprinklr and Rakesh Pillai, DevOps Lead Engineer at Sprinklr
Guest post by Senthilkumar Ramaswamy, Lead Architect at Sprinklr and Rakesh Pillai, DevOps Lead Engineer at Sprinklr
At Sprinklr, we help the largest brands in the world with marketing, advertising, research, care, and commerce via our unified customer experience management platform. Integrated with Facebook, Twitter, LinkedIn, and 22 other social channels globally, our platform uses thousands of servers, sifts through petabytes of data, and processes billions of transactions every single day. Twitter alone requires that we process a few hundred million tweets a day.
Given the tremendous amount of data that we process daily, disaster recovery (DR) is of utmost importance to us. We aspire to ensure business continuity in the face of natural or man-made disaster.
Most organizations try to implement High Availability (HA) instead of DR to guard them against any downtime of services. In case of HA, we ensure there exists a fallback mechanism for our services. The service that runs in HA is handled by hosts running in different availability zones but in the same geographical region. This approach, however, does not guarantee that our business will be up and running in case the entire region goes down. DR takes things to a completely new level, wherein you need to be able to recover from a different region that’s separated by over 250 miles. Our DR implementation is an Active/Passive model, meaning that we always have minimum critical services running in different regions, but a major part of the infrastructure is launched and restored when required.
The Challenge
We don’t want to risk going out of business in case of a disaster. As part of our commitment to our customers, we are required to have a robust disaster recovery process. This is critical for any business. For example, during Hurricane Sandy, only a few companies with data centers in the U.S.’s Northeast region were forced offline because of flooding. For our DR, we have a Recovery Point Objective (RPO) of 24 hours. This means that for recovery, our data can’t be older than 24 hours. Our Recovery Time Objective (RTO)—meaning the time it takes to complete the restoration from the time the DR is declared—varies from 6 hours to 24 hours based on the customer SLA. During our test, we targeted an RTO of 4 hours.
Planning your DR
Know the scale
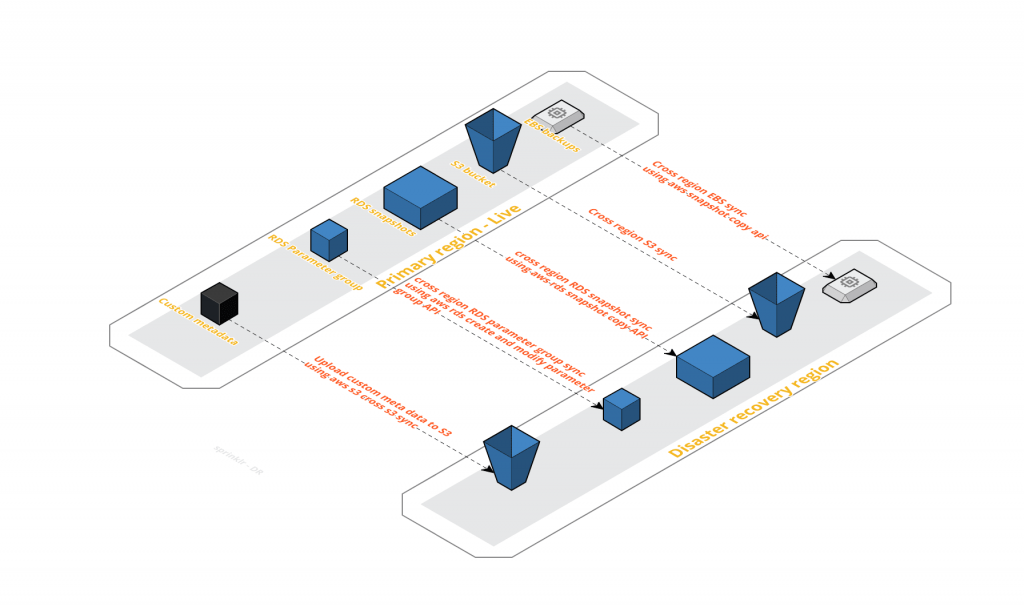
To understand what we were attempting, it’s important to take into account our current scale of operation, which involves the type of services and their count. We have an extensive list of data/non-data services like MongoDB, Elasticsearch, SOLR, Mesos, RDS, and more. These contribute to thousands of servers—close to 100 ELB, around 4000 route53 entries, over a petabyte of primary data and 50+ RDS instances. All of these services have to be launched in DR regions at the time of restore.
To achieve our purpose, we have written custom scripts which heavily rely on AWS API calls that we make to launch instances, attach snapshots, create elbs, and create route entries.
As depicted in above picture, all relevant backups get copied onto the DR region for restore.
At a high level, we have three types of backup to be copied.
1. EBS snapshots: We build our custom logic to intelligently keep track of all available backups and its progress and completion. We try not to cross the AWS limits and yet achieve complete snapshot copy.
2. S3 snapshots: We rely on the cross s3 sync and this works like a charm. We are able to copy the data from our primary to the DR region within a matter of few minutes.
3. RDS snapshots: We use the AWS RDS CopyDBSnapshot API to copy the RDS snapshots
Pilot Light Setup for DR
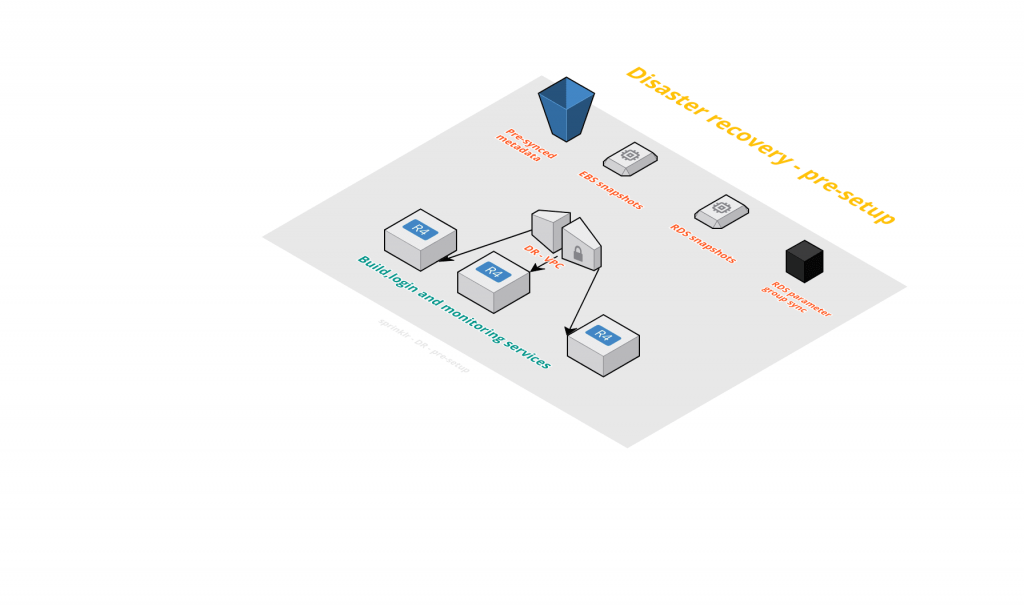 For us to get going at the word go, there are certain services that need to be running in order for us to provide us a gateway to attempt DR. These include setting up the VPC, subnets, and Route53 entries. We have built our custom tooling to help us do that. We create the VPC, which is of the similar CIDR configuration and subnet masking. For the Route entries, we make sure that any new subnets that get created get auto-created in the DR region as well. For this, we make use of AWS API calls to identify the subnet info in the primary region and create respective ones in the west region.
For us to get going at the word go, there are certain services that need to be running in order for us to provide us a gateway to attempt DR. These include setting up the VPC, subnets, and Route53 entries. We have built our custom tooling to help us do that. We create the VPC, which is of the similar CIDR configuration and subnet masking. For the Route entries, we make sure that any new subnets that get created get auto-created in the DR region as well. For this, we make use of AWS API calls to identify the subnet info in the primary region and create respective ones in the west region.
We identify required services without which we cannot gain entry to start our restore. This could be the authentication servers if you have any ( ldap/IPA ), the build servers, or the monitoring servers. These services should always be running, which means that once launched and set up, we always keep them running the DR region so that at any unforeseen circumstances, we are always able to get an entry into our DR region.
Also, Dependent AWS services should be made available. For example, we ensure that S3 buckets are available in the DR region and are in sync always with the primary region. This step is important because a lot of our configs, property files, and binaries sit in S3. It is important to make these available in the DR region for our application to be made up and running. For this, we use the AWS cross s3 feature, which does a remarkable job for us by fast and almost instantaneous sync of objects.
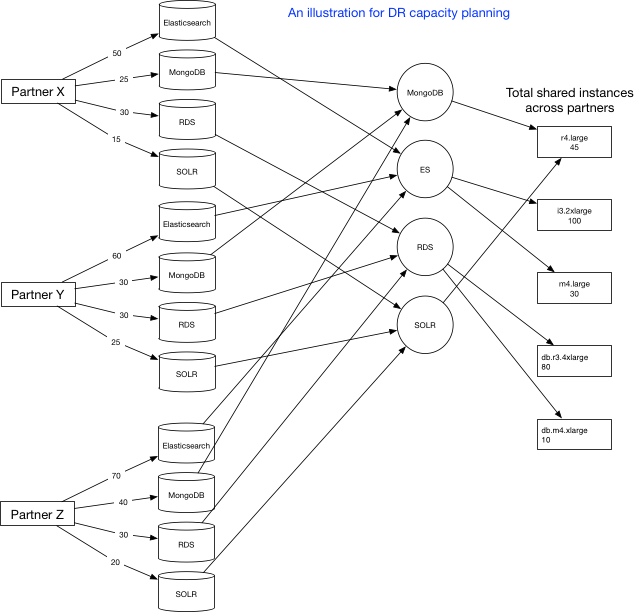
Capacity Planning
With the scale taken into account, we now must try to find our capacity requirement for DR.
The first step, from an application perspective, is to make sure the required configs are available in the DR region. These could be DB specific or any custom setup-related parameters—basically, anything that is required for your application to be up. As depicted in the above figure, for each of our partners that we restore and from the properties stored for them in our DB, we identify the capacity requirements for various services. For example, Partner Z needs 70 ES clusters, 40 MongoDBs, 30 RDS, and 20 SOLRs. Next, at a later step, we take a union of all services and find out the unique ones. That is because we share our clusters DBs across partners so some of the clusters found in the initial capacity requirements may actually be shared among other partners as well. So that leads us to a final capacity requirement, which is that we break down into instance types. As depicted in the above figure, for each service like Elasticsearch, we have different types of instance types. Finally, we arrive at a total capacity requirement for the instance types.
Once step one is clear, we figure out the number of ELBs and route entries to be created. We keep a metadata, which is arrived at by using the AWS APIs for the ELB and route entries info always ready in the west. This way we get a correct count of the capacity requirements and estimate the infrastructure. This includes capacity planning for EC2, ELB, and Route entries.
All of the above steps are important and go hand in hand to ensure a smooth recovery and preferably should be automated. We have all of this automated by writing custom scripts in Perl that makes use of the AWS API calls.
When You’re Hit By A Disaster
Try to prioritize
Out of the different services that exist, we should prioritize our launch based on services that are most critical and start launching EC2 instances for them. Ideally, divide these into three sets. It is an important decision, as we want to ensure that the critical services are launched with ease. The main blockers we are trying to avoid are capacity or limit issues from AWS. Division of services means we hit a lower number of API calls and are able to make use of all the available instance types that AWS may have at that point in time for the tier 1 services. The second and third sets will be attempted next. The advantage of this approach is, first you do not overuse the AWS API calls and crash your restore. For this, we have developed a caching logic where we cache the AWS API calls output that we know we will need again. With this, we are able to cut down the number of API calls by 50%. Second, make sure the major part of available capacity gets allocated to the most critical services.
Plan B for capacity
At the time of disaster, we may not have the liberty to launch instances as we’d like and it’s necessary to build runtime intelligence.
By the time we reach our second and third set of priority services, we may have exhausted available capacity. We ensure that the limits are already increased. However, at the time of DR, not all of the instance types that we require may be guaranteed to be available with AWS and this can potentially jeopardize the entire DR operation.
To mitigate this we have our Plan B. The Plan B is to be prepared and build intelligence via automation to launch other instance types in the same family. To build this intelligence, we rely on AWS CloudWatch. We use information from AWS CloudWatch metrics to analyze our instance usage in our primary region and this allows us to figure out what possible instance families and types can be attempted in case the current one isn’t available. That means, for a specific service, which uses, say, r3.xlarge instance type, with the help of CloudWatch metrics, we have all the information available to decide the next instance type that this service can possibly use and attempt to launch.
Once we determine a new instance type, there is an additional task of calculating the number of instances. That is because if we go a level below, say, r3.2xlarge to r3.xlarge, then we may need to double the capacity and if we go up, then we may need to reduce the capacity by half. So this calculation has to be made at runtime.
Restore and Launch Other AWS services
The launch of other non-EC2 services like ELB, Route, and more are triggered now; we rely on the metadata that’s kept in sync on S3 from the primary region to bring up these services. The metadata information contains the required information for us to launch the services. In the case of ELB, it’s the type of ELB (internal or external) the certificate info, attached subnets, and attached instances. For a route entry, it’s the type of DNS record and its values.
We launch these after the EC2 are launched because they may require the EC2 instance information for the configuration. For example, a route entry may need the public IP address information of an EC2 instance.
Restore the Application
We are halfway through after the successful execution of the above steps. That’s because we have been able to get the resources from AWS and configure them as per our application requirements. The major part of our capacity requirement from AWS is handled. The remaining part is mostly related to the application and logic. This involves making sure that your codebase is available and you have the builds ready to deploy when required in the DR region.
Issues Faced and Remediation
Having implemented the above model, we still ran into several issues surrounding the API calls. The scale of restore led us to hit a huge number of API calls, which gets throttled by AWS. We developed an intelligent caching system, which allows us to cache a lot of the information from the APIs. We reduced the AWS API calls to one-fourth of the initial number.
Hopefully, this blog post gives you some ideas about the approach for planning your DR process. DR planning and periodic testing is critical for ensuring that a company doesn’t go out of business in case of natural or manmade disaster. To learn more, visit the Sprinklr website.