AWS Startups Blog
Leveraging AI and Amazon SageMaker to Streamline Business Accounting Practices
Guest post by CANDIS.io
Every year, millions of companies in Europe and abroad have to file one or more kinds of tax returns. While authorities have managed to provide digital inboxes for tax data as a whole, preparing everyday accounting documents such as bills, invoices, bank statements and expense reports is still a lot of manual labor—both for companies and tax advisories. Managers, bookkeepers and founders all spend enormous time on obligatory accounting issues—just the way their grandparents did. And while global mobility faces the last day of the combustion engine, accounting still works just like in the days when streets echoed from the clattering of horse shoes.
At CANDIS, we strive to remove the friction from everyday processes that finance managers face at small and medium-sized enterprises when it comes to preparing accounting and financial data for their tax advisors.
In order to achieve this, we enable customers to easily integrate their data directly into CANDIS. Our customers can forward invoices via mail or simply upload them as scanned documents. On top of that, we automatically fetch invoices from online portals and email accounts. Via our banking API, we automatically pull transaction data from our client’s transaction accounts. As a result, customers can manage their accounting data and documents from a common central for all their finance documents—CANDIS recognizes, assorts, and matches data and transactions. It provides updates for missing documents and enables customers to upload structured and usable data to their tax advisor.

One of the key topics in accounting automation is to provide reliable and consistent document extraction, i.e. to capture structured data from unstructured documents such as scans, images or PDFs. Specifically, we are confronted with the challenge to obtain more than 50 individual data points from every individual document. These data points range from gross amount, tax portion and cash discounts to textual features like the sender’s name, address, email and telephone number.
While in literature and practice there are many approaches to this problem, we were eager to try out state-of-the-art machine learning methods, and specifically deep learning. Since CANDIS manages a service center of trained professionals that extract data from uploaded documents and annotate them with relevant financial metadata, our data scientists had access to a growing dataset they can experiment with. After confirming that initial prototypes of the extraction modules exhibited satisfactory performance, the team faced the challenge of deploying these to production and making them available to the user base.
Initial proposals to deploy models on Lambda (Lambda restricts your build artifact including all dependencies to not surpass 50mb) and Elastic Beanstalk (too much DevOps overhead) proved to not be the most natural environments to effectively deploy machine learning models. Luckily enough, around that time AWS released Amazon SageMaker in Frankfurt (EU region). SageMaker allowed our data science team to independently push machine learning models from prototypes to load-safe production endpoints in a matter of days.
One of the key benefits of SageMaker is that it supports multiple popular deep learning frameworks like Mxnet, Keras, Tensorflow and Scikit-learn. It hence considerably reduced effort to migrate our existing local experiments to SageMaker. Model trainings, deployments and hosting is another key strength of SageMaker, where Docker containers of trained models are there on EC2 while their key data reference source on S3. Training and deployment can be done using the boto3 SDK, a high-level SageMaker SDK or even the console, making it easier for our data science team to deploy large scale models quickly without the overhead of DevOps.
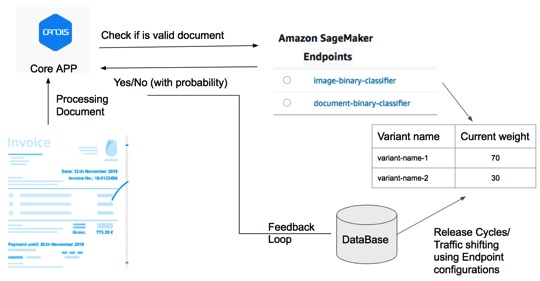
Typical workflow of SageMaker in Candis is illustrated in the picture above. Most of the models that were in proof of concept stage came into testing/production build using the customized docker containers. SageMaker starts Docker container on an instance to have a working environment suitable for your needs. “bring_you_own” directories from SageMaker really helped us speed the deployment process. We just needed to define our own input, output and validation schemas in the inference after the training.
Time to deployment in testing/staging to production in terms of release cycles is a sophisticated challenge in machine learning based projects. We tackled it creating separate endpoints for different applications and interacted with Core App as needed. Feedback loop for learnings was stored in database which was later used to retrain new model. Release cycle for different versions or variants of endpoint and shifting traffic for A/B testing and traditional rollout strategy is fully managed by updating the endpoint configurations, totally at the server end.
Using SageMaker turned out as an ideal setup for our infrastructure. It enabled us to build a document recognition engine that extracts a growing number of fields with accuracies above 98%, and to process a growing share of documents in real time.
We know accounting can be a tedious task for SMEs and larger companies. That’s why we at CANDIS focus our attention on making the accounting experience for finance managers as convenient and result-oriented as possible. For more information about ways to streamline your own processes, please visit our website and blog at https://candis.io/.