AWS News Blog
AWS Snowball Edge – More Storage, Local Endpoints, Lambda Functions
A I was preparing to write this blog post I went back and read the post I wrote when we launched AWS Snowball last year (AWS Import/Export Snowball – Transfer 1 Petabyte Per Week Using Amazon-Owned Storage Appliances) and then cataloged all of the updates that we have made since then. To recap, Snowball started out as a 50 TB data transfer appliance, designed with physical integrity and data security at top of mind. In a little over a year we have made many incremental improvements including increased capacity (80 TB), a job management API, HIPAA-eligibility, HDFS import, an S3 adapter, and availability in additional AWS Regions.
While all of these improvements were important they did not change the basic character of the appliance. Over the past year or so, with many AWS customers putting the original Snowball to work in many different types of physical environments and on a very wide variety of migration, big data, genomics, and data collection workloads, we have seen that there’s room to make this appliance even more functional.
Many customers are generating large amounts of data (often hundreds of terabytes) in situations where network connectivity is limited or non-existent and the physical environment is extreme. Customers want to collect data that they generate in farms, factories, hospitals, aircraft, and oil wells. From shop floor metrics to video surveillance, to information collected by IoT devices, customers are interested in a model that goes beyond straightforward store-and-forward data to collection, and would like to be able to do some local processing as the data arrives. They want to filter, clean, analyze, organize, track, summarize, and monitor the data as it arrives. They want to scan incoming data for patterns or problems, and raise alerts quickly if something interesting is detected.
New Snowball Edge
 Today we are adding Snowball Edge to the lineup. This appliance expands the scope of the Snowball, adding more connectivity, more storage, horizontal scalability via clustering, new storage endpoints that can be accessed from existing S3 and NFS clients, and Lambda-powered local processing.
Today we are adding Snowball Edge to the lineup. This appliance expands the scope of the Snowball, adding more connectivity, more storage, horizontal scalability via clustering, new storage endpoints that can be accessed from existing S3 and NFS clients, and Lambda-powered local processing.
Physically, Snowball Edge is designed to be at home in rough-and-tumble industrial, aerospace, agricultural, and military environments. The new form factor is also suitable for rack mounting in situations where you are taking advantage of the new clustering feature.
Let’s take a quick look at all of the new features!
More Connectivity
This appliance is well-connected, and gives you plenty of high-speed options.
On the network side you can use 10GBase-T, 10 or 25 Gb SFP28, or 40 Gb QSFP+. Your IoT devices can upload data using 3G cellular or Wi-Fi. If that’s not enough, there’s also a PCIe expansion port.
You have access to enough connectivity to copy data to Snowball Edge at up to 14 Gb per second; you can copy 100 TB in 19 hours or so. Beginning-to-end (initiate data transfer to data available in S3) the entire process takes a week, including shipping and handling along the way.
More Storage
Snowball Edge includes 100 TB of storage.
Horizontal Scaling via Clustering
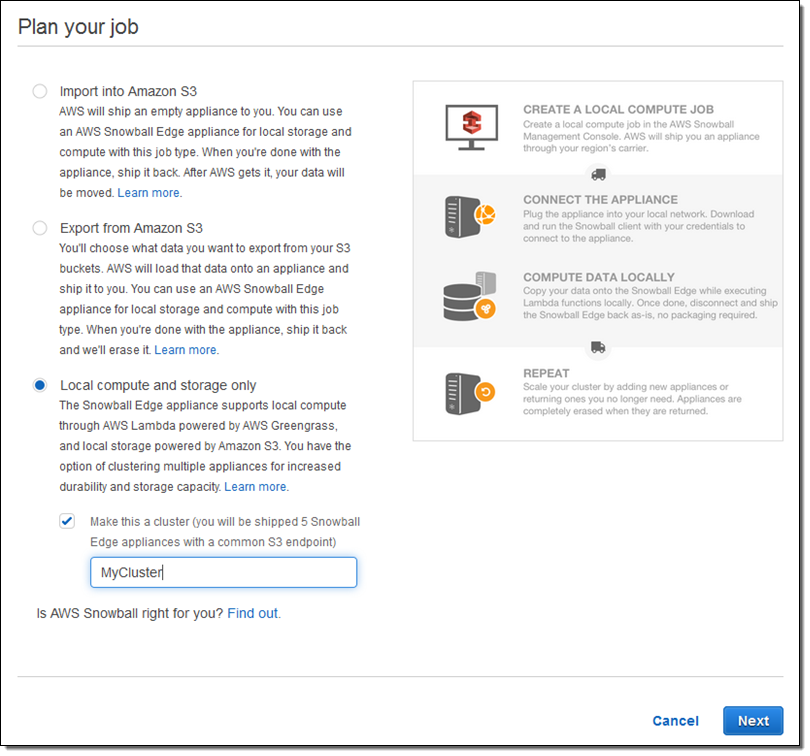
You can easily configure 2 or more Snowball Edge appliances into a cluster to add capacity and to increase durability, while keeping all of the storage accessible through a single endpoint. For example, clustering 6 appliances will create a highly available cluster with 400 TB of storage and 99.999% durability. This allows you to remove 2 of the appliances and still keep your data protected.
You can grow clusters up to petabyte scale, and you can shrink them by simply removing and returning appliances. The clusters are self-managing and you don’t need to worry about software updates or other tedium.
Order a cluster by simply checking Local compute and storage only and Make this a cluster when you set up your job:
New Storage Endpoints (S3 and NFS)
If you have existing backup, archiving, or data transfer tools that “speak” S3 or NFS, you can now use them to store and access data stored on Snowball Edge. If you create a cluster of 2 or more appliances, the same endpoint applies to all of them; this allows you to think of your cluster as local, network-attached storage.
Snowball Edge supports a powerful subset of the S3 API, including LIST, GET, PUT, DELETE, HEAD, and Multipart Upload. It also supports NFS v3 and NFS 4.1.
When you use Snowball Edge as a file storage gateway and access it via NFS, file and directory metadata (permissions, ownership, and timestamps) is mapped to S3 metadata, and preserved when the data is ingested to S3. You can use this feature to migrate data, bootstrap your usage of AWS Storage Gateway, or to store on-premises files for sharing between on-premises apps.
Lambda-Powered Local Processing
You can now write AWS Lambda functions in Python and use them to process data as it is uploaded to an S3 bucket associated with a Snowball Edge.
The functions can (as I hinted at earlier) filter, clean, analyze, organize, track, summarize the data as it arrives. Snowball Edge gives you the ability to add intelligence and sophistication to your data collection and data processing systems.
We are starting out with support for the S3 PUT operation, and you can use one function per bucket. The functions must be written in Python, and are run in a Lambda environment that is configured for 128 MB of memory.
You configure your functions when you order your Snowball Edge:
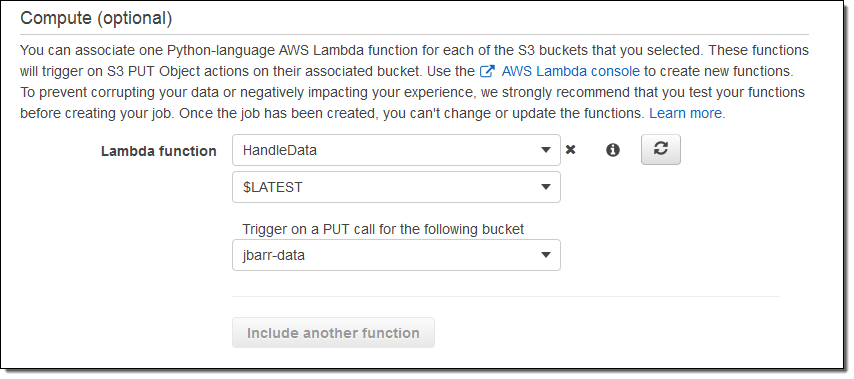
We do recommend that you test your functions in the cloud before placing your order.
Pricing and Availability
Snowball Edge is designed to be deployed in plug-and-play fashion. Your colleagues in the field don’t have to configure or administer it. The on-board LCD panel displays status information and plays setup videos. The on-board code is self-updating; there’s no routine software maintenance. You can check the status and make late-breaking configuration changes to deployed appliances through the AWS Management Console (API and CLI access is also available).
Each Snowball Edge job costs $300 plus shipping. You can keep each appliance for up to 10 days; after that you’ll be charged $30 per appliance per day. You can run Lambda functions locally at no charge.
You can learn more by attending our webinar December 15th. Register here.
— Jeff;